 夜雨聆风
夜雨聆风我会用10分钟,教你搭一个真正能帮你干活的AI知识库。它不是收藏夹,不是笔记本,而是一个能自己读资料、自己做笔记、自己产出成果的 agent 系统。
打开豆包电脑版,进入「办公任务」,选择项目,创建一个文件夹。
然后把下面这段提示词发给豆包:
请帮我生成一个简略版 AI 自生长知识库
你现在是我的本地知识库搭建助手。
请在当前目录下创建一个文件夹:
AI自生长知识库-简略版/
这是一个免费版、简略版框架,不需要做复杂配置,不需要安装插件,不需要一键脚本。
目标只有一个:
让我能把资料放进去,让 AI 帮我消化,再产出文章、学习笔记或选题。
请创建这些文件夹
AI自生长知识库-简略版/
├── 00-原始资料/
├── 01-AI消化笔记/
├── 02-方法库与提示词/
├── 03-输出成果/
└── 04-复盘/
请创建根目录 README.md
内容请包含:
这个知识库是干什么的
五个文件夹分别放什么
最小工作流:
00-原始资料/
→ 01-AI消化笔记/
→ 03-输出成果/
→ 04-复盘/
一句话原则:
收藏只是入口,回流才是知识库开始自生长的地方。
提醒我:不要一开始追求完美分类,先跑通一份真实材料。
请创建 00-原始资料/README.md
说明这里可以放:
文章
视频逐字稿
课程笔记
读书摘录
聊天记录
灵感
网页摘录
并提醒我:
原始资料不用先整理,先放进来。
请创建 01-AI消化笔记/README.md
说明这里不是摘要区。
每篇消化笔记必须回答:
这份材料对我有什么用?
推荐结构:
一句话结论
原始资料讲了什么
对我有什么启发
可以变成什么输出
下一步动作
请创建 02-方法库与提示词/原始资料消化提示词.md
写入下面这段提示词:
请读取我指定的原始资料,生成一篇 AI 消化笔记。
不要只做摘要。请重点回答:这份材料对我有什么用?
请按以下结构输出:
一句话结论 原始资料讲了什么 核心观点拆解 对我的学习、创作或工作有什么启发 可以变成什么输出 下一步动作
如果适合写成文章、知乎回答、小红书图文或视频脚本,请顺便指出。
请创建 03-输出成果/README.md
说明这里放:
文章大纲
文章初稿
知乎回答
小红书图文
视频脚本
学习总结
并加入输出回流卡:
输出回流卡
这次输出用了哪些原始资料: 新产生了什么观点: 哪个段落以后还能复用: 产生了哪些新问题: 是否形成新方法:
请创建 04-复盘/README.md
说明这里每周记录一次:
本周放进来了哪些资料
哪些资料真的被消化了
哪些内容产出了文章或笔记
哪个环节最有用
下周只推进哪三件事
请创建 CLAUDE.md
这是 Claude Code 的入口规则。
请写入:
先读取 README.md
新资料进入后,先生成 AI 消化笔记,不要直接写成品
消化笔记必须回答“这份材料对我有什么用”
输出成果必须附输出回流卡
默认先文章化,再考虑视频化
不要替我删除原始资料
完成后请告诉我
请列出你创建了哪些文件,并告诉我第一步应该往 00-原始资料/ 放什么。
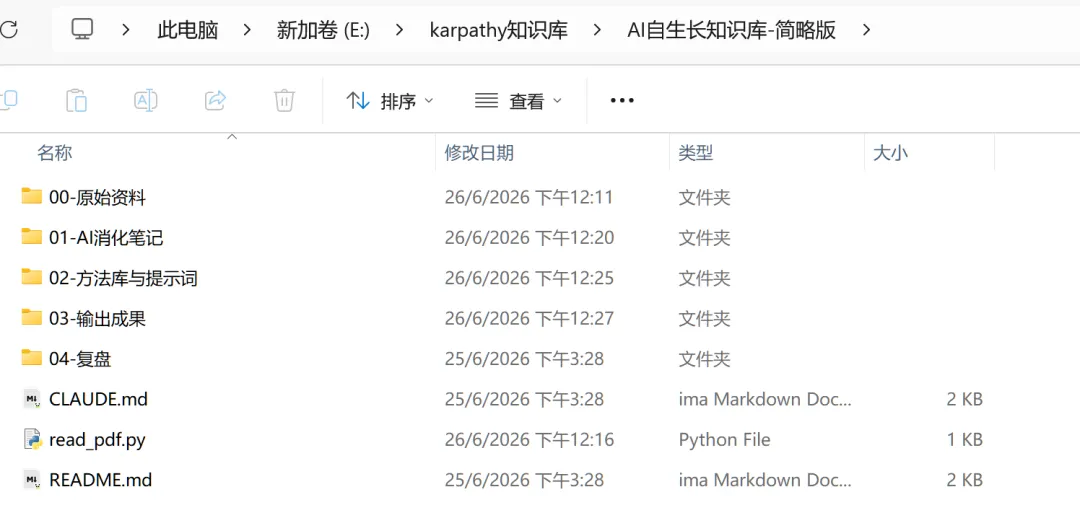
- 00-原始资料
:你收集的所有未处理材料——论文、文章、聊天记录、灵感碎片,都丢这里 - 01-AI消化笔记
:AI读完资料后生成的笔记,这是从"原料"到"成品"的中间层 - 02-方法库与提示词
:从笔记里提炼出来的、可以反复复用的方法、模板、工作规则 - 03-输出成果
:最终的成品——文章、报告、视频脚本、小红书图文 - 04-复盘
:每周记录哪些资料真的被消化了、哪些内容产出了成果,让系统持续优化
从左到右,从原料到成品,再从复盘回到原料——形成一个闭环。
这就是你的AI系统的地基。后面不管你换什么工具,这个结构都不用变。
现在,我们来投喂第一批资料。
放什么都行——你最近读的一篇文章、存的一份报告、收藏的一篇公众号推文、甚至是一段聊天记录。只要是你想让AI帮你消化的内容,都可以丢进去。
为了演示,我往里面放了五篇英文论文。
然后用自然语言告诉豆包,这是我的本地知识库,拿来学习论文的。
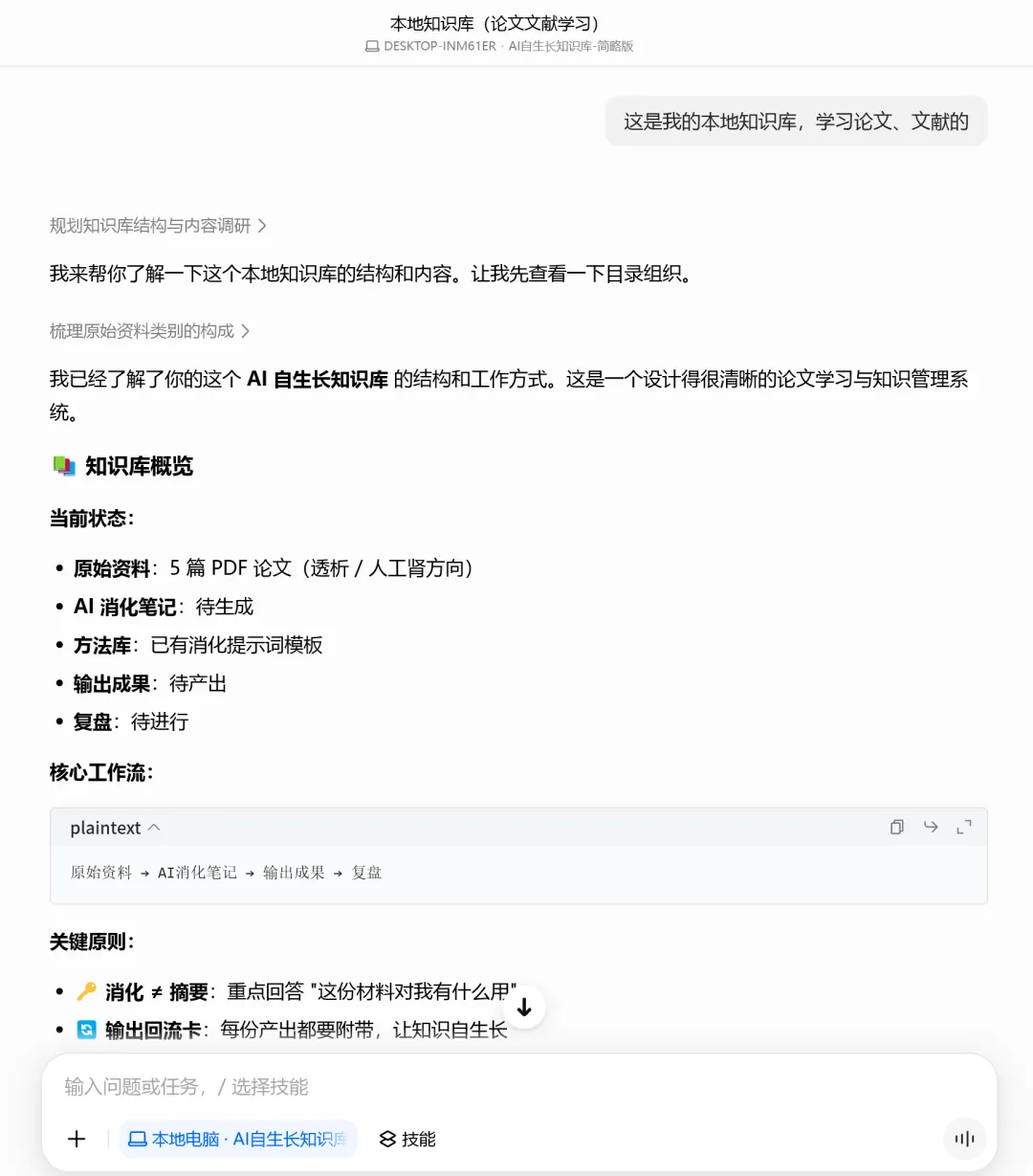
等一会会,豆包已经识别到了你放入的文件。
这就是 agent 模式和 chat 模式的第一个本质区别:AI 能看到你文件夹里有什么了。 你不需要把文件内容复制粘贴给它,也不需要上传附件。它就在你的文件夹里,随时可以读。
然后对它说一句:
批量消化所有论文,一次性生成 5 篇消化笔记。
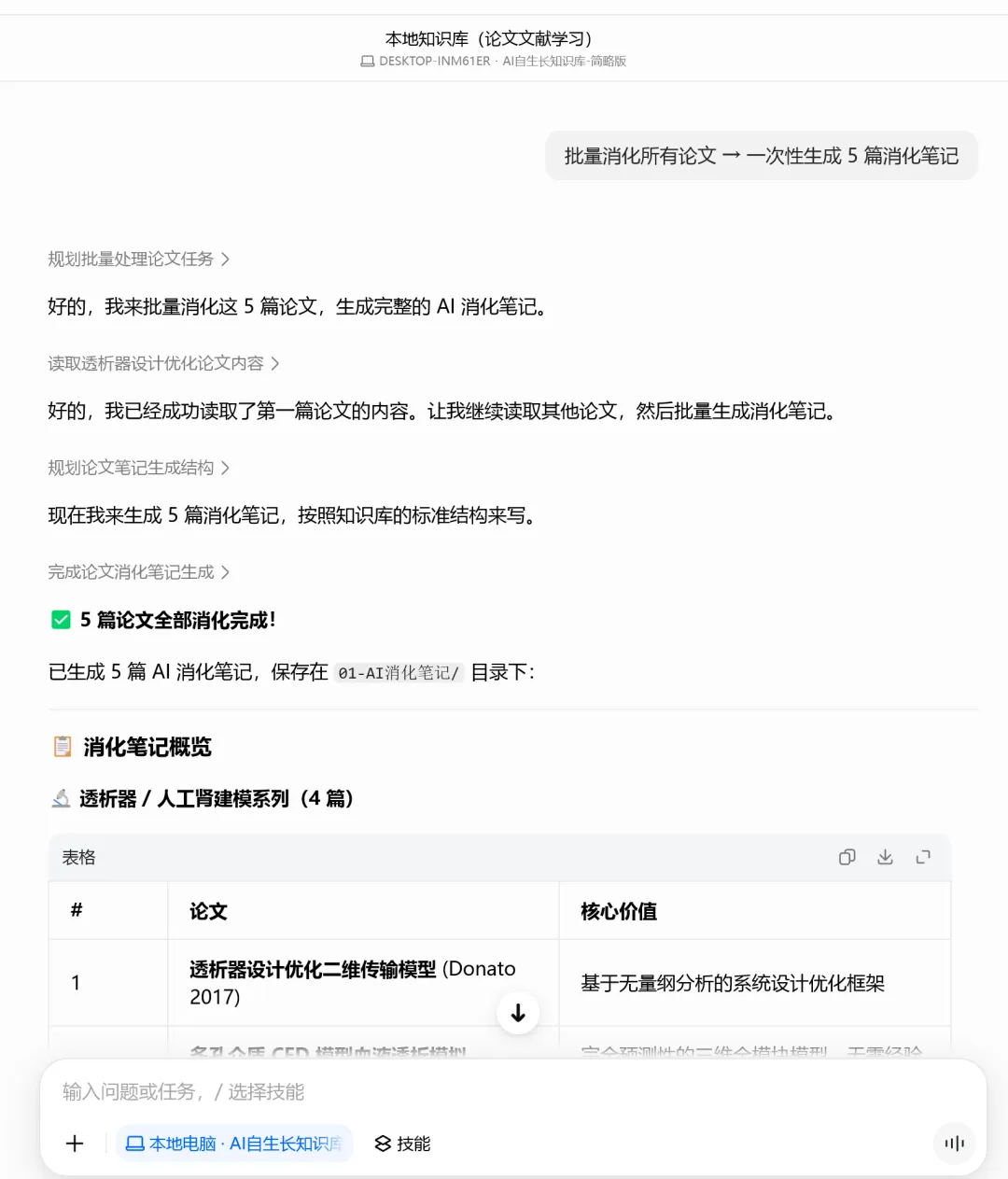
豆包会一篇一篇地读取资料,按照你之前定义的格式生成消化笔记,然后自动保存到 01-AI消化笔记/ 文件夹里。
等它干完活,会给你一个汇报。
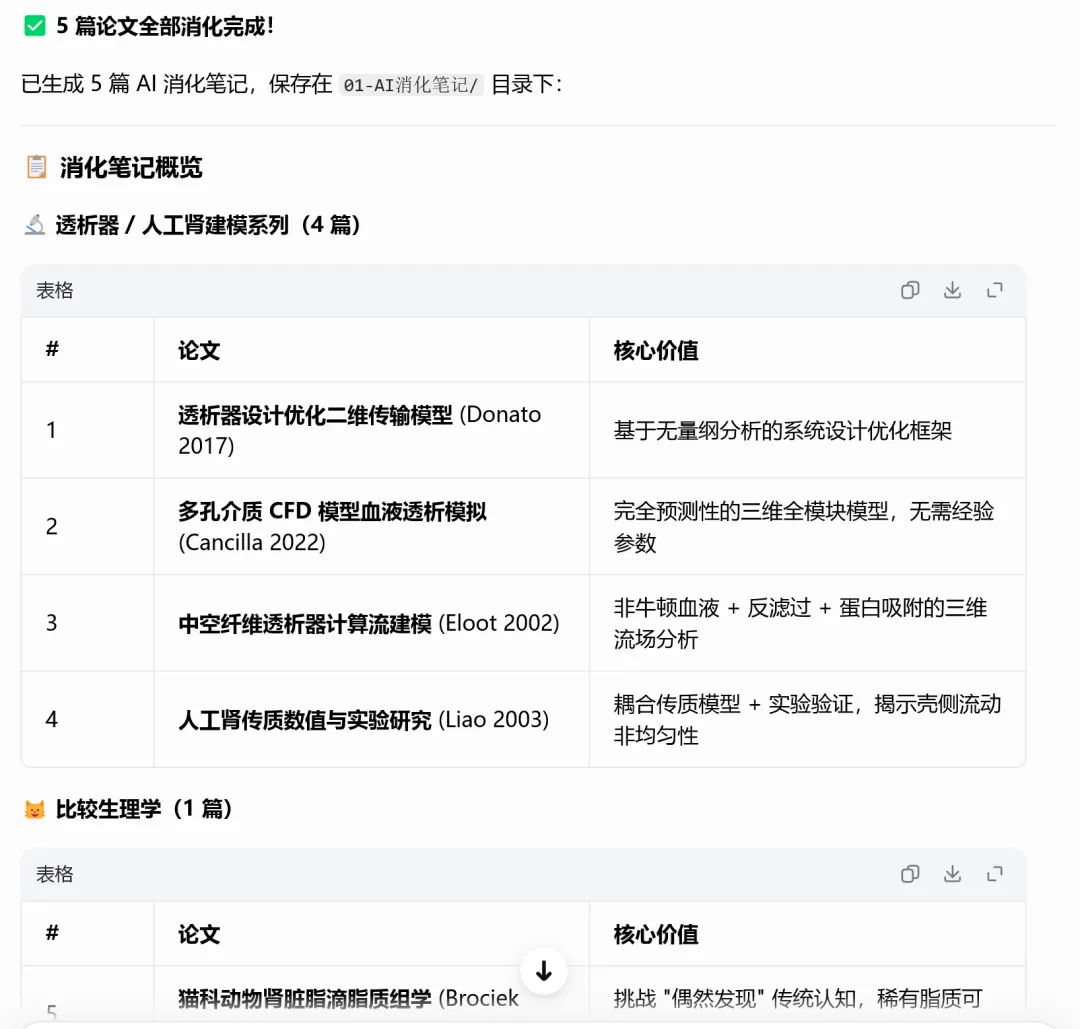
你打开文件夹看看,五篇消化笔记已经整整齐齐地躺在那里了。
每一篇都按照你定义的结构:一句话结论、原始资料讲了什么、核心观点拆解、对我的启发、可以变成什么输出、下一步动作。
随便打开一篇看看:

注意,这不是简单的翻译或摘要。
AI 做了一件更重要的事:它站在你的角度,回答了"这份材料对我有什么用"这个问题。
这就是为什么我们把它叫做"消化笔记"而不是"摘要"。摘要只是把原文缩短,消化是把别人的知识,变成对你有用的东西。
消化笔记不是终点。它是中间产物,是从"原料"到"成品"的过渡。
有了消化笔记之后,你可以继续让 AI 往前走一步:把这些笔记提炼成可复用的方法,或者直接产出最终的成果。
比如,你可以对豆包说:
继续工作,处理 02-方法库与提示词、03-输出成果。这是一个辅助我学习的本地知识库,你继续工作。

豆包会继续读取 01-AI消化笔记/ 里的内容,从中提炼出可以复用的方法和模板,写入 02-方法库与提示词/;同时根据笔记内容,生成一些可以直接使用的输出成果,写入 03-输出成果/。
干完之后,它会再次给你汇报:

到这里,你的知识库就完成了一次完整的流转:
原始资料 → AI 消化笔记 → 方法库 → 输出成果
这就是我们常说的"知识流动"。资料不是堆在那里落灰,而是经过消化、提炼,最终变成对你有用的产出。
而这一切,你只做了两件事:把资料丢进文件夹,然后对 AI 说了两句话。
这就是 agent 模式的力量,当然,这只是开始。你的知识库现在还只有几篇消化笔记,输出成果也只有寥寥几个。
但没关系——系统已经跑起来了。接下来,你只需要持续往里面投喂资料,它就会越长越大,越来越懂你。
你的收藏夹再也不会落灰了,你读过的每一篇文章、听过的每一节课,都会真正变成你的知识资产。
快去试试吧,发一段提示词,丢几篇你一直想看但没看的资料进去。
然后回来告诉我,你的AI助手都帮你干了什么活?
