 夜雨聆风
夜雨聆风你手机里装的那个"AI换脸检测"APP,大概率没在干你以为它在干的事。
想象一下这个场景:你的银行客户经理突然打来视频电话,说"你昨天提交的贷款申请需要补一份材料,现在对着镜头念一下身份证号"。屏幕里的人脸、表情、说话节奏都和你记忆中的一模一样,你几乎没有犹豫就照做了。
三个月后,你发现这笔贷款被人以你的名义转走了。
这不是科幻电影的情节,而是2026年已经发生的真实案件。意大利银行 governor 被深度伪造视频 impersonate 用于投资诈骗,美国中期选举期间AI生成的政客广告满天飞,名人代言加密货币的假视频让州检察长发出紧急警告。深度伪造已经从实验室走向了日常犯罪工具。
而对抗这一切的第一道防线——AI换脸检测技术,最近被一篇论文扒了个底朝天。
考试越来越难,但考的可能是语文不是侦察
过去五年,深度伪造技术的进化速度呈指数级增长。从早期的FaceSwap换脸,到现在的Sora级视频生成、Voice Clone语音克隆、数字人直播,假内容的逼真度已经让普通人的肉眼彻底失效。
学术界和工业界都在疯狂堆 benchmark。视频检测有AIGVDBench(涵盖31个生成器、44万条视频)、GenVidBench(600万视频规模);图像检测有Celeb-DF++(22种换脸方法、5万+伪造样本);音频检测有MLAAD v9(140小时、51种语言、84个TTS系统)。数据集越来越大,生成器越来越多样,跨域测试越来越严格。
检测器的论文也在不断刷新SOTA。ForgeLens1做到89.41% AUC,Effort做到89.82%,音频检测的EER(等错误率)从早期的20%+降到了4%左右。看起来,我们正在赢得这场军备竞赛。
但问题在于:这些分数到底在测量什么?
Drexel University和Adobe Research的研究人员提出了一个极其简单但一针见血的诊断方法。他们不去发明新的检测器,而是用一个"外行"去考现有的检测器:
不训练任何专用检测模型,只用现成的通用预训练模型(比如V-JEPA2、DINOv3、XLS-R),在上面套一个最简单的线性分类器(linear probe),看能达到什么水平。
如果这个"半路出家"的线性探针,在benchmark上的表现已经能和专门训练了几个月、专门针对深度伪造优化的SOTA检测器不相上下,那就说明:
这个benchmark的大部分"难题",其实早已经被通用模型的表征空间解决了。 检测器刷分,刷的只是"我比通用模型多背了几页笔记",而不是"我掌握了真正的侦察能力"。
用"小学奥数"打败"高考状元"
要理解这个结论有多惊人,你得先明白什么是线性探针。
想象你有一个已经读完了大学所有课程的通才(比如V-JEPA2视频模型)。这个通才看过无数自然视频,理解了运动、物体、场景、光影,但他从来没听说过"深度伪造"这个词,也没看过任何AI生成的假视频。
现在你只需要做一件事:拿他大学四年学的知识,贴一层"试卷答题纸"——就是一个最简单的线性分类器——然后问他:"这段视频是真的还是AI生成的?"
这个"答题器"有多简单?它本质上就是一根直线(二维情况下)或一个平面(高维情况下),把"真"和"假"在特征空间里切开。它不能学习新的特征,不能做复杂的推理,不能理解"为什么假"——它只能做一件事:看通用模型已经encode好的特征里,有没有现成的真假区分信号。
如果这根直线就能把真和假分开,说明什么?
说明真和假本来就已经被分开了。 通用模型在理解"正常视频应该长什么样"的时候,顺便把"假视频看起来不对劲"这件事也编码进了它的特征空间。专用的深度伪造检测器,只不过是在这个已经分开的空间里,又画了一条更精细的线而已。
三个模态,同一个结论
研究团队在三个主流benchmark上做了实验,横跨视频、图像、音频三个模态。他们的实验设计非常严谨:每个模态都用"源域训练、目标域测试"的跨数据集协议,确保检测器不能靠"背答案"拿分。
视频检测(AIGVDBench):
在V-JEPA2模型的第22层,Ridge线性探针达到了88.51%的macro-average AUC。这是什么概念?AIGVDBench论文里列出的10个顶级检测器,最高分是Effort的89.82%,ForgeLens1是89.41%。我们的线性探针超过了其中8个,只比第一名差1.3个百分点。
而且,这个探针用的是V-JEPA2的"默认"预训练权重——没有针对深度伪造做任何微调,没有使用任何时序推理模块,没有见过任何AIGVDBench的训练数据。它就是一个"裸奔"的通用模型 + 一条直线。
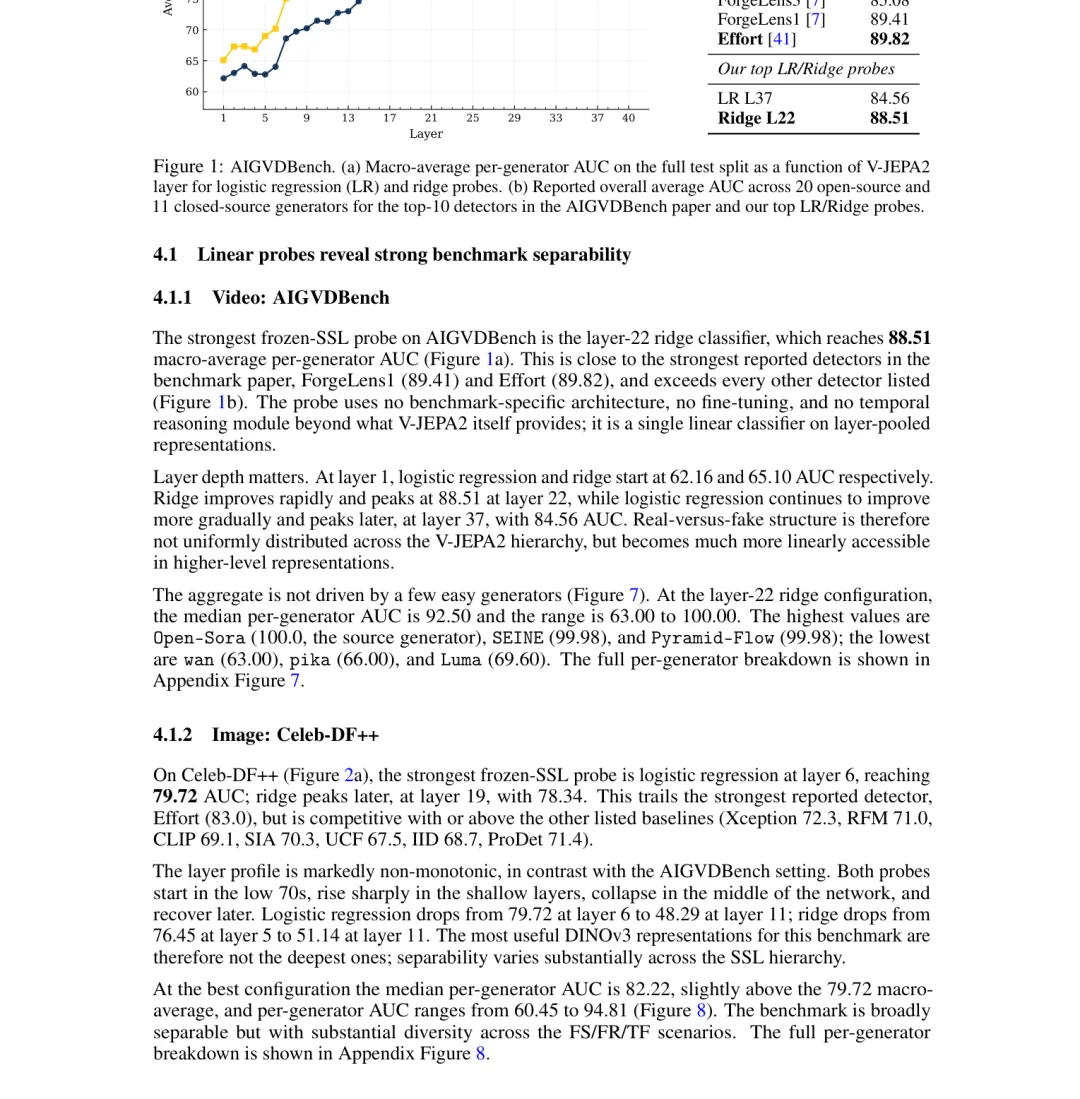
图像检测(Celeb-DF++):
在DINOv3模型的第6层,逻辑回归探针达到79.72% AUC,第19层的Ridge探针达到78.34%。虽然比Effort的83.0%略低,但已经超过了Xception(72.3)、CLIP(69.1)等经典方法。值得注意的是,图像检测的结果呈现出"非单调"特性——不是越深的层越好,而是在浅层(第6层)突然冒出来一个峰值,然后在中间层塌陷,最后在深层又恢复。这说明不同的表示层编码了不同类型的真假区分信号,不是简单堆层数就能解决的。
音频检测(MLAAD v9英文):
在XLS-R模型的第18层,Ridge探针达到88.84%的平均准确率,中位数高达93.1%。在84个TTS系统上,有些系统(WhisperSpeech、facebook_mms-tts-eng、e2-tts)被100%识别,而另一些系统(DeepGram仅39.2%、Microsoft VibeVoice 1.5B仅52.0%)让探针彻底失效。这个巨大的跨度说明:真假可分这件事在通用表征里确实存在,但不同生成器的"可检测性"差异极大。
为什么"认图"和"找假"是两回事?
你可能要问:既然通用模型已经能分清真假了,为什么实际deployed的检测器还会被真·深度伪造骗过去?
这就是论文揭示的第二个关键问题:benchmark里的"假",可能不够真。
研究者用了几何学的方法分析了这个问题。他们不直接看检测器的准确率,而是看每个生成器在特征空间里的"地理位置"。具体来说:
• 把所有真实视频/图片/音频映射到特征空间的一个区域("真巢")
• 把所有已知的AI生成内容映射到另一个区域("假巢")
• 然后看新的、未见过的生成器,离哪个巢更近
他们定义了一个指标 Δ(Delta) = 到真巢的距离 − 到假巢的距离。如果Δ是正数,说明这个生成器离假巢更近,应该容易检测;如果Δ接近0或负数,说明它离真实内容更近,检测器就容易翻车。
结果非常清晰:
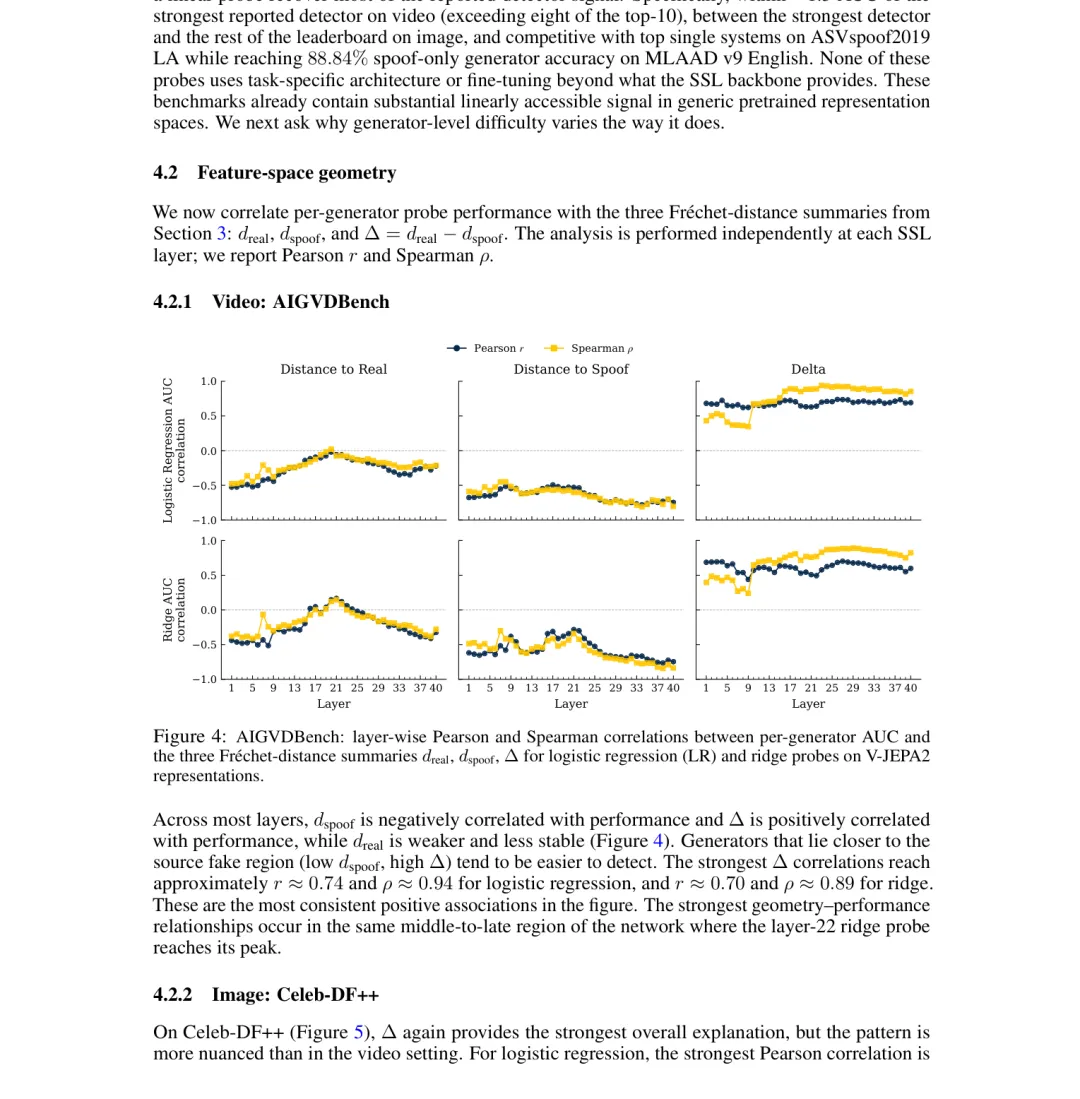
• Δ越大的生成器,越容易被探针检测到(视频领域相关系数r最高达0.74)
• Δ越小(甚至负数)的生成器,越难检测——因为它们"伪装"得太像真实内容了
• 最令人担忧的是:有些生成器之所以"难检测",不是因为技术更先进,而是因为它们在特征空间里恰好贴近了真实分布——这跟"造假水平"无关,跟"考卷出题位置"有关
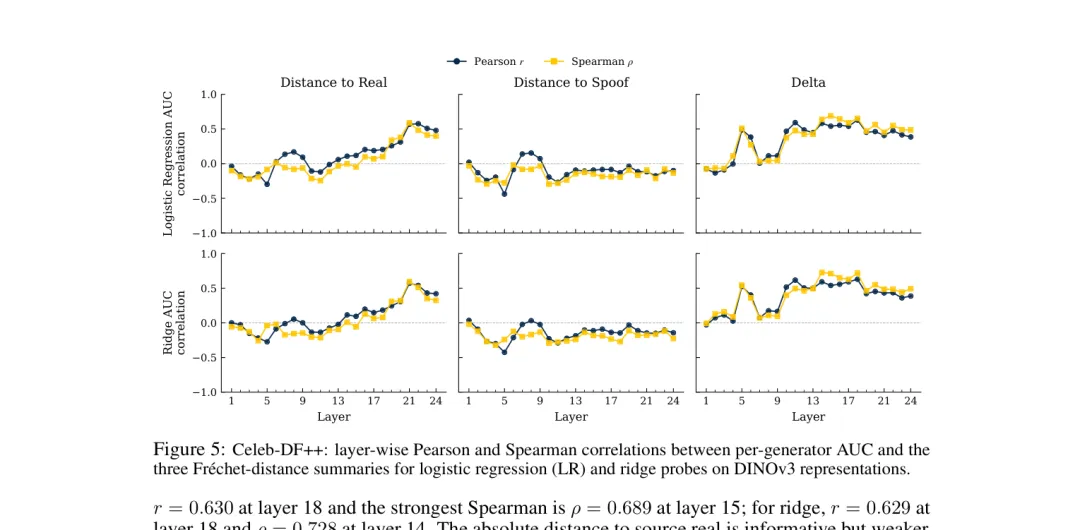
这就暴露了现有benchmark的结构性缺陷:测试集里有些生成器其实是"重复考点"。 比如AIGVDBench里用Open-Sora做训练集,然后测试时Open-Sora的"变体"出现——探针只需要记住"这个分布=fake"就能拿高分,根本不需要理解"什么叫伪造"。更有甚者,某些生成器因为和真实数据在特征空间里重叠,反而成了"送分题"的反面——检测器在这些样本上表现差,不是因为造假技术高,而是因为它们长得太像真的了,连通用模型都分不清。
检测器到底学到了什么?
你可能还会追问:如果线性探针已经这么强了,那专门训练的那些检测器(比如Effort、ForgeLens)到底比探针多学到了什么?
答案是:在大部分benchmark上,它们学到的"额外知识"其实很有限。
论文做了一个更细致的分析:在视频检测中,探针和最强检测器的差距只有1.3个AUC点;在图像检测中差距3.3点;在音频检测中几乎持平。考虑到这些检测器动辄用了数万张伪造样本、复杂的注意力机制、多尺度特征融合,它们花大力气学到的"专家知识",在通用模型的表征空间里已经存在了90%以上。
但这不意味着检测器一无是处。论文明确指出:线性探针的优势恰恰在于它"学不到新东西"——它只能挖掘通用模型已经编码的信号。如果某个检测器在探针基础上还有显著提升,那说明它确实学到了一些通用模型没捕捉到的forensic特征。 问题是,目前很少有检测器能做到这一点。
更关键的是,论文揭示了一个"天花板效应":当探针已经接近SOTA时,我们其实无法判断检测器是真的更聪明,还是只是在通用模型的基础上做了一点微小的优化。要证明一个检测器真的有效,应该先证明它能在探针达不到的地方表现出色——而不是在探针已经解决的问题上刷分。
检测器的"皇帝新衣"
综合三个模态的结果,论文给出了一个振聋发聩的结论:
当一个benchmark能被一个线性探针解决大部分问题时,这个benchmark测量的就不再是"forensic understanding(取证理解力)",而是"general modality understanding(通用模态理解力)"。
翻译成大白话就是:
你考的不是"侦探能力",考的是"视力好不好"。
一个视力5.0的人,不需要学过刑侦,也能一眼看出两张照片的光影不一致。但这不意味着他能当法医——当伪造技术进化到连光线、纹理、时序都完美模拟时,视力再好也没用。
现在的深度伪造检测benchmark,恰恰卡在这个尴尬的中间地带:它们测试的"假",还停留在"视力测试"的层面,还没进化到"刑侦测试"的层面。 检测器可以因为"这串文本的字体间距不太对"而识别假文档,但一旦伪造者把间距也模仿到完美,同样的检测器就会彻底失效。
对普通人意味着什么?
第一,不要迷信检测器的"准确率"。
你现在看到的各种AI内容检测工具、平台、API,报出来的99%准确率,很可能是在某种特定benchmark上刷出来的。如果换一批生成器,或者遇到更逼真的伪造,这些数字可能会断崖式下跌。下次再看到"AI检测准确率99%"的宣传,记得问一句:"在什么测试集上?换了生成器还准吗?"
举个例子:一个在Celeb-DF++上表现优异的检测器,换到另一个包含全新换脸方法的测试集上,AUC可能直接掉到60%以下。这不是检测器没用,而是"在已知题型上拿高分"和"能解决未知难题"是两回事。 普通用户能做的,就是保持怀疑——任何声称"万能检测"的产品,都值得打一个问号。
第二,换脸检测的军备竞赛,可能打错了方向。
研究团队建议:在构造新的benchmark时,应该先跑一遍线性探针。如果一个简单的线性分类器就能在某个benchmark上拿到80分以上,那这个benchmark可能从根本上就不适合用来衡量"真正的鉴别能力"。 更好的benchmark应该包含那些让通用模型也束手无策的、真正 novel 的生成方式——比如更注重"现实世界威胁模型"而不是"生成器覆盖数量"。
这就像武术比赛:如果一套动作(线性探针)就能拿80分,那说明这个比赛的评分标准有问题——它可能偏向"动作好看"而不是"实战有用"。真正的实战测试,应该用那些连"武术大师"都难以应对的突发招式。
第三,"通用模型已经知道了",其实是好消息。
这意味着我们不需要从零开始训练专门的深度伪造检测器。现有的通用视觉/音频模型(V-JEPA2、DINOv3、XLS-R)已经编码了丰富的真伪区分信号。下一步不是堆更复杂的检测架构,而是设计更好的测试方法,去挖掘这些通用模型里还没被利用的那部分鉴别能力。
对行业来说,这意味着下一波突破可能不在"检测器本身",而在"如何让通用模型更主动地暴露它已经知道的真假区别"。也许未来的深度伪造防御,不是一个个独立的检测APP,而是集成在视频通话软件、社交媒体平台、甚至相机硬件里的"通用感知层"——在你拍摄或浏览的每一帧画面里,quietly运行着来自V-JEPA2或DINOv3的"真假嗅觉"。
最后说一句
这篇论文最可贵的地方,不是它又提出了一个"更先进的检测方法",而是它敢于质疑整个评估体系。
在AI领域,我们太容易陷入"刷分竞赛"了。检测器的AUC从70涨到90,我们会欢呼雀跃;但很少有人停下来问:这个分数有没有意义?
这篇论文提醒我们:在庆祝SOTA之前,先看看这个SOTA是不是一条直线就能达到的。 如果答案是肯定的,那可能不是检测器太强,而是考试太简单。
深度伪造的威胁是真实的,但我们的应对方式可能需要一次反思。不是更多的检测器,而是更好的测试;不是更高的分数,而是更深的洞察。
这才是"审计"的意义——不是否定检测器的价值,而是帮我们看清,我们到底在测量什么,以及我们以为在测量什么。
论文信息
标题: What Do Deepfake Benchmarks Measure? An Audit Using Frozen Self-Supervised Representations
作者: Samuel Pagon, Yixuan Shen, Vishal Asnani, Feng Liu
机构: Drexel University, Adobe Research
链接: https://arxiv.org/abs/2606.26384
(本文基于2026年6月发表于arXiv的研究论文撰写,实验数据均来自原文。如需了解更多技术细节,可查阅论文原文Section 3-4。)
