 夜雨聆风
夜雨聆风你每天用AI,但它为什么总在一本正经地胡说八道?
最近帮一个朋友排查了一个很无语的情况。
她让AI帮她查公司的差旅报销上限,AI给了一个非常像样的回答,格式规整,数字清楚,还带了「根据公司规定」这几个字。朋友照着报了账,结果财务打回来了。那条规定根本不存在。
我看了她截图,AI的回答真的很「专业」,专业到你完全想不到那是编的。
这不是个例。
我自己也踩过,让Claude帮我确认某个SDK的函数参数,它给了一个自信满满的解释。我信了,直接用进去,跑起来报错了,去翻文档才发现,那个参数根本不是那个意思。
这个现象有个名字,叫幻觉(Hallucination)。但我觉得光知道这个名词没用,你得搞清楚它为什么会发生,才知道怎么防它、怎么绕它。
今天从头说清楚,顺便把最近很多人在聊的RAG讲明白。

我把这个内容也做成了视频版,动画演示会更直观,在主页可以找到。
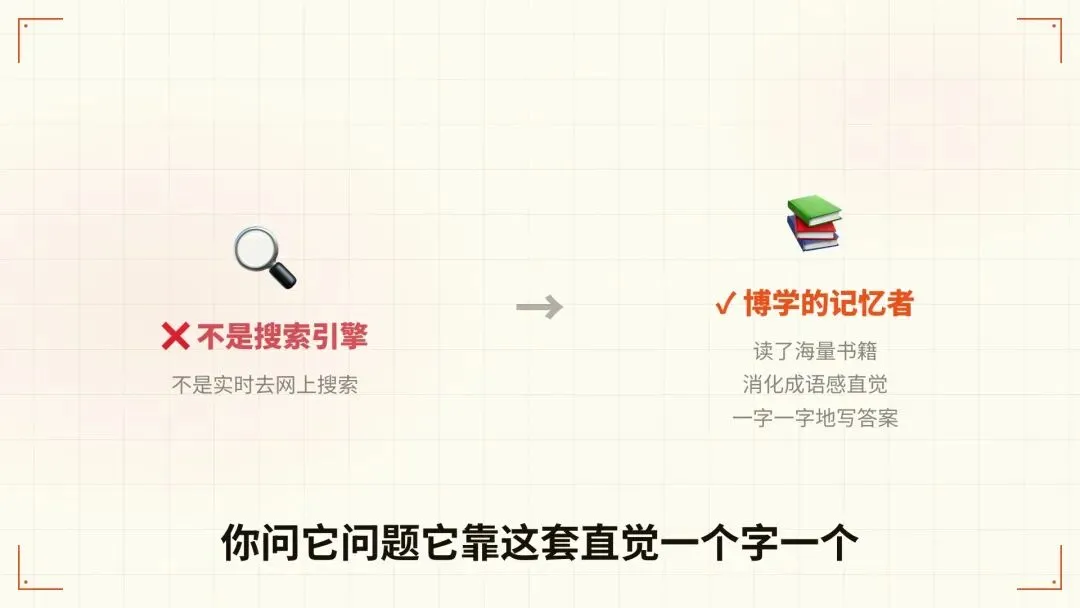
你可能以为,AI回答问题是去网上实时搜索的,像一个更智能的百度。
不是的。
AI的工作方式更像一个读了非常多书的人,靠脑子里的记忆来回答你。训练的时候,它看了海量的文章、书籍、网页、代码,把这些东西消化成了一套「语感直觉」。你问它问题,它靠这套直觉,一个字一个字往外写答案。
听着好像很厉害对吧。问题就在这里。
截止日期之后的事,它不知道。
你们公司上个季度更新的报销规定,它不知道。你昨天发的内部通知,它不知道。你正在开发的产品文档,它当然也不知道。
更关键的是,它不会承认自己不知道。
这是设计上的问题,不是bug。AI的运作方式是「根据上下文预测下一个最可能出现的词」,它没有一个「我不知道」的开关。遇到不会的,它会用自己的直觉拼凑一个听起来合理的答案。
说得越自信,往往错得越离谱。

顺着这个说,还有另一个现实问题。
你愿意把公司的合同、客户资料、核心产品文档,随便上传给AI吗?
大多数企业不敢,因为传出去就回不来了。这是一个真实的数据安全顾虑,不是多虑。
所以AI工具明明很好用,很多公司却根本没法真正落地,卡在这里。
一个是AI会乱编。一个是数据不能随便上传。这两个问题叠在一起,让「企业用AI」这件事变得非常憋屈。
好,那RAG是怎么解决这两个问题的。
思路其实很朴素,朴素到有点让人「就这?」
与其让AI「记住」所有东西,不如让它「查」。
你想想看,你考试可以开卷的时候,不需要把书全背下来。你只需要知道去哪找,找到了对着写答案就行。
AI也可以这样。
普通AI做的是闭卷考试,只能靠训练时的记忆答题。RAG给了它开卷考试的资格,考试前先去翻相关的笔记,再根据笔记写答案。
这个方法就叫RAG,全称Retrieval-Augmented Generation,检索增强生成。
先检索,再生成。

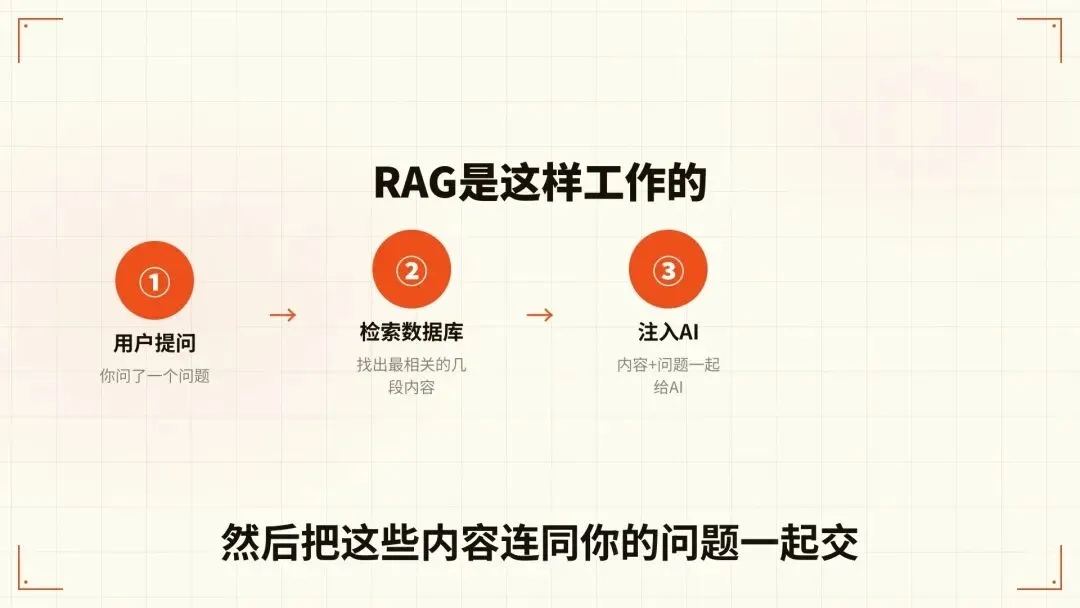
具体流程是这样的。你问了一个问题进来,系统先去你自己的数据库里搜一圈,找出最相关的几段内容,把这些内容连同你的问题一起交给AI,AI对着这些真实的资料给你写答案。
它不是在猜,它是看着笔记在答题。
而且你的数据全程放在你自己的服务器上,不需要上传给任何人。内容随时可以更新,今天更新,今天就能查到。
两个老问题,一个思路全解决了。
回到这块再聊聊,那个「可以查的数据库」到底是怎么建起来的。
你要把你的资料,变成一个能按意思来搜索的书架。分三步。
第一步,把资料全都导进来。PDF、Word文档、内部wiki、客服历史记录,都可以。
第二步,把长文章切成小段。整篇文档直接丢给AI,它消化不了,效果很差。所以要切,每段保留完整的意思,大概两三百字一段。这一步看着简单,实际上切法很讲究,切得不好会把一句话断在中间,语义就碎了。
第三步,给每一段生成一个「含义坐标」。这个过程叫向量化,也叫Embedding。你可以理解成,给每段文字分配了一个隐形的位置码,意思相近的内容坐标靠近,意思完全不同的距离很远。

最后把这些带坐标的内容存进向量数据库,书架就建好了。
它是按意思来归档的,不是按关键词。
这个区别很重要。普通数据库你搜「请假」,只能找到包含「请假」两个字的文档。语义数据库你搜「请假」,能找到「休假申请流程」,哪怕这两个词之间没有一个字相同。因为它们的意思是靠近的。
检索这块,比你想的复杂一点,说两个点。
第一,只靠语义检索有时候会漏内容。所以好的系统,会同时跑一遍传统的关键词检索,两个结果合并排序,取最相关的。这叫混合搜索。
第二,你问的问题有时候不够准确,或者一个问题包含了好几个子问题。系统可以帮你把问题重写,或者拆成几个子问题分别去找,最后汇总。

坦率的讲,很多人用了RAG感觉「也没多智能」,问题基本出在这里,检索出来的东西本身就不对,AI再怎么努力也没法给你一个好答案。
说到评估,有一套三元组标准我觉得挺实用的。
一,检索相关性,找到的内容,跟你问的问题是不是真的相关,有没有检索到一堆跑题的东西混在里面。
二,答案基于性,AI写的回答,有没有真正依据找到的内容,而不是回到老路子去猜。
三,答案相关性,最终的回答,有没有回答用户的问题。
三条都过了,这个系统才算真正可用。哪一条出了问题,就在那条上优化。

说到这里,RAG其实不神秘。
我自己折腾这块也有一段时间,最大的感受是,这个技术的上限和下限都很宽。
上限,取决于你的数据质量有多好,检索策略有多精细,评估反馈做得有多认真。有些团队把这一套搞得很扎实,AI的回答准确度能大幅提升。
下限,你随便搭一个最简单的RAG,效果可能比直接问AI还差,因为检索到了一堆不相关的内容,反而干扰了AI的判断。
所以「用了RAG就准确」,是不对的。RAG是一个框架,框架里每一步做好了,效果才能出来。
但对大多数有私有数据需求的场景来说,RAG几乎是绕不开的选择。
你不能一直让AI瞎猜。

今天这篇是个扫盲,把RAG是什么、为什么需要它、大概怎么工作,理清楚了。如果你对具体实现有兴趣,比如怎么选向量数据库、怎么优化检索策略,后面可以出更实操的版本。
可以把这篇发给身边对AI感兴趣但还没搞清楚RAG的朋友,帮他们少踩一个坑。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
/ 作者,词元Max
