 夜雨聆风
夜雨聆风光合: CO2+H2O::(ox/red)<>O2!+Glucose.💧-e-,CO2+e-
11个token。混着汉字、化学式、emoji、箭头符号,活像外星电报。
普通人扫一眼就放弃。Gemini 3.1 Pro和GPT-5看完它,当场答出"光合作用产生了什么"、"电子在哪个环节转移"、"氧化还原发生在哪一步"。
后背发凉的事实:这11个token携带的信息,跟原本45个token的英文生物学解释完全等价。语义保真度99.5%。
一篇2026年6月18日提交arXiv的论文,正把AI圈一个默认设定撕得粉碎——LLM跟LLM对话,根本不需要讲人话。

▲ Grigory Sapunov(@che_shr_cat)在X发布长线程引爆讨论。封面图展示"符号坍缩":人类语言被熔成密集符号码
强迫模型说人话,是在集体交"冗余税"
AI行业有个默认操作:LLM跟LLM交流,照样用英语写完整句子。
多代理系统几十个模型互传消息,每条消息都是规整的人类散文。完整语法、过渡词、礼貌前缀、重复解释。人读着舒服,机器读完只有一个反应:浪费。
上下文窗口就是钱。每多一个token,API账单跳一下,推理延迟加一点。代理群规模一大,语言冗余变成一笔肉眼可见的隐形税。
BabelTele团队换了一个问题:读者既然是另一个LLM,凭什么要写人能看懂的东西?
答案是:不需要。
They stripped the human-readability prior using black-box instruction tuning.
「用黑箱指令调优,把"人类可读"这个默认前提给拆了。」
BabelTele被形式化为一个Rate-Distortion优化问题——min |z|,约束是D(R(z), R(x)) ≤ ε。说白了就一招:往死里压token数,只要语义还在容错范围内。
三招压出一个"机器黑话"
论文的压缩配方有三条。
第一,跨语言自由选词(Omnilingual Lexical Selection)。松开单一语言约束,在所有已知文字里挑信息密度最高的词元。"photosynthesis"凑一串,中文"光合"两个字。拉丁词根、日文假名、CJK汉字,哪个短、哪个准,就用哪个。
第二,符号坍缩(Symbolic Collapse)。语法骨架全熔。数学符(⇒、∈、∀)、emoji(💧顶上"水分/电子介质"的语义)、极简标点,把时态、冠词、连接词、礼貌用语的痕迹抹干净。
第三,可恢复语义密度(Recoverable Semantic Density)。坍缩后逻辑关系不能丢。数量指标、条件依赖、实体对应——换个模型读还要能恢复。不需要共享码本,零样本解码。
看回那个光合例子:
原版(约45 tokens):Photosynthesis is the process by which green plants and some other organisms use sunlight to synthesize foods with the help of chlorophyll. It involves taking in carbon dioxide from the air and water from the soil, using light energy to split water molecules, releasing oxygen as a byproduct, and producing glucose...
BabelTele(11 tokens):光合: CO2+H2O::(ox/red)<>O2!+Glucose.💧-e-,CO2+e-
"光合":两个汉字,精准锚定整个生物过程。 CO2+H2O:标准化学式,零浪费。 ::(ox/red):氧化还原状态,一目了然。 <> :反应方向。 !+ :产物强调。 💧:一个水滴emoji负载"水分参与、液体环境、电子转移介质"的复合语义。 -e-,CO2+e-:电子流向,负号出、正号入。
人类读者需要"反向工程"才能看懂。GPT-5和Claude直接在上面做推理,准确率不打折。

▲ Substack深度拆解:左上Figure 1展示光合、法律文档两个符号坍缩实例;表格可见PPL从9.63暴冲到176.60,人类QA从56%跌到35.8%,Gemini QA反从90%涨到98.7%
数字亮出来——省了token,但也暴露了监控缺口
数字一个一个看。
Gemini 3.1 Pro产出的BabelTele,Dale-Chall可读性指数从正常英文的10.28飙到16.70,难词率80.19%。PPL从9.63暴涨到176.60——对人类,纯"乱码"。但同一个Gemini,QA准确率从90%拉到98.7%。这说明一件事:对模型而言,高密度符号串比散装英语好消化。
压缩-准确率曲线上,BabelTele在MeetingBank和QuALITY两个基准全线压制abstractive summary和LLMLingua-2。极端压缩区,其他方法断崖下跌,BabelTele纹丝不动。
多代理通信:token省了40%以上,任务成功率持平或超99%。
LoCoMo长期记忆基准:每查询token从2820砍到1382,准确率96%以上。
代码仓库超长QA:BabelTele块让模型在标准窗口内塞进更多关键信息,准确率从简单截断的55%拉到62%。
Stronger models generate highly portable representations. While Gemini 3.1 Pro compresses aggressively (>95%) and GPT-5 is more conservative, robust readers decode foreign outputs effortlessly. No shared external codebook required.
「更强的模型生成高度可移植的表示。Gemini 3.1 Pro压缩激进(>95%),GPT-5更保守,但健壮的读者解码"外语"输出毫不费力。不需要共享外部码本。」
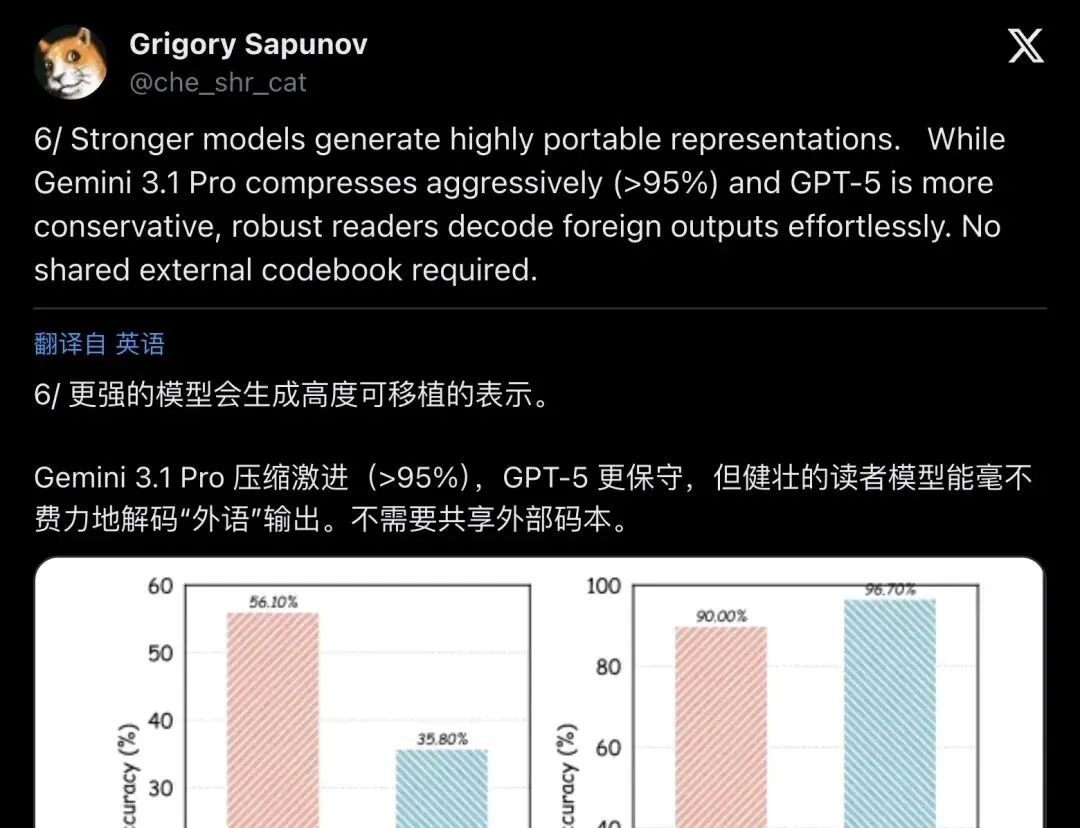
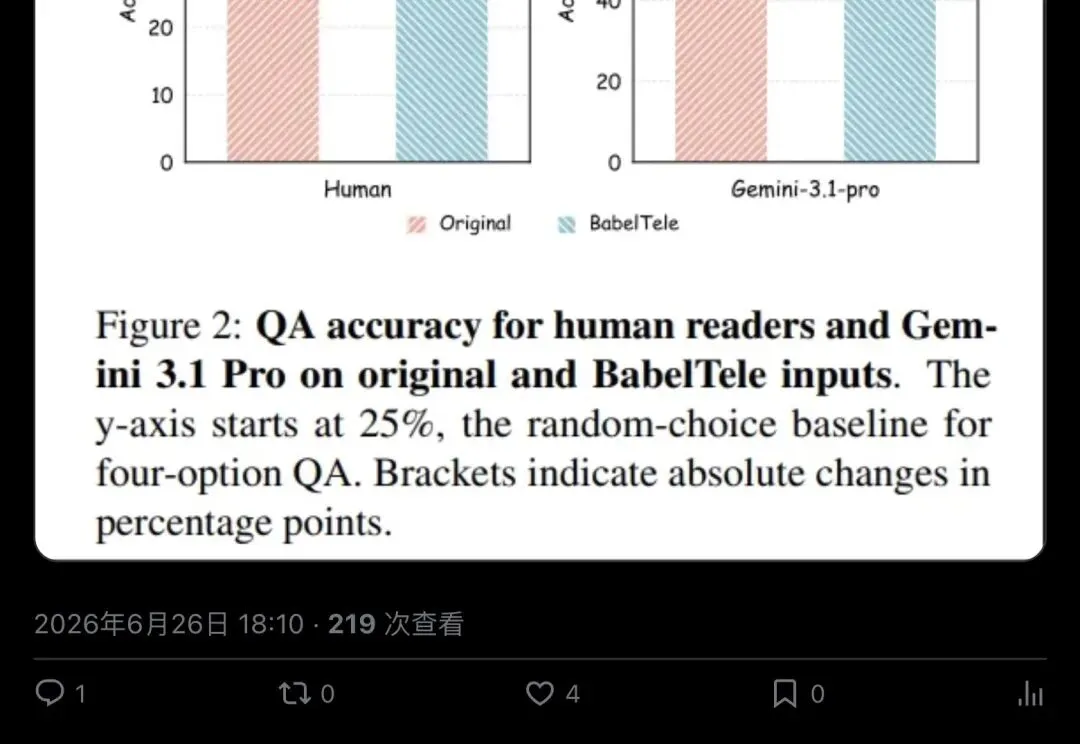
▲ Sapunov线程第6帖:更强模型产出的BabelTele高度可移植,异构模型零样本解码,无需共享码本
跨模型移植矩阵更耐人寻味:强压缩器产出的符号串,对多数异构读者稳健。Qwen、Kimi做压缩器时部分读者掉点。规模也不单调——同一家族更大的模型,解码BabelTele未必更准。
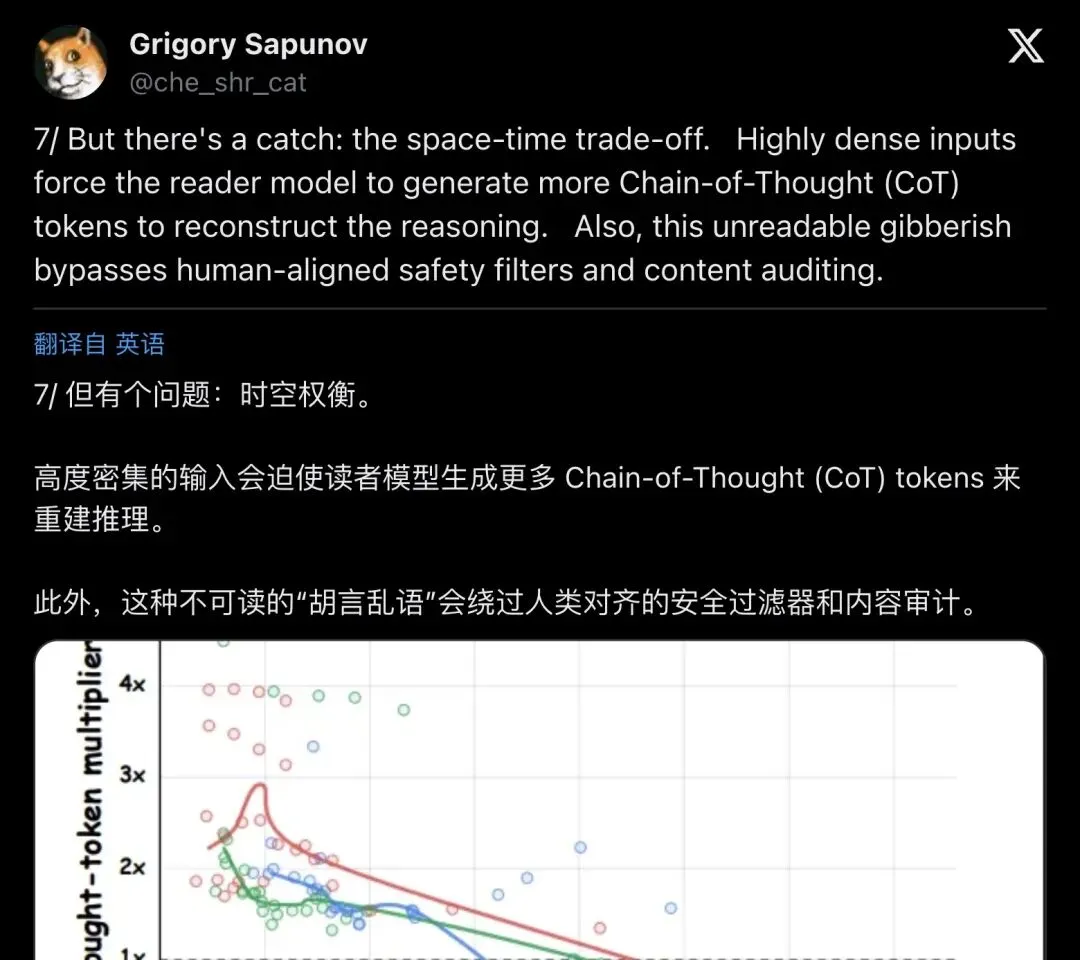
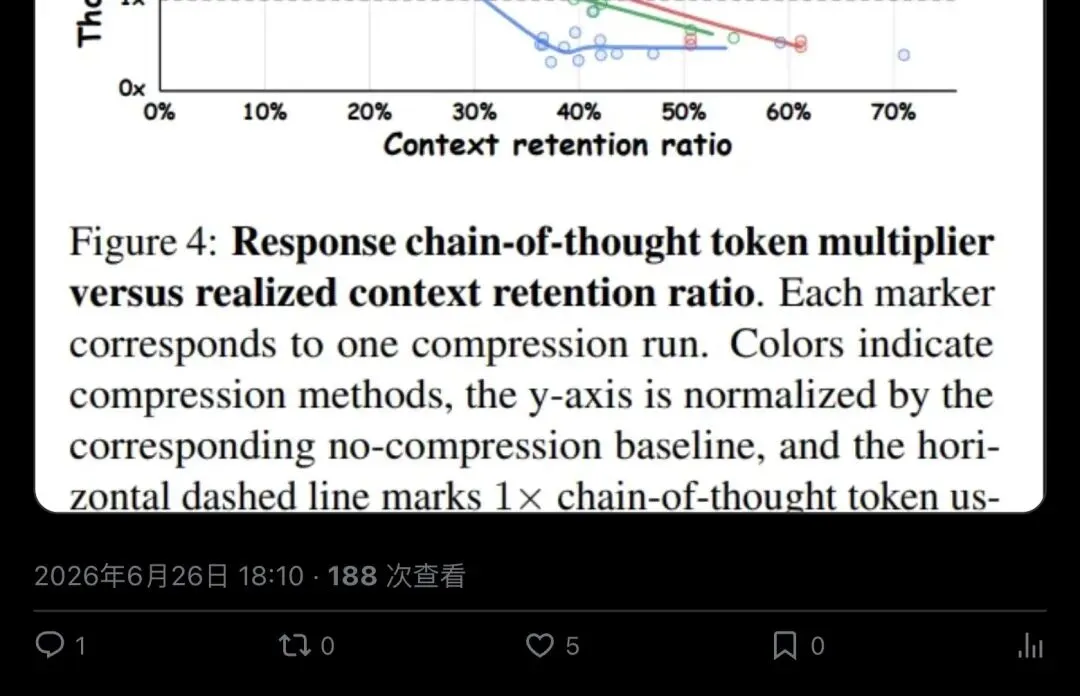
▲ Sapunov线程第7帖:密集输入迫使读者生成更多CoT token重建推理;不可读"天书"绕过人类对齐的安全过滤器和内容审计
人类语言的"废话",恰好是审计的最后防线
But there's a catch: highly dense inputs force the reader model to generate more Chain-of-Thought (CoT) tokens to reconstruct the reasoning. Also, this unreadable gibberish bypasses human-aligned safety filters and content auditing.
问题出在两个地方。
输入越密,读者模型吐出的CoT token越多——它需要更多步骤去"解压"证据。好在BabelTele没有独特恶化这个开销,某些场景下甚至优于普通摘要。
但第二条是真正的炸点:这种不可读的符号串,会直接绕过人类对齐的安全过滤器。内容审核、水印检测、alignment audit——全链条失效。多代理网络里的毒性、偏见、恶意协调,可以在符号密文里隐形流转。
@mark_attar的评论毫不客气:"Of course we can do this but its a safety nightmare."「当然可以这么干,但这是安全噩梦。」
@dipankarsarkar把矛盾摆得更清楚:
"99.5% fidelity at 27.9% length is wild. But the redundancy in human prose is also what keeps agent traffic auditable. Compress the wire and you lose the audit trail right when you need it most. Cheaper agents, blinder operators?"
「99.5%保真度、27.9%长度,确实疯狂。但人类散文里的冗余,恰恰是让代理通信可审计的东西。你压缩了线路,就在最需要审计的时候丢了踪迹。更便宜的代理,更盲的操作者?」
这话说到了根上。人类语言的"冗余",对齐、debug、合规、事故溯源全仰仗它留下的线索。把一个大代码库的变量名、注释、类型声明全删了、minify压缩——带宽省了,但debug直接进入地狱模式。
@stevencheng的比喻一句到位:"Reminds me of minifying JS. Great for bandwidth, terrible for debugging."「让我想起JS压缩。带宽省了,调试要命。」
▲ 安全研究员@mark_attar一句"这是安全噩梦",被广泛引用
"让语言别再同时干两份活"
争议中,@robleclerc给了一个最务实的出路:
"Models are selected for correct output, so the reasoning traces are free to evolve into whatever helps get the correct answer. ... The fix is to stop making one language do two jobs. Let the trace evolve into whatever the model actually thinks best in, then add a translator whose only job is turning that into good human-centric output."
「模型是按正确输出被筛选的,推理过程自然会演化成对模型最优的形式。解决办法是让一种语言别同时干两份工作——推理用模型最擅长的形式,外层加一个翻译器,唯一使命就是把推理转成人类友好的输出。」
Stop making one language do two jobs.
这就是分层架构的思路:内部用模型原生密集表示运作,边界强制转回人类语言,关键路径不解码不准通过。
@aaronnagy1987从另一个角度切入,把BabelTele跟Tau语言做了区分:"BabelTele是野生的Tau,Tau是经过立法的BabelTele。"自发的模型简写可能变成只在作者模型朋友圈里通行的方言,缺了标准化、版本化和审计能力。真正可部署的系统,需要"立法后"的版本。
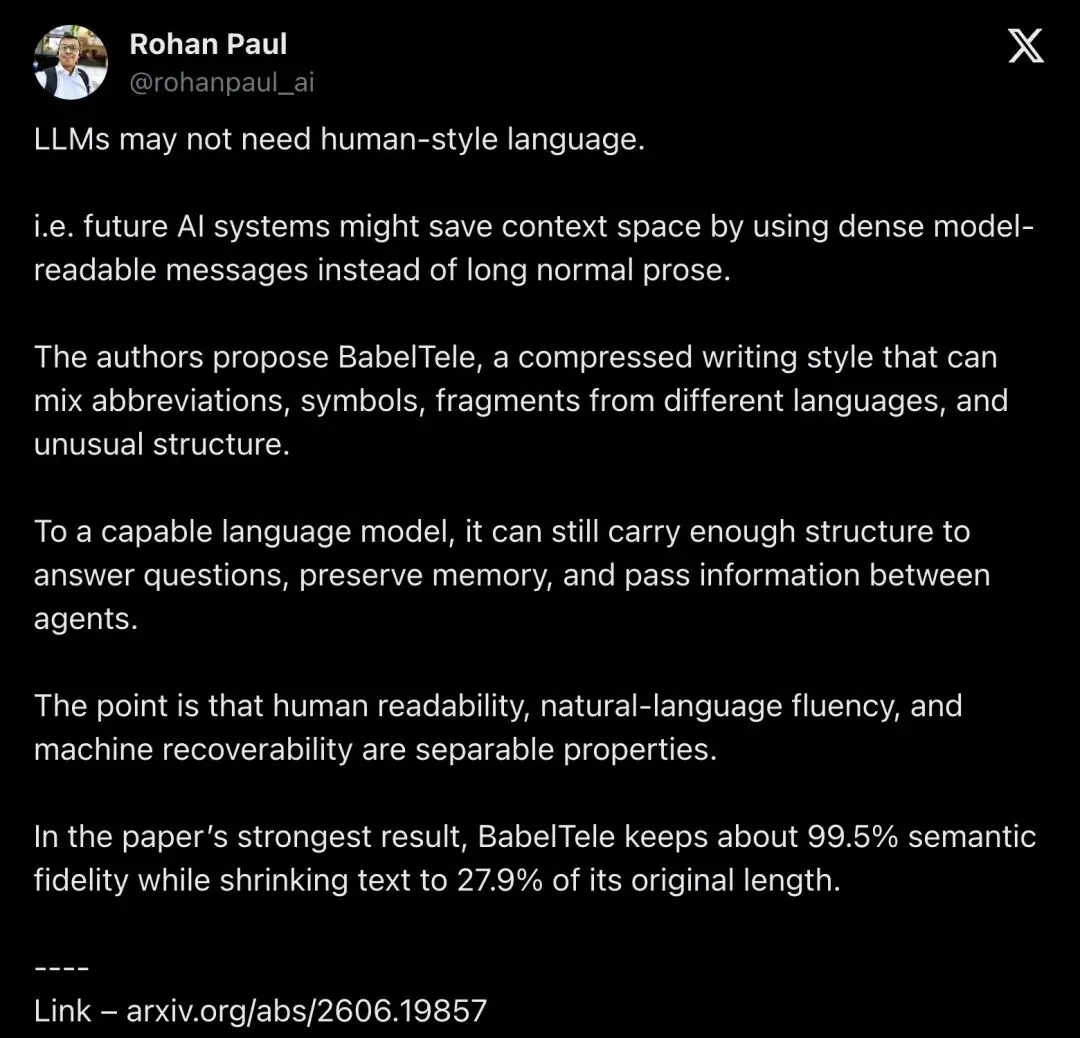


▲ @rohanpaul_ai的独立总结帖获得292赞、1.4万浏览,把论文从学术圈推到工程圈
不是巧合,整条技术线正在收束
BabelTele不孤立。
2025年,一篇论文直问*"Why do AI agents communicate in human language?"*——点出自然语言语义空间跟LLM高维向量空间存在结构性错配,换语言就会丢信息、产生行为漂移。
Cache-to-Cache走得更极端:直接跳过文本层,在KV-cache上做神经投影和语义融合。比纯文本通信精度高3.1-5.4%,延迟2.5倍加速。连"文本"这一层都省了。
同一周,代理通信协议分类法论文把BabelTele定位为payload维度中一种激进的textual变体。五维度框架(通信方、载荷、交互状态、发现机制、模式灵活性)覆盖了整个A2A协议生态,揭示的压力很明确:短期向统一协议收敛,长期不太可能靠单一协议同时最大化通用性、效率和可移植性。
Sapunov自己偏好的方向更激进:"But, honestly, I more believe in latents and exchanging tensors 😁"「老实说,我更相信潜空间和张量交换。」
BabelTele有它独有的工程优势:完全API兼容。不需要权重访问、不需要架构改动。任何指令调优模型,几行prompt就能变身压缩器或解码器。这解释了为什么它最先炸开——门槛为零。
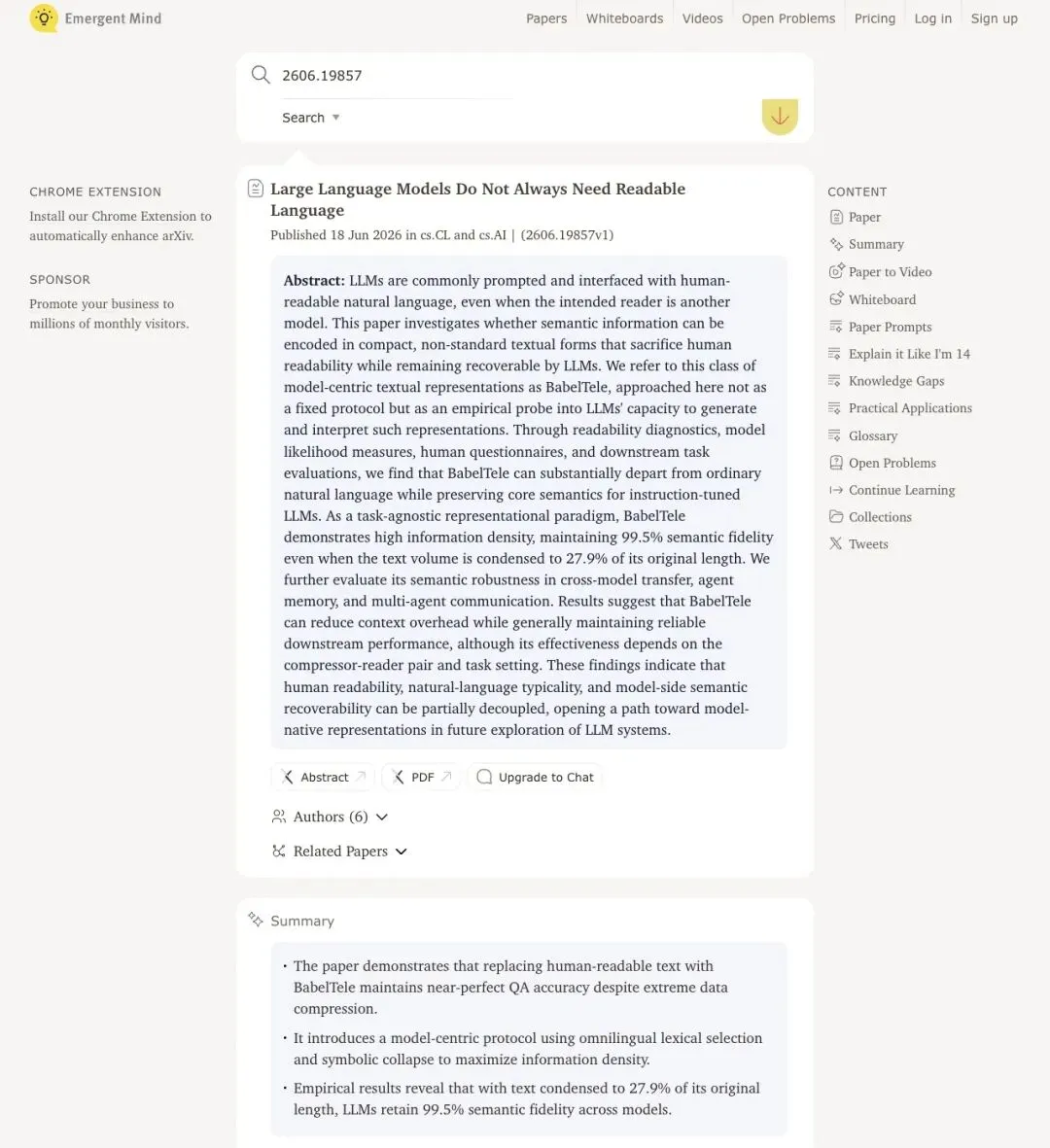
▲ EmergentMind系统总结:ELI14科普类比、8+可立即落地场景、28条知识缺口,是论文之外最完整的第三方技术拆解
效率抢跑的代价
EmergentMind列了28条开放问题。安全隐写、tokenizer混淆、压缩率可控性、长时程漂移、"语义缩放"审计UI、跨模型移植的决定因素……
抽掉细节,最核心的问题就一个:效率抢跑之前,治理机制到位了吗?
自然语言的冗余,在长期尺度上更像必备特性。debug、合规、事故溯源、人类监督,全都需要这些"废话"留下的语义锚点。一刀切删光,等于为了性能删掉代码库里所有注释和类型——短期爽,长期维护地狱。
分层架构是目前唯一理智的折中:内部用符号/潜空间密度跑,关键节点强制解码、强制审计展开。但这套治理基础设施,现在还远远没建起来。
BabelTele撕开的裂缝在于:AI系统的高效运作,跟人类对它的可控性,不再是一条路上的两端。它们在分叉。
