 夜雨聆风
夜雨聆风写在前面
前阵子有个人想让我把电子书搞成朗读版,恰好又有人有需求说不善言辞,想让我帮他做一份声音克隆,克隆他的声音说一大段话。这个需求在我看来简单的过于简单了,一直没写,今天抽空写一下,谁叫平台给我这几天推流呢,天予不取,反受其咎。哈哈哈。
我觉得这个功能已经被不法分子利用了,所以大家可以看看声音是如何被偷取的,陌生电话要么不接,接了千万不要先说话,对面可能就在录音,够3秒就挂电话了。你的声音就被偷走了。
ai是个双刃剑,从声音到人脸视频,都可以克隆合成,降低了门槛,本文除了技术记录,更想通过这篇文章让大家有一些防范意识。
音频效果,我就截个图,不放音频文件了。 遮天电子书的音频: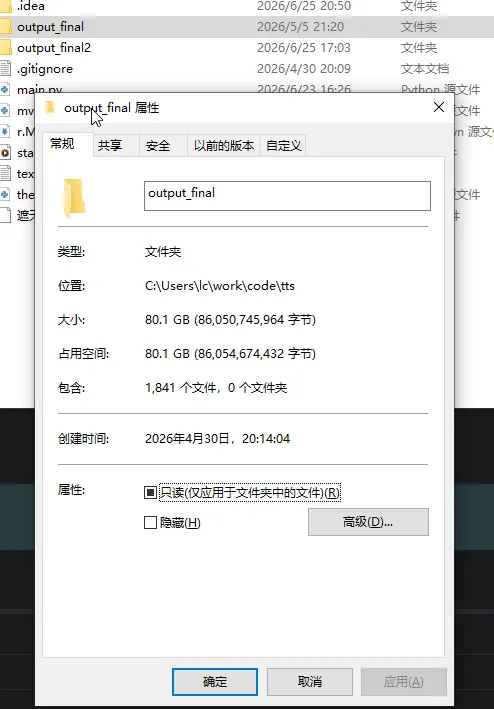
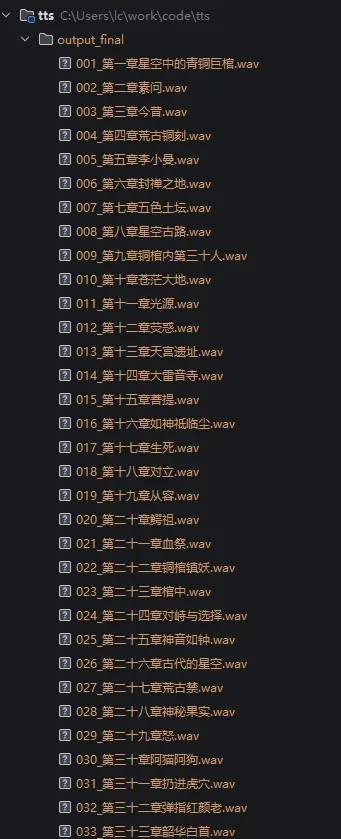
 文件太多了,截个局部,这个音频读起来不是死板生硬的那种,很有感情的声音,完全可以搭配
文件太多了,截个局部,这个音频读起来不是死板生硬的那种,很有感情的声音,完全可以搭配文生音色来自定义开发做成剧场模式。
一、前置 Microsoft 环境
项目必须安装 Microsoft Visual Studio C++ Build Tools[2]用conda install安装的不行
点击 Visual Studio C++ Build Tools[3] 这个链接,打开的页面是这样的 
这会下载来一个 exe程序,双击打开,会看到下面这个界面,记得勾选图中这个,其他的不要勾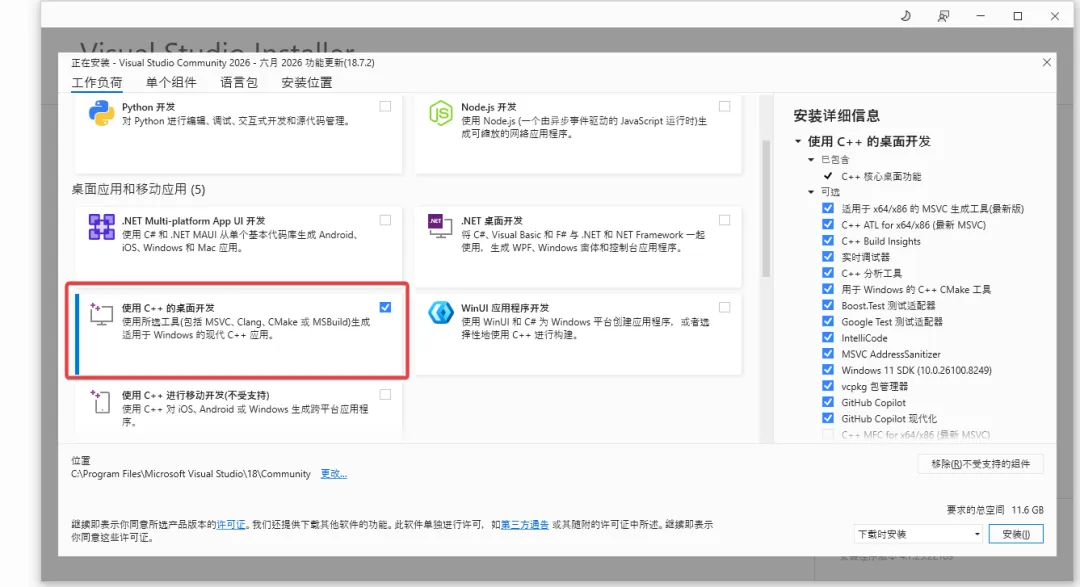
然后点右下角安装就行了,安装完成后重启电脑
二、GPU环境
unsetunset1、安装显卡驱动unsetunset
nvidia-app 主页地址[4] NVIDIA_app_v11 下载地址[5] 安装 NVIDIA app 程序,无脑下一步就行。
unsetunset2、安装CUDA 程序unsetunset
cuda 版本大于11就行,我用的是12
执行 nvidia-smi看你的显卡是否支持cuda 11以上。cuda 12 下载地址[6] 安装选项记得选择 自定义: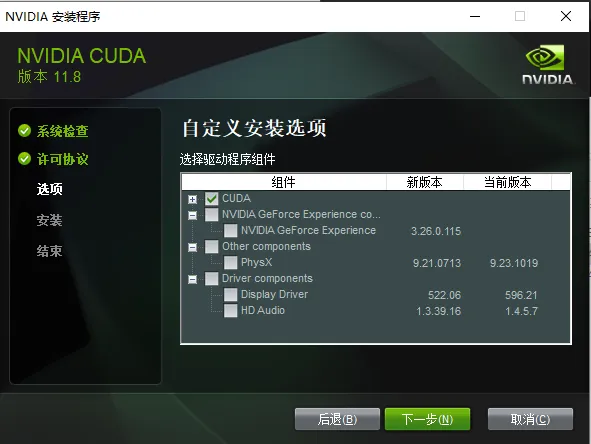
然后一路点下一步。都完成后记得重启一下电脑。
三、运行环境
unsetunset1、下载源代码unsetunset
我用的是专用n卡版本 v2pro-20250604-nvidia50[7]
注意:这个nvidia50不是说必须要是nvidia 50系列的显卡哈,我用nvidia 3060也能运行。
unsetunset2、创建基础python环境unsetunset
GPT-SoVITS[8] 要求 python=3.10,所以执行conda create -n tts python=3.10 -y激活环境 conda activate ttscd到源代码目录cd C:\Users\lc\work\GPT-SoVITS-v2pro-20250604-nvidia50(lc是我的电脑用户名,代码我放在c盘了)用 conda安装ffmpeg,运行conda install ffmpeg安装项目依赖 pip install -r extra-req.txt --no-deps、pip install -r requirements.txt安装额外依赖 pip install torchcodec
unsetunset3、下载权重文件unsetunset
aria2c是一个liunx下的断点续传的多线程下载器,我在windows wsl下使用的。如果没有可以复制下载链接到浏览器,正常下载即可。
aria2c -s16 -x16 --file-allocation=none -o "s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt" -d./GPT_weights_v2 https://huggingface.co/lj1995/GPT-SoVITS/resolve/main/s1bert25hz-2kh-longer-epoch%3D68e-step%3D50232.ckpt?download=truearia2c -s16 -x16 --file-allocation=none -o "s2G488k.pth" -d./SoVITS_weights_v2 https://huggingface.co/lj1995/GPT-SoVITS/resolve/main/s2G488k.pth?download=true到这里,就可用启动了
本地启动 python api_v2.py允许远程访问 python api_v2.py -a 0.0.0.0 -p 9880web-ui方式 双击go-webui.bat或python webui.py
注意,我是启动了api_v2.py将它当作一个tts api服务在运行,额外编写python脚本来调用它来完成更多的自定义功能。如果只需要界面的用界面启动方式就可以了。
四、编写自定义脚本调用tts api
下面是我让AI 按我的要求写的脚本,完成了以下功能
ios下的epub电子书,按章节解析并生成。TXT电子书按章节解析并生成。。指定文本的声音生成。 自定义音色文件。 自定义感情曲线、语速节奏等参数。
运行之前,需要先安装一些依赖
pip install requests ebooklib beautifulsoup4 tqdm下面是完整的代码(记得把文件路径改成自己的)
import jsonimport reimport osimport threadingimport timeimport requestsimport ebooklibfrom ebooklib import epubfrom bs4 import BeautifulSoupfrom concurrent.futures import ThreadPoolExecutor, as_completedfrom tqdm import tqdm# ==========================================# 第一部分:小说解析器模块 (可扩展)# ==========================================class BaseParser:"""解析器基类""" def get_chapters(self, file_path): raise NotImplementedError("子类必须实现 get_chapters 方法") def _basic_clean(self, text):"""通用清洗逻辑""" text = re.sub(r'https?://\S+', '', text) text = re.sub(r'[=+\-]{5,}', '', text)return text.strip()class TxtParser(BaseParser):"""纯文本解析器""" def get_chapters(self, file_path): with open(file_path, 'r', encoding='utf-8') as f: content = f.read() pattern = r'(第[一二三四五六七八九十百千万零\d]+[章节回].*)' parts = re.split(pattern, content) chapters = []for i in range(1, len(parts), 2): title = parts[i].strip() body = self._basic_clean(parts[i + 1])if body: chapters.append({"title": title, "content": body})return chapters def get_chapters_text(self, file_path): with open(file_path, 'r', encoding='utf-8') as f: content = f.read()return contentclass EpubParser(BaseParser):"""EPUB 解析器 - 增强正则版""" def get_chapters(self, file_path): book = epub.read_epub(file_path) chapters = []# 严格的章节匹配正则# 匹配:第1章、第一章、序言、前言、楔子、后记 等 title_pattern = r'^(第[一二三四五六七八九十百千万零\d]+[章节回].*|序言|前言|楔子|后记|尾声|第[一二三四五六七八九十百千万零\d]+部分.*)'for item in book.get_items():if item.get_type() == ebooklib.ITEM_DOCUMENT: soup = BeautifulSoup(item.get_content(), 'html.parser')# 1. 提取所有文本并清洗 raw_text = soup.get_text() content = self._basic_clean(raw_text)if len(content) < 50: continue# 忽略掉太短的片段(如版权页)# 2. 寻找真正的标题 lines = [l.strip() for l in content.split('\n') if l.strip()]if not lines: continue# 逻辑:检查第一行是否符合章节正则 first_line = lines[0]if re.match(title_pattern, first_line): title = first_line# 既然第一行是标题,正文就从第二行开始,避免重复读标题 body_content = "\n".join(lines[1:])else:# 如果第一行不匹配正则,说明这个 HTML 文件可能没有明确标题# 比如封面、简介,或者是被切碎的正文续接# 我们尝试找 HTML 的 h1-h3 标签再校验一次 header = soup.find(['h1', 'h2', 'h3'])if header and re.match(title_pattern, header.get_text().strip()): title = header.get_text().strip() body_content = contentelse:# 最终兜底:如果完全没标题,可能是正文的延续,起个序列名或跳过# 这里我们取前15个字作为标识,或者你可以选择直接跳过非章节内容 title = f"正文片段_{lines[0][:10]}" body_content = content# 3. 文件名安全处理 safe_title = re.sub(r'[\\/:*?"<>|]', '_', title).strip() safe_title = safe_title[:40] # 限制文件名长度 chapters.append({"title": safe_title, "content": body_content})return chapters# ==========================================# 第二部分:TTS 核心引擎模块# ==========================================class TTSEngine: def __init__(self, api_base="http://localhost:9880"): self.api_base = api_base# 默认配置 self.config = {"gpt_path": "C:/Users/lc/work/GPT-SoVITS-v2pro-20250604-nvidia50/GPT_weights_v2/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt","sovits_path": "C:/Users/lc/work/GPT-SoVITS-v2pro-20250604-nvidia50/SoVITS_weights_v2/s2G488k.pth","ref_audio": "C:/Users/lc/work/音色.wav","prompt_text": "今天下大雨,但是我没带伞,有人给我送伞吗","prompt_lang": "zh" } self._init_models() def _init_models(self):print(f"[*] 初始化引擎: 加载模型中...") requests.get(f"{self.api_base}/set_gpt_weights", params={"weights_path": self.config["gpt_path"]}) requests.get(f"{self.api_base}/set_sovits_weights", params={"weights_path": self.config["sovits_path"]}) def generate(self, title, text, output_path):"""核心合成方法 - 增强版""" params = {"text": text,"text_lang": "zh","ref_audio_path": self.config["ref_audio"].replace("\\", "/"),"prompt_text": self.config["prompt_text"],"prompt_lang": self.config["prompt_lang"],# --- 核心调优:长时间听书方案 ---"text_split_method": "cut2", # 改用 cut2:按句号+逗号切分,比 cut1 更连贯,比 cut5 更清晰"top_k": 5, # 【疯狂收紧】从 10 暴降到 5!强行在极高温度下,只允许 AI 选择最契合情绪的前 5 个音节候选,防止字音发散崩溃"top_p": 0.85, # 【首次截断】从 1.0 降到 0.85。过滤掉高升温带来的尾音毛刺和杂音"temperature": 1.45, # 【生死线】直接轰到 1.45!这是未解密/魔改版内核的极限,声音的抑扬顿挫会变得极其夸张,充满戏剧化的拿腔拿调"speed_factor": 1.05, # 【语速微催】提高到 1.05x。人在情绪激动(愤怒、惊恐、狂喜)时,语速会本能地加快,更加逼真"half": True, # 半精度推理"media_type": "wav","streaming_mode": False, } try: tqdm.write(f"[>>>] 开始合成: {title}")# 使用 POST 请求。GPT-SoVITS API v2 支持 POST 传参,避免 URL 过长报错# 注意:POST 请求参数通常放在 json=params 中 response = requests.post(f"{self.api_base}/tts", json=params, timeout=None)if response.status_code == 200:# 检查返回内容是否为空if not response.content:print(f"[!] {title} 失败: 服务器返回了空数据")return False, title with open(output_path, "wb") as f: f.write(response.content)return True, titleelse:# 优化点 2:安全地处理非 200 状态码print(f"[!] {title} 失败: {response.text}") try:# 尝试解析错误信息,如果不成 JSON 就输出原始文本 err_info = response.json()print(f" 详情: {err_info.get('message', '未知错误')}") except:print(f" 原始报错信息: {response.text[:200]}") # 只打印前 200 字防止刷屏return False, title except Exception as e:print(f"[!] {title} 合成异常 (网络或系统级): {e}")return False, title# ==========================================# 第三部分:业务调度逻辑# ==========================================def start_task(file_path, output_dir):# 1. 解析器选择 ext = os.path.splitext(file_path)[-1].lower() parser = EpubParser() if ext == '.epub'else TxtParser()# 2. 解析内容print(f"[*] 正在解析文件: {file_path}") raw_chapters = parser.get_chapters(file_path)# 过滤非章节内容 title_pattern = r'^(第[一二三四五六七八九十百千万零\d]+[章节回].*|序言|前言|楔子|后记|尾声)' chapters = [ch for ch in raw_chapters if re.match(title_pattern, ch['title'])] total_chapters = len(chapters)if total_chapters == 0:print("[-] 未识别到任何有效正文章节,请检查解析器正则。")return# 3. 初始化引擎 engine = TTSEngine()# 4. 准备目录if not os.path.exists(output_dir): os.makedirs(output_dir)print(f"[*] 识别到正文 {total_chapters} 章,开始处理...")# --- 核心修改逻辑 --- with tqdm(total=total_chapters, desc="总进度", unit="章") as pbar: with ThreadPoolExecutor(max_workers=100) as executor: task_mapping = {}for i, ch in enumerate(chapters):# 生成安全的文件名 safe_title = re.sub(r'[\\/:*?"<>|]', '_', ch['title']) file_name = f"{i + 1:03d}_{safe_title}.wav" save_path = os.path.join(output_dir, file_name)# 检查文件是否已存在if os.path.exists(save_path): pbar.update(1)# tqdm.write(f"[横跳] 跳过已存在章节: {ch['title']}") # 如果觉得日志太吵可以注释掉这行continue# 如果不存在,才提交任务 future = executor.submit(engine.generate, ch['title'], ch['content'], save_path) task_mapping[future] = ch['title'] tqdm.write(f"[→] 已提交: {ch['title']}")# 如果没有新任务需要执行,直接结束if not task_mapping:print("[+] 所有章节均已存在,无需生成。")return# 实时获取执行中的任务结果for future in as_completed(task_mapping): ch_title = task_mapping[future] try: success, title = future.result()if success: pbar.update(1) tqdm.write(f"[√] 已合成: {title}")else: tqdm.write(f"[×] 失败: {title} (请检查 API 报错)") except Exception as e: tqdm.write(f"[!] 运行异常: {ch_title} | 原因: {e}")print(f"\n[+] 任务处理完成!")def start_task2(file_path, output_dir):# 1. 解析器选择 parser = TxtParser()# 2. 解析内容print(f"[*] 正在解析文件: {file_path}") raw_text = parser.get_chapters_text(file_path)# 3. 初始化引擎 engine = TTSEngine()# 4. 准备目录if not os.path.exists(output_dir): os.makedirs(output_dir)# 生成安全的文件名 safe_title = re.sub(r'[\\/:*?"<>|]', '_', "录音") file_name = f"{safe_title}.wav" save_path = os.path.join(output_dir, file_name) engine.generate(title="主播录音", text=raw_text, output_path=save_path)print(f"\n[+] 任务处理完成!")if __name__ == "__main__":# 使用示例# 只需要传入文件,程序会自动识别解析器# start_task("遮天.epub", "output_final") start_task2("text.txt", "output_final2")收工,非常简单,实际上可以把这个脚本改成,实时读取麦克风流,然后流式调用这个tts api就可以实现在线实时变音。
四、部署建议
这个有CPU版本,我试过了,贼慢,如果套了nginx代理,注意超时设置和缓存设置。 按当前GPU版本,基本上可以实现秒级生成声音。
警告与声明
本文仅作为开源项目的AI技术应用学习和研究,不作为任何商业目的,更加不提供任何违法犯罪的技术传播或支持。
GPT-SoVITS: https://github.com/RVC-Boss/GPT-SoVITS
[2]Microsoft Visual Studio C++ Build Tools: https://visualstudio.microsoft.com/zh-hans/downloads/?q=build+tools
[3]Visual Studio C++ Build Tools: https://visualstudio.microsoft.com/zh-hans/downloads/?q=build+tools
[4]nvidia-app 主页地址: https://www.nvidia.com/zh-tw/software/nvidia-app/
[5]NVIDIA_app_v11 下载地址: https://tw.download.nvidia.com/nvapp/client/11.0.7.237/NVIDIA_app_v11.0.7.237.exe
[6]cuda 12 下载地址: https://developer.nvidia.com/cuda-12-1-0-download-archive
[7]v2pro-20250604-nvidia50: https://www.modelscope.cn/models/FlowerCry/gpt-sovits-7z-pacakges/resolve/master/GPT-SoVITS-v2pro-20250604-nvidia50.7z
[8]GPT-SoVITS: https://github.com/RVC-Boss/GPT-SoVITS
