 夜雨聆风
夜雨聆风
😩 真实痛点:代码可读性的三大惨案
惨案 1:新人入职迷路
新人入职第一天,打开项目代码。500 个文件,3 个 README,其中两个过期。问同事「这段代码为什么这么写」,同事说「我也不知道,上一个人写的」。
代码能跑,但没人知道为什么这么写。
惨案 2:文档永远过期
你写了一篇漂亮的架构文档,配了流程图和时序图。三个月后重构了两次,文档没更新。现在文档和代码完全是两个系统,新人按文档操作直接翻车。
文档和代码永远不同步,不同步的文档比没有文档更危险。
惨案 3:Code Review 靠猜
Code Review 时看到一个 200 行的函数,没有任何注释。你花了 40 分钟才理解它在做什么。Review 完写了一段评论,作者回复:「这个函数的逻辑在 wiki 第 47 页有说明」。
代码和文档是两个世界,理解代码的成本比写代码还高。
📊 数据暴击:代码阅读的时间远超编写
研究数据表明:开发者 70% 的时间在读代码,不是写代码。
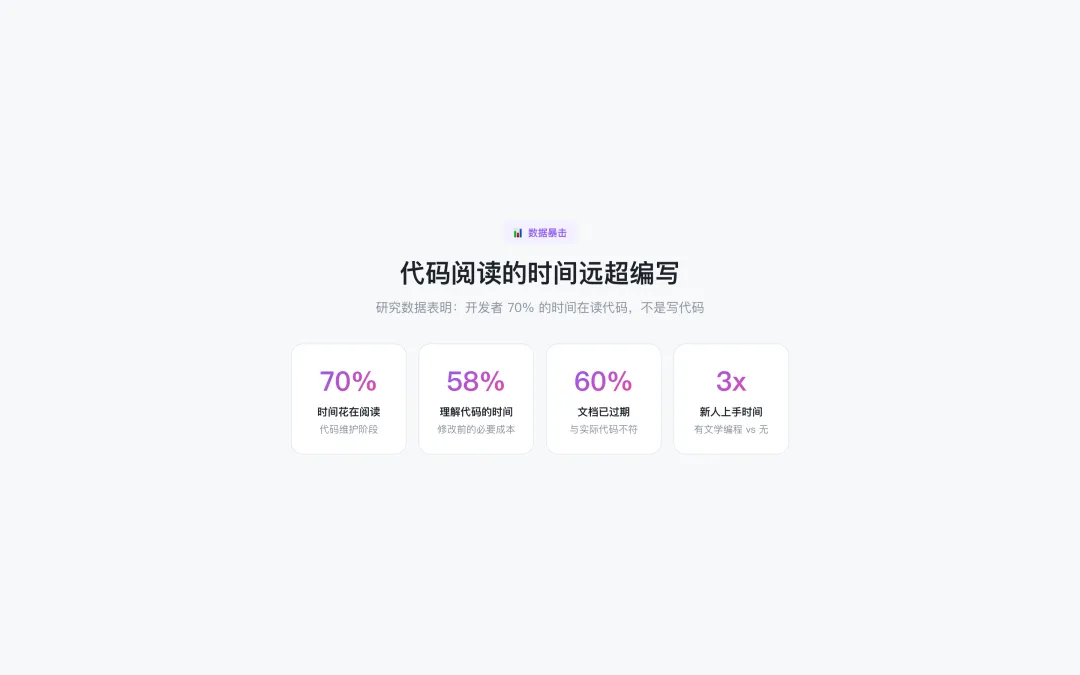
• 70% 的时间花在阅读代码(代码维护阶段)
• 58% 的修改时间用于理解代码(修改前的必要成本)
• 60% 的文档已过期(与实际代码不符)
• 3x 新人上手时间差异(有文学编程 vs 无)
💡 转折
如果代码本身就是文档呢?
Knuth 在 1984 年说:「程序应该写成给人类读的散文,顺便让机器执行。」40 年后,AI Agent 终于让这个梦想变成了现实。
Litprog Skill 是一个 Claude Code Skill,能把你的整个代码库变成一篇「文学编程」文档。一个 .lit.md 文件 = 散文叙述 + 代码块 + Mermaid 图表,按「人类最容易理解的顺序」组织,而不是编译器要求的顺序。
⚡ 效果对比:传统代码 vs 文学编程
左边是传统代码的日常,右边是文学编程的解决方案。核心差异在于:单一真相源。

传统方式下,代码、README、Wiki 三处独立维护,永远不同步。文学编程只有一个 .lit.md 文件,散文就是文档,代码变了文档自动跟着变。
🚀 6 大核心能力
不只是「给代码加注释」,是一整套文学编程生产线:
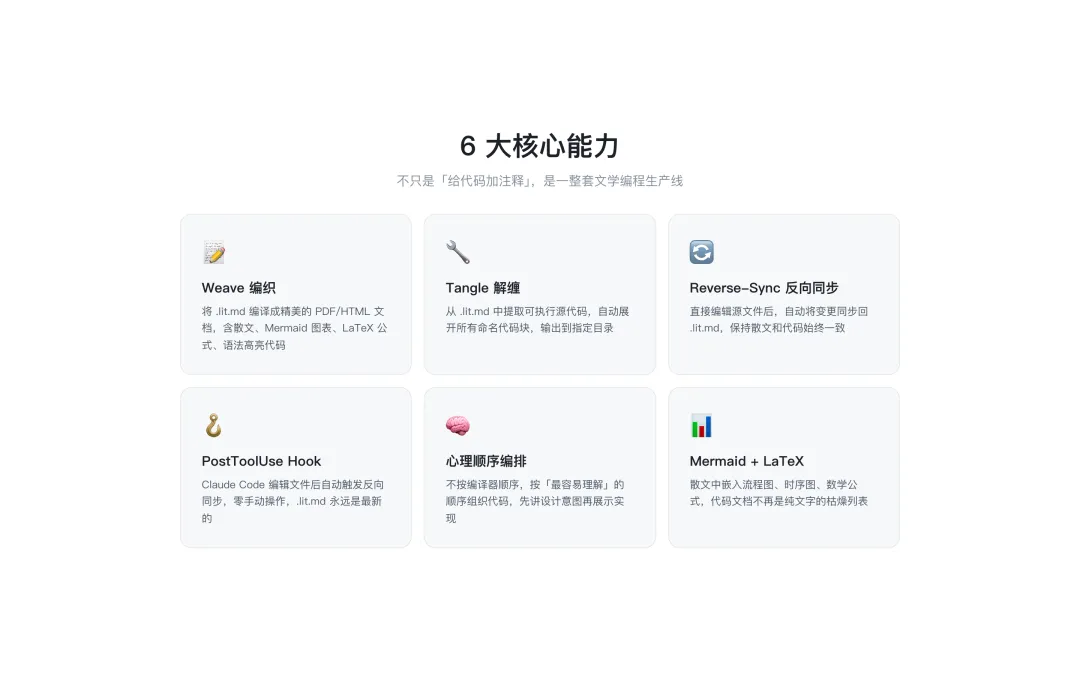
1. Weave 编织 —— 将 .lit.md 编译成精美的 PDF/HTML 文档,含散文、Mermaid 图表、LaTeX 公式、语法高亮代码
2. Tangle 解缠 —— 从 .lit.md 中提取可执行源代码,自动展开所有命名代码块
3. Reverse-Sync 反向同步 —— 直接编辑源文件后,自动将变更同步回 .lit.md
4. PostToolUse Hook —— Claude Code 编辑文件后自动触发反向同步,零手动操作
5. 心理顺序编排 —— 按「最容易理解」的顺序组织代码,先讲设计意图再展示实现
6. Mermaid + LaTeX —— 散文中嵌入流程图、时序图、数学公式
🔄 完整工作流
从代码库到精美文档,全程 AI Agent 自动化,三步搞定:
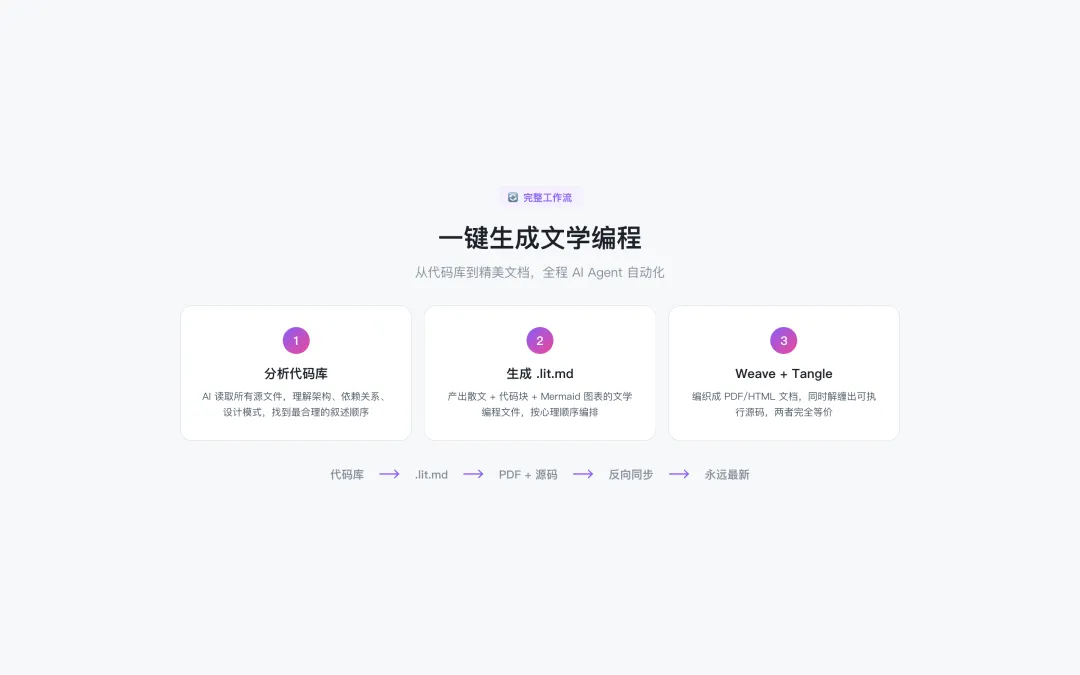
1. 分析代码库 —— AI 读取所有源文件,理解架构和依赖关系
2. 生成 .lit.md —— 产出散文 + 代码块 + 图表的文学编程文件
3. Weave + Tangle —— 编织成 PDF 文档,同时解缠出可执行源码
📦 安装方法
Claude Code:
# 复制 SKILL.md 到项目的 .claude/skills/ 目录
git clone https://github.com/tlehman/litprog-skill.git
cp litprog-skill/SKILL.md your-project/.claude/skills/literate-programming.md
安装后在 Claude Code 中输入 /literate-programming 即可使用。
Codex:
npx skills add tlehman/litprog-skill
安装后在 Codex 会话中自动可用。
Hermes:
hermes skills install tlehman/litprog-skill
或手动 clone 到 ~/.hermes/skills/ 目录。
✅ 立即行动清单
1. 选一个项目 —— 挑一个你最熟悉的代码库,最好是中等规模(5000-50000 行)
2. 安装 Litprog Skill —— 一行命令搞定,支持 Claude Code / Codex / Hermes
3. 运行 /literate-programming —— 让 AI 分析代码库,自动生成 .lit.md 文件
4. 生成 PDF 文档 —— 用 Pandoc 编译成精美的 PDF,含图表和公式,给团队分享
5. 体验反向同步 —— 直接改源文件,.lit.md 自动更新,从此告别「文档过期」
