 夜雨聆风
夜雨聆风先问你一个问题。
你想做AI短视频,或者AI漫剧,第一个想到的工具是什么?
大概率是即梦、可灵、通义万相,或者剪映的AI功能。这些都能做些东西,但有两个问题:第一,每个工具只管一块,做图的管不了视频,做视频的管不了音频;第二,免费的有限额,想做多就得开会员。
有没有一个工具,画图、做视频、做3D、生成背景音乐,全在一个软件里完成,而且完全不收费?
而且现在抖音很多做视频的都在用它。
它就是ComfyUI。
GitHub上118,552颗星,全球AI创作者几乎人手一个。
一、用它能做什么——先说视频和漫剧
漫剧怎么做的?传统流程:画师画出角色立绘和关键帧,后期加对话框、配音、音效、镜头推拉。一条几分钟的漫剧,从画到剪可能要一个星期。
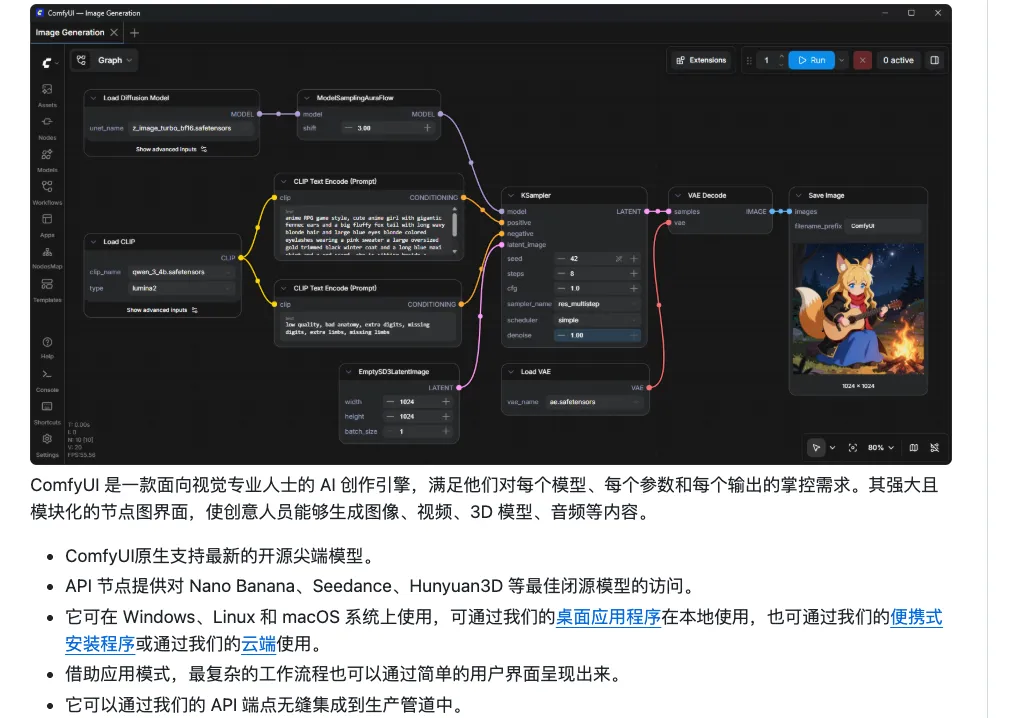
有了ComfyUI之后,流程变成什么样:
第一步,生成角色。输入描述词:比如"黑发少年,古装,侧脸,写实转漫改风格",出图。想保证角色每张图长得一样,用IP-Adapter或者InstantID节点锁定面部特征。同一个角色在所有图里都是同一张脸,不会变来变去。
第二步,生成场景:古风庭院、市井街道、竹林深处——同样输入描述,批量出图。风格用同一个模型,画面统一。
第三步,图转视频:这是最关键的一步。把静态的画面接进Wan 2.1或者Hunyuan Video节点,镜头可以推拉摇移,角色眼珠会转,头发衣摆会飘。两三秒的动态片段,拼起来就是一条漫剧。
第四步,背景音乐:用Stable Audio节点,输入"古风、悠远、箫声",生成一段配乐。直接用。
以上四步,在一个软件里完成。不用切换即梦、可灵、剪映、网易云音效库。一条线从头串到尾。
抖音短视频呢?
同样是图片转视频。想做产品展示?拍一张产品图,接视频节点,自动生成动态环绕镜头。想做知识口播?生成背景画面,接动态效果节点。
想做带货视频?全流程一样:AI生成产品场景图 → 图转视频 → AI生成BGM → 导出。
图、视频、音频、3D,全能做
ComfyUI不是"画图的",也不是"做视频的"。它是一个全能控制台。
图片生成——Flux、SD3、混元图像、Qwen Image,主流模型全支持。风格从商业海报到二次元到真人写实都能做。
视频生成——Wan 2.1、Hunyuan Video,一段描述出几秒视频,支持镜头控制。
3D模型生成——Hunyuan3D 2.0,描述出3D模型,导出就能用。
音频生成——Stable Audio,文字出音乐和音效。
图片编辑——换背景、超分辨率放大、老照片修复、风格迁移。
一个软件,全部管完。
二、ComfyUI难不难学
说句实话,ComfyUI的界面第一次打开会懵——不是Midjourney那种输入框+按钮,是一块空白画布,上面什么都没有。
但它的逻辑异常简单:把积木连起来。
一个节点是一个功能。拖"加载模型"节点 → 接"输入提示词"节点 → 接"生成图像"节点,用线连起来,点运行——出来了。
想加视频?加个视频生成节点。想固定角色长相?加个人脸锁定节点。想给老照片超分放大?加个放大节点。
听起来多,其实就是一个连线的过程。连完了保存成工作流,下次一键加载。
而且你不用从零搭。comfy.org/workflows上有成千上万个别人分享的工作流,下载导入直接用。B站搜"ComfyUI工作流"、"ComfyUI漫剧"、"ComfyUI抖音",中文教程一大把,手把手教。
三、ComfyUI怎么装
现在的版本和装普通软件一样简单:
去 comfy.org/download,下载桌面版。Mac和Windows都有。安装后打开,内置模型管理器,搜模型、下载、切换全部在界面里操作。不用碰命令行。
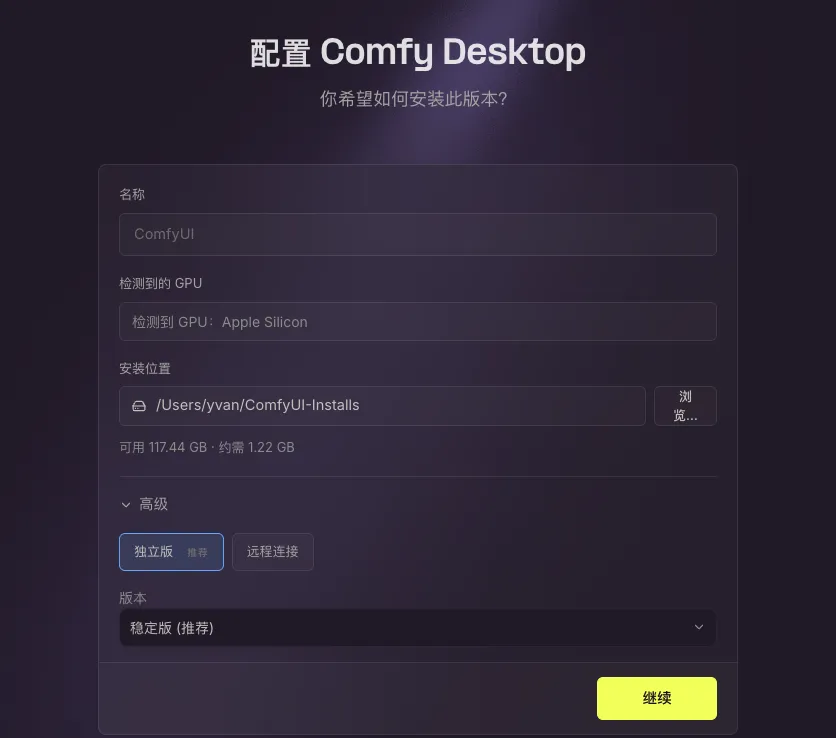
显卡不够?支持低显存模式,1GB显存的老卡也能跑。实在没显卡,Comfy Cloud按量付费,不用买硬件。
全部免费
ComfyUI开源、桌面版免费、模型免费。没有月费,没有会员。唯一花钱的地方是如果你用云计算——那是给云服务商的,不是给ComfyUI的。
桌面版下载:comfy.org/download
工作流模板:comfy.org/workflows
B站搜"ComfyUI教程",中文内容多多。
一句话总结:如果你想用AI做抖音短视频或者漫剧,这个工具一个就够了。118K星,免费开源。
你有想过用AI做短视频或漫剧吗?目前在用什么工具?评论区聊聊。
关注我,获取AI精彩内容!
更多内容请移步:https://github.com/comfyanonymous/ComfyUI
