 夜雨聆风
夜雨聆风别再一页页抄 PDF,Unlimited-OCR 把长文档解析成 Markdown
一篇给内容团队、知识库维护者、运营、法务和开发团队的实用拆解。
一份 60 页合同、一本文字很密的扫描手册、一份带表格和公式的研报,最折磨人的地方不是看,而是搬出来用。复制不出来,就只能截图、识别、校对、合并;页面一多,顺序、表格、脚注、图片说明都会乱。
传统 OCR 经常卡在另一个地方:它能认字,却常把一份完整文档拆成一堆孤立页面。第一页的标题、第三页的表格、后面附录里的说明,本来属于同一条线,处理完却变成很多碎片。后续要写报告、做资料库、给客户交付,人工补线的时间往往比识别本身更长。
百度 6 月 22 日开源的 Unlimited-OCR,瞄准的就是这一步。项目地址:https://github.com/baidu/Unlimited-OCR
它不是手机扫描王那类轻工具,而是一个面向长文档解析的 3B 模型。官方说法叫 One-shot Long-horizon Parsing,换成工作语言,就是尽量让模型连续读完多页文档,再输出可编辑的 Markdown。做内容、做知识库、做合同归档、做书稿整理,价值不在“识别几个字”,而在把一堆 PDF 变成后续能加工的文本。
官方示意图可以这样理解:左边是页面图像,右边不是一段纯文本,而是带段落、表格、坐标信息的结构化结果。
所以它适合先被当成一条“文档进厂”流水线来评估:输入是扫描图、PDF 页或图片目录,输出最好是可以继续编辑、检索、切片和入库的 Markdown。只要这条链路跑顺,后面的写作、检索、客服问答、内部培训才有基础材料。
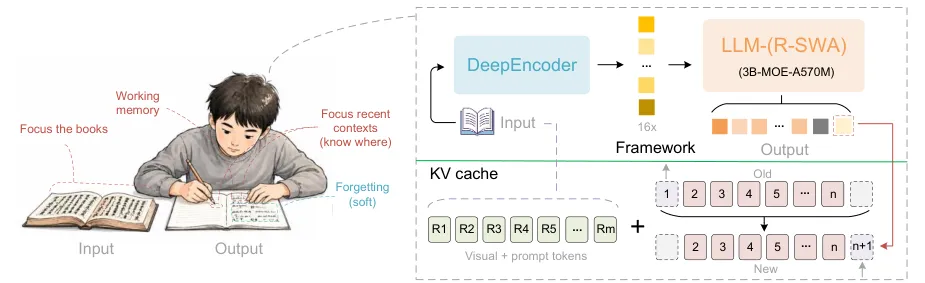
图 1:项目官方示意图。Unlimited-OCR 的目标是把页面图像解析成可继续加工的结构化文本。
最快的路径:先用在线 Demo,不急着装环境
最省事的方式,是先打开 Hugging Face Space。在线体验可用时,先上传一张清晰扫描图,再换一张带表格的 PDF 页,检查三件事:段落顺序有没有乱,表格列还在不在,输出能不能直接复制成 Markdown。
三个入口先记住:GitHub 项目地址:https://github.com/baidu/Unlimited-OCR;模型页:https://huggingface.co/baidu/Unlimited-OCR;在线体验:https://huggingface.co/spaces/baidu/Unlimited-OCR。
这一步不追求跑满性能,只看它能不能处理手上那类文件。能过,再考虑部署;过不了,就别急着接进流程。
Demo 阶段不要一上来扔整本书。更好的试法是挑三张典型页面:一张正文密集页,一张表格页,一张扫描质量最差的页。三张页面的 Markdown 都能读,才说明这个项目和手头资料匹配。要是表格直接散掉,或者脚注混进正文,后面批量跑只会把问题放大。
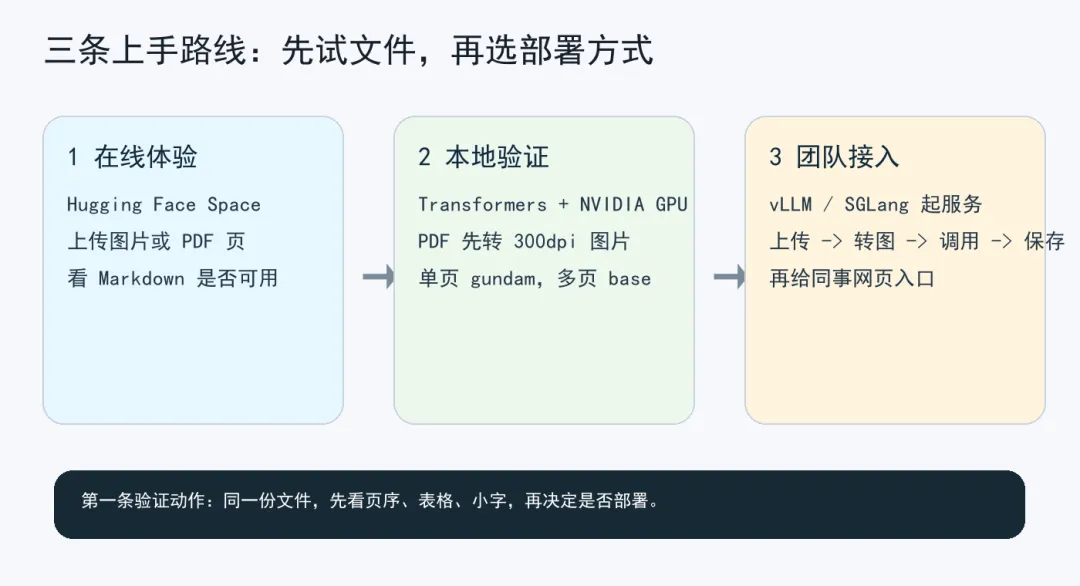
图 2:最快上手路线。先在线试文件,再决定用本地 Transformers、vLLM 或 SGLang。
自己部署,别少配这几个开关
要接入团队流程,优先看 vLLM recipe。官方页面写得很清楚:服务端要用专门镜像,prompt 要以 `` 开头,`skip_special_tokens` 要设为 False,还要带 n-gram 处理器。少一个,可能空输出,或者长文档里反复吐坐标标记。
服务端最短命令可以从这里开始:
docker pull vllm/vllm-openai:unlimited-ocr
docker run --rm --gpus all --network host --ipc host \
vllm/vllm-openai:unlimited-ocr\
baidu/Unlimited-OCR\
--trust-remote-code\
--logits_processorsvllm.model_executor.models.unlimited_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching\
--mm-processor-cache-gb0
本地 Transformers 路线也能跑,但 README 写的是 NVIDIA GPU,测试环境是 Python 3.12.3 + CUDA 12.9。单图可用 gundam 模式,多页或 PDF 要先用 PyMuPDF 转成 300dpi 图片,再走 `infer_multi` 的 base 模式。办公电脑没独显,不要在这里硬耗,先用在线 Demo 或云 GPU。
vLLM recipe 给的前提是单卡 8GB 以上显存可做 BF16 推理。复杂 PDF、并发请求、长输出会继续吃显存,正式使用前要拿自己的文件压一轮。
客户端调用也有一个容易忽略的点:prompt 不是随便写一句“帮我识别”,而是要按 recipe 从 `document parsing.` 开始。多页或 PDF 场景要把 `window_size` 调到 1024。拿到结果后,原始输出里可能带 `<|ref|>`、`<|det|>` 这类标记,做成业务工具前要把坐标框清掉,只保留干净 Markdown。
如果只是个人整理资料,用 Transformers 跑几份文件就够了;如果要给团队多人使用,vLLM 或 SGLang 更适合做成服务。懒一点的工程路径是:前端只管上传 PDF,后端转图片,按页或按批次调用模型,结果写成 `.md` 文件,再给一个下载按钮。别一开始就做复杂后台,先让一条文件能稳定跑完。
能落地的场景,靠的是把流程接起来
内容团队可以拿它整理行业白皮书、论文、说明书,把 PDF 变成 Markdown,再进 Notion、Obsidian 或 RAG 知识库。省下来的不是一次复制,而是反复校对页序的时间。
财务、法务和运营可以处理报价单、合同附件、招投标文件。表格型文件最怕被识别成散句,Unlimited-OCR 的重点是文档解析和阅读顺序,但金额、条款、日期仍要人工复核。
教育和书稿整理也适合。旧教材、讲义、扫描书稿先转成可搜索文本,再切成章节笔记。它适合做初稿,不适合无校对发布。
外贸、电商和售后团队也能用。供应商手册、产品说明书、质检报告,经常是 PDF 或扫描件。把它们转成 Markdown 后,可以继续翻译、改写成 FAQ、喂给客服知识库,减少同一份资料被不同岗位反复搬运。
开发团队可以把 vLLM 或 SGLang 起成内部服务,把上传 PDF、转图片、调用模型、保存 Markdown 串起来,给同事一个网页入口。真正省事的是把“每次手动识别”变成“上传后等结果”。
结果能到哪一步,要看文档质量
官方技术报告给了几个硬数字:模型总参数 3B,激活参数约 0.5B,最大长度 32K;在 OmniDocBench v1.5 上官方称总体结果 93%,v1.6 overall metric 为 93.92%。长页测试里,20 页输入仍保持较好结果;40+ 页时 edit distance 低于 0.11,Distinct-35 为 97%。
它能处理长文档,核心不是把上下文无限堆大,而是用了 Reference Sliding Window Attention。简单说,模型不用一直记住前面生成过的所有内容,只保留当前需要看的近处窗口和参考信息,KV cache 不随输出长度线性膨胀。长文档越长,这种设计越能减少速度下滑和显存压力。
这组数字说明它不是玩具,但也别把它当最终审稿员。小字、低清扫描、复杂跨页表格、手写批注,仍然要抽样复核。最稳的做法是先拿三类文件试跑:一页表格、一份 10 页 PDF、一份最糟糕的扫描件。三份都过,再接正式流程。
发布或交付前,可以按四项检查走一遍:页序有没有断,表格有没有错列,公式有没有丢符号,小字有没有被漏掉。只要其中一项经常出错,就不要批量放行,先换更清晰的扫描件,或者把文档拆成更小批次。

图 3:跑完不要只看“有输出”,要检查页序、表格、公式和小字。
写在收尾:先拿一份麻烦 PDF 跑通
Unlimited-OCR 给人的提醒很简单:文档工作可以少一段体力活。过去很多人做知识库、交付报告、整理资料,卡在 PDF 进不来、表格拆不开、长文档拼不回去。这个项目把那段卡点往前推了一步。
别先研究架构图。拿项目地址,打开 Demo,上传一份手上最麻烦的 PDF。能输出可用 Markdown,再决定要不要上 GPU、接 API、做批处理。工具能不能留下,不看它说了多大能力,看它能不能替你少一次重复搬运。
最实用的开始方式很简单:今天找一份最烦的扫描资料,跑一遍,保存 Markdown,对照原文改一轮。能把这个动作跑通,下一步才是自动化;跑不通,再漂亮的模型介绍都帮不上忙。
