 夜雨聆风
夜雨聆风澄偊而行 · 原创丨 技术科普 · AI硬件
2026年,英伟达市值一度突破5万亿美元,成为全球市值最高的公司。B200一卡难求,新一代GPU排队到2028年。所有人都在盯着GPU。
但有一个问题很少人问:那张GPU插在什么东西上面?
答案是——一块你从没见过的、价值数十万美元的AI算力主板。
这块主板上面不止有GPU。它上面跑着比GPU更稀缺、利润更惊人的零部件。英伟达每卖出一块B200,自己赚走一大块蛋糕的同时,周围还有一群"卖铲人"——他们不会出现在英伟达财报上,但他们的名字刻在每一块AI算力主板的毛细血管里。
这篇文章,我们就来把这块最贵的主板一层一层扒开,看清楚除了黄仁勋,还有谁在AI淘金热里低调发财。
一、AI算力主板长什么样?
普通服务器的板子你可能见过:一块绿色PCB,插着CPU、内存条、硬盘接口、网卡,大概几千块钱。
AI算力主板完全不是一回事。
以英伟达DGX系统里的8卡主板为例:
尺寸:远大于普通服务器主板,通常需要定制机箱
层数:不是普通电脑的8层PCB,而是16层、24层甚至28层
厚度:比普通PCB厚40%以上,因为铜箔层厚得多、线宽更细
价格:一块DGX B200的8卡主板,仅PCB裸板就要近万美元,加上各种芯片和连接器后轻松突破10万-20万美元
这块主板上,肉眼能看到的东西包括:
二、CPU——总指挥:谁在给AI分配任务?
前面我们看到主板上密密麻麻的组件——其中最容易被忽视的,是两颗不在聚光灯下的CPU。
CPU(中央处理器),你电脑里那颗Intel或AMD芯片就是它。几十个核心,每颗都很强,什么都会、什么都不快——适合跑操作系统、做逻辑判断、管理内存和硬盘。
在AI服务器里,CPU的角色像工地的项目经理:自己不搬砖,但所有调度、分配、监控都是它在做。
一块DGX B200主板上装着2颗CPU(Intel Xeon或AMD EPYC),它们的工作清单包括:
从硬盘或网络读取训练数据,切分好,分给8颗GPU
告诉每颗GPU"你算这一块,你算那一块"
监控8颗GPU的温度、功耗、有没有哪颗掉队
8颗GPU算完后,把结果汇总、写回存储
没有CPU,GPU连"该算什么"都不知道。
AI训练不是你给GPU丢一本《三国演义》它就能自己读完——是CPU把书拆成80个段落,给8颗GPU每人分10段,再告诉它们该算什么,全程盯进度。
CPU的供应商很集中:Intel和AMD,两家包揽了全球99%以上的服务器CPU市场。在AI服务器里,它们不抢英伟达的风头,但每一块DGX主板都离不开它俩——典型的"卖铲人",卖的是"调度能力"。
三、GPU——特种部队:AI的真正算力引擎
CPU分完任务之后,真正干活的是GPU。
GPU(图形处理器)最初是为游戏画面渲染设计的,但人们很快发现了一个更有价值的用途:它的几千颗小核心,天生适合"同样的事情同时算很多份"——这叫并行计算。
AI训练的本质是什么?矩阵乘法。 不管是ChatGPT生成一句话,还是Sora渲染一帧画面,底层99%的时间都在做大数字表格乘来乘去。这件事,CPU算很慢,GPU一瞬间就能跑完。
CPU 像一位数学教授——能解微分方程,但一次只能算一道题
GPU 像一个教室坐满了一万个中学生——每人只会加减乘除,但一万人同时算,总速度碾压教授
以英伟达B200为例,它内部有两套计算引擎:
CUDA核心:通用计算主力,几千颗同时工作
Tensor核心:AI专用加速器,专门处理矩阵乘法。H100的第四代Tensor核心支持FP8精度,同功耗下AI计算速度比上一代快好几倍
在DGX主板上,2颗CPU配对8颗GPU。CPU负责"想",GPU负责"算"——两个角色各司其职,一台DGX才能在一眨眼功夫里学完一万本书。
GPU赛道是目前AI硬件里竞争最激烈的:AMD有MI300系列、Intel有Gaudi 3、华为有昇腾、寒武纪和摩尔线程也在追。但现阶段英伟达B200/H100依然占据AI训练市场90%以上的份额——原因我们在后面会谈到。
搞清楚了CPU和GPU的分工,接下来我们看主板上那些比GPU更稀缺的零部件。
四、第一个卖铲人:HBM——卡住英伟达脖子的记忆体
没有HBM,GPU就是一块废铁。
这不是夸张。B200每一个GPU旁边必须紧贴着8颗HBM3e显存。没有这些HBM,GPU连数据都吃不到。
为什么HBM这么重要?
普通电脑的内存和GPU是分开的,数据通过窄窄的内存总线搬运,带宽大概几十到一百GB/s。但对于训练GPT-5这样的模型——一次训练要搬运的数据量相当于把整个美国国会图书馆的书籍全部读完几十遍——这个速度远远不够。
HBM的做法非常粗暴但有效:把内存直接堆叠在GPU旁边,通过硅中介层用几千根微观连线直连。 这相当于把"从书房走到客厅拿书"改成了"书就摊在书桌旁边一伸手就够到"。
带宽差距动辄几十倍。
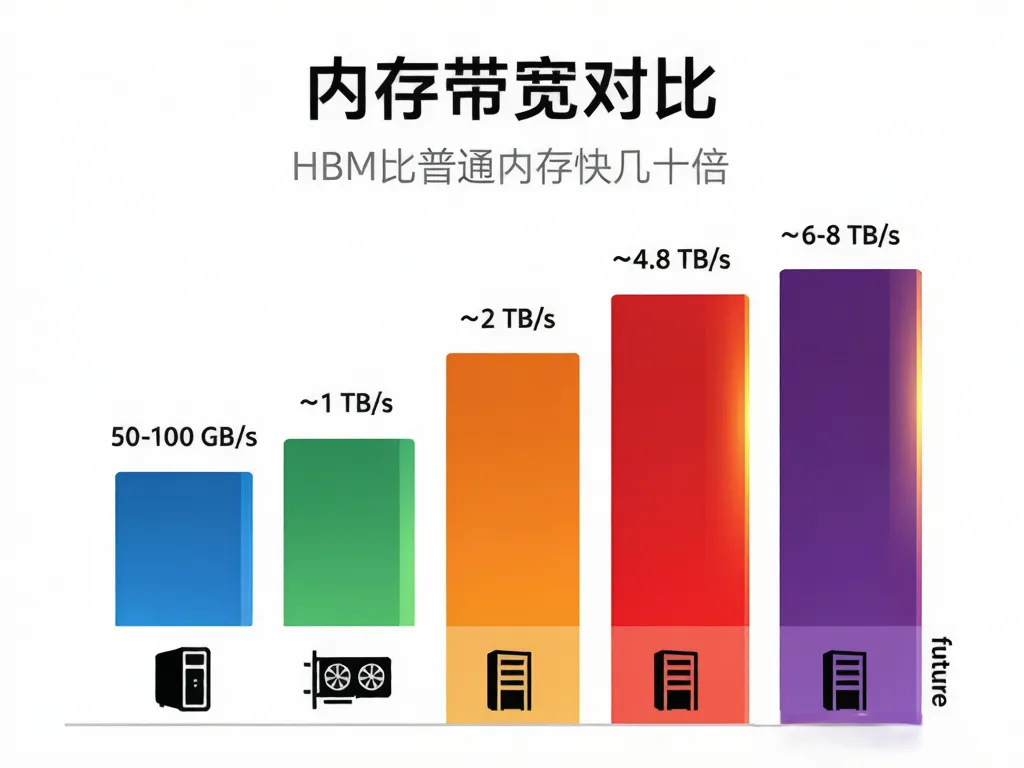
▲ 图2:从DDR5到HBM4,内存带宽差距一目了然——HBM3e比普通内存快几十倍
谁在做HBM?
全球能干这个事的,就三家:SK海力士、三星、美光。
但三家不是平分天下——SK海力士吃掉了90%以上的英伟达HBM订单。三星和美光目前都还在爬坡。
2024年SK海力士的HBM营收同比翻了3倍以上,2025年继续翻倍。黄仁勋在公开场合多次喊话SK海力士"请加快HBM4的进度"——这种话英伟达对供应商极少说,足以说明HBM有多难替代。
HBM的定价权有多恐怖?
一颗HBM3e的单价约1500-2000美元
一颗同容量的普通DDR5内存颗粒,大概只要几十美元
同容量,HBM贵了几十倍
而且HBM良率不到60%,远低于普通内存的95%+——每一颗都经过数千项测试,因为它一旦失效,旁边那个几万美元的GPU也跟着废了
小结:HBM是AI算力主板上利润最惊人、供应最集中的环节,比GPU更稀缺。英伟达卖GPU还得面对AMD、Intel的竞争和华为昇腾的追赶;而HBM这个赛道,SK海力士几乎没有对手。
五、第二个卖铲人:CoWoS先进封装——台积电的隐藏金矿
先搞清楚一个容易被忽视的事实
大多数人以为:H100/B200 = 台积电做好GPU芯片 → 英伟达拿走 → 装到主板上。
实际情况复杂得多。
GPU芯片做好之后,还不能直接用。它需要跟HBM显存做一次"超级精密手术"——把GPU和HBM拼到同一块硅中介层上,再用CoWoS先进封装技术密封成一个完整的"算力砖块"。
这步专利技术全球只有台积电能做大规模量产。
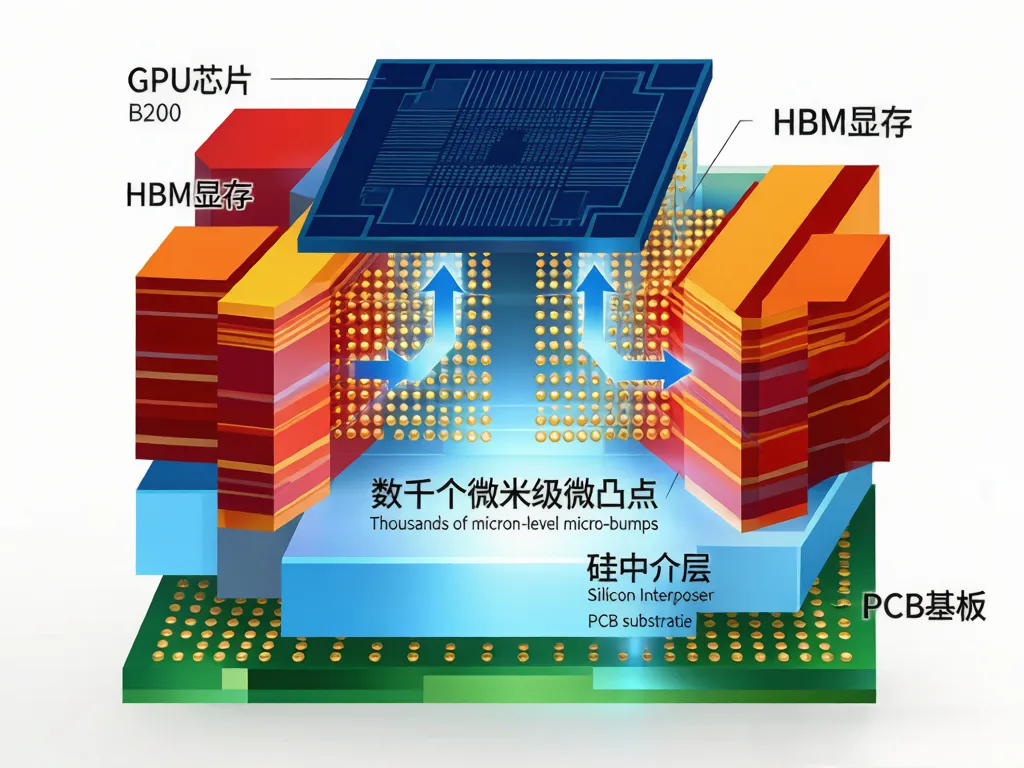
▲ 图3:CoWoS先进封装截面结构——GPU和HBM通过硅中介层(Interposer)精密连接
CoWoS为什么是瓶颈?
一个H100的CoWoS硅中介层面积大约是整块12寸晶圆切下来的很大一块(约800mm²),而且工艺复杂——要在硅片上刻出几千根互连线,每一根都比头发丝的千分之一还细,连接GPU和HBM。
这意味着:一片12寸晶圆能切出的硅中介层数量非常有限;CoWoS产能跟不上GPU产能;台积电的CoWoS成了整个AI产业的最大瓶颈之一。
2024年,台积电的CoWoS产能被英伟达、AMD、博通、微软、亚马逊等客户抢购一空,排队等到2026年。
2025年台积电把CoWoS月产能从2023年的约1.5万片扩张到3.5万-4万片,2026年目标7万片+,但依然不够用。
谁能分一杯羹?
除了台积电之外,三星和英特尔也有类似技术(三星叫I-Cube,英特尔叫EMIB),但目前产能和良率都远不及台积电。
但现阶段,CoWoS约90%的份额在台积电手里。有人估算,台积电从每一颗B200身上赚到的总营收可能接近2000-3000美元——而它自己不用跟英伟达PK任何性能指标,纯粹坐收"卖铲人"红利。
六、第三个卖铲人:NVLink与高速铜缆——让GPU开口说话
8颗GPU装到一起之后,要不要互相"说话"?当然要。AI训练的本质是把一个大模型切成无数小块,分给几百颗GPU同时算,算完再汇总。如果GPU之间的通信慢了,几千亿美元的算力投资就打了水漂。
NVLink是英伟达自研的GPU高速互联协议,速度比行业通用的PCIe快得多:
NVLink的速度是PCIe的20-50倍。

▲ 图4:NVLink vs PCIe互联带宽对比——NVLink每一代翻倍,速度远超行业通用标准
而NVLink要真正发挥作用,需要两个东西:NVSwitch交换芯片(英伟达自研,负责8颗GPU间的数据调度)和物理连接线——把这么多GPU的NVLink信号用铜缆或光缆真的连起来。
GPU之间的物理连接,目前主流用的是DAC高速铜缆(Direct Attach Copper)。随着NVLink带宽不断翻倍,铜缆的规格也越来越高——从400G到800G再到1.6T。全球能供货高速铜缆的厂商不多:安费诺、莫仕、泰科电子主导,但中国大陆厂商正在快速切入。
铜缆看似不起眼,但一块8卡DGX主板上的铜缆加起来价值不菲——而且随着Rubin平台升级到NVLink 6.0,铜缆的规格要求指数级上升,能做的供应商只会更少。
七、第四个卖铲人:PCB——AI算力的"骨架"
普通电脑主板8层PCB、线宽接近100微米就够了。AI算力主板的PCB要求完全不在一个量级:
| 20-28层 | ||
| 小于30μm | ||
| 超厚铜,2-3倍于常规 | ||
| 超低损耗高速材料 | ||
| 2.4mm+ | ||
| 数千-近万美元 |
高端AI服务器PCB全球能做好的企业不到10家:日本的Ibiden长期是英伟达H100/B200 PCB核心供应商;中国台湾的欣兴电子、臻鼎、华通是全球PCB产值最大地区;中国大陆的深南电路、沪电股份、胜宏科技等正在快速突破高端AI PCB,部分已进入英伟达PCB供应链。
八、第五个卖铲人:供电——喂饱这头电力怪兽
8颗B200满负载跑起来,功耗超过8000瓦。差不多相当于5台家用空调同时满功率制冷。
这么多电要稳定、精准地输送给GPU,靠的就是主板上密密麻麻的供电模块。AI算力主板上的供电系统由三部分组成:
电源管理芯片(PMIC):控制电压和电流精度,GPU核心电压波动超过1%,性能就受影响
MOSFET/DrMOS:负责大电流开关转换,一颗B200需要几十颗高性能MOSFET围绕它
电感/电容:滤波储能用,高端MLCC电容一颗单价可以到几美元
MPS(芯源系统)是这里面最值得关注的名字。它是全球AI供电芯片龙头,英伟达B200的DrMOS方案主要供应商——每一块B200主板上有几十颗它的芯片。它不跟英伟达比算力,不跟台积电比制程,不跟SK海力士比存储技术——它就靠给GPU供电,2024年AI相关营收暴涨,股价同样翻了数倍。
九、第六个卖铲人:光模块——主板之外的关键拼图
严格来说,光模块不在"主板"上,它在服务器外面。但它是AI算力系统不可分割的一环。
AI训练不是一台服务器的事——它是几千台服务器、几万张GPU组成一个集群在跑。GPU和GPU之间除了主板上的NVLink直连,跨服务器的数据还要通过高速网络传输。负责这种传输的,就是光模块。
每一次换代,光模块的单价比上一代差不多翻倍——因为技术难度指数级上升。
这个领域最大的"卖铲人"是中际旭创——全球800G光模块出货量第一,英伟达、谷歌、微软、亚马逊都是它的客户。不是GPU厂商,但它的市值和利润在过去两年随着AI浪潮暴涨。这就是"卖铲人"的魅力——淘金的人换了多少轮不重要,卖铲子的人每一轮都在赚钱。
十、一张AI算力主板上的利润蛋糕怎么分?
把前面的数据拼在一起,以一块8卡B200算力主板为例:

▲ 图5:一块DGX B200 8卡主板的价值分布——GPU占大头,但"卖铲人"们合起来也是一块大蛋糕
一张板子总价值约40万-60万美元。 英伟达分了最大的一块——但剩下的"卖铲人"们,每一家拿到的也都不是小钱。
而且更重要的是——你注意到没有?
GPU有竞争:AMD MI300、Intel Gaudi 3、华为昇腾、寒武纪都在追
HBM几乎没有竞争:SK海力士独占90%+
CoWoS几乎没有竞争:台积电独占90%+
高端AI PCB竞争有限:全球不超过10家能做
供电芯片竞争有限:MPS是B200主力供应商
GPU赛道越拥挤,"卖铲人"们的护城河反而越安全。
十一、未来怎么看?AI算力的下一块拼图
Rubin平台(2026-2027年推出)会是下一个分水岭。每颗Rubin GPU预计需要HBM4——带宽更大、功耗更高、工艺更难。这就意味着:
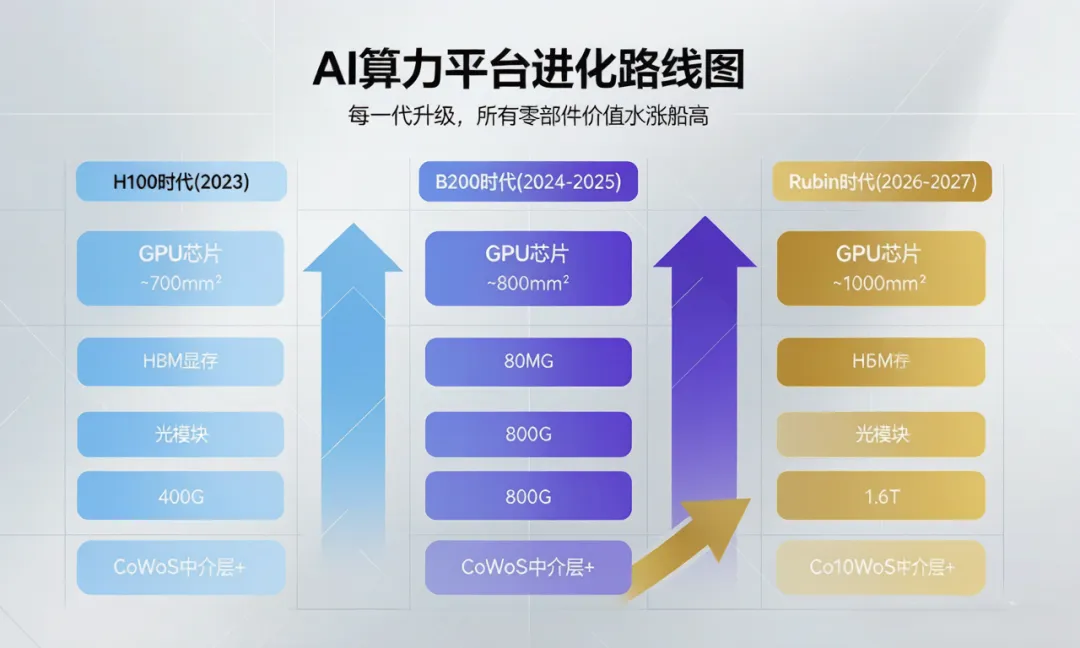
▲ 图6:AI算力平台三代进化路线——每一代升级,HBM、光模块、CoWoS全面水涨船高
HBM:SK海力士HBM4已送样,三星美光还在追赶,差距可能进一步拉大
CoWoS:中介层面积可能进一步扩大到1000mm²+,台积电产能瓶颈持续
PCB:NVLink 6.0(3.6TB/s)对信号损耗要求更苛刻,能做的厂更少
供电:Rubin功耗只增不减,供电芯片的需求量和单价都会继续涨
光模块:1.6T光模块将成为标配,能供货的厂商可能一只手数得过来
英伟达每推出一代新GPU,这块板上每一个零部件的价值都在水涨船高。
小结:别只盯着淘金的人
AI算力这场淘金热里,英伟达当然是最大的赢家。但如果你把视角拉远一点,会发现真正"稳赚"的群体,不是那些竞争最激烈的GPU厂商,而是那些把"唯一性"做到极致的底层供应商:
SK海力士——没有我的HBM,你的GPU就是一块废铁
台积电——没有我的CoWoS,你的GPU和HBM永远拼不到一起
MPS——没有我的供电芯片,你8颗GPU连开机都做不到
Ibiden/深南电路——没有我的PCB,你的信号连10厘米都跑不了
中际旭创——没有我的光模块,你的GPU集群就是一座座孤岛
黄仁勋造了铲子给大家用,但这些人才是造铲子原材料的人。
AI时代的每一次算力升级,不仅是英伟达的胜利,也是一条完整的、深度绑定的全球产业链的胜利——而在这个产业链里,最稀缺、最不可替代的"卖铲人",往往比最聪明的"淘金者"赚得更久。
