














文档内容
§9.3 成对数据的统计分析
考试要求 1.了解样本相关系数的统计含义.2.理解一元线性回归模型和2×2列联表,会运
用这些方法解决简单的实际问题.3.会利用统计软件进行数据分析.
知识梳理
1.变量的相关关系
(1)相关关系:两个变量有关系,但又没有确切到可由其中的一个去精确地决定另一个的程
度,这种关系称为相关关系.
(2)相关关系的分类:正相关和负相关.
(3)线性相关:一般地,如果两个变量的取值呈现正相关或负相关,而且散点落在一条直线
附近,我们称这两个变量线性相关.
2.样本相关系数
(1)r=.
(2)当r>0时,称成对样本数据正相关;当r<0时,称成对样本数据负相关.
(3)|r|≤1;当|r|越接近1时,成对样本数据的线性相关程度越强;当|r|越接近0时,成对样本
数据的线性相关程度越弱.
3.一元线性回归模型
(1)我们将y=bx+a称为Y关于x的经验回归方程,
其中
(2)残差:观测值减去预测值,称为残差.
4.列联表与独立性检验
(1)关于分类变量X和Y的抽样数据的2×2列联表:
Y
X 合计
Y=0 Y=1
X=0 a b a+b
X=1 c d c+d
合计 a+c b+d n=a+b+c+d
(2)计算随机变量χ2=,利用χ2的取值推断分类变量X和Y是否独立的方法称为χ2独立性检
验.
α 0.10 0.05 0.010 0.005 0.001
x 2.706 3.841 6.635 7.879 10.828
α常用结论
1.经验回归直线过点(,).
2.求b时,常用公式b=.
3.回归分析和独立性检验都是基于成对样本观测数据进行估计或推断,得出的结论都可能
犯错误.
思考辨析
判断下列结论是否正确(请在括号中打“√”或“×”)
(1)散点图是判断两个变量相关关系的一种重要方法和手段.( √ )
(2)经验回归直线y =b x+a 至少经过点(x ,y),(x ,y),…,(x ,y)中的一个点.( ×
1 1 2 2 n n
)
(3)样本相关系数的绝对值越接近1,成对样本数据的线性相关程度越强.( √ )
(4)若分类变量X,Y关系越密切,则由观测数据计算得到的χ2的观测值越小.( × )
教材改编题
1.实验测得四组(x,y)的值为(1,2),(2,3),(3,4),(4,5),则y与x之间的经验回归方程为(
)
A.y=x+1 B.y=x+2
C.y=2x+1 D.y=x-1
答案 A
解析 由已知可得=×(1+2+3+4)=2.5,
=×(2+3+4+5)=3.5,
所以经验回归直线过点(2.5,3.5),
所以把点(2.5,3.5)代入四个选项中验证,可得只有y=x+1成立.
2.(多选)下列关于成对样本数据的统计分析的判断中正确的有( )
A.若样本相关系数r=0,则说明成对样本数据没有相关性
B.样本相关系数r越大,成对样本数据的线性相关性越强
C.用最小二乘法求得的一元线性回归模型的残差和一定是0
D.决定系数R2越大,残差平方和越小,模型的拟合效果越好
答案 CD
解析 对于A,当r=0时,只表明成对样本数据间没有线性相关关系,但是不排除它们之
间有其他相关关系,故A错误;
对于B,样本相关系数|r|越大,成对样本数据的线性相关性越强,故B错误;
对于C,残差和为
(y-y)=y-(bx+a)]
i i i i
=-b-a
i i=n-nb-na
=n(-b-a)=0,故C正确;
对于D,决定系数R2越大,表示残差平方和越小,即模型的拟合效果越好,故D正确.
3.(多选)为了解阅读量多少与幸福感强弱之间的关系,一个调查机构根据所得到的数据,
绘制了如下所示的2×2列联表(个别数据暂用字母表示):
幸福感强 幸福感弱 合计
阅读量多 m 18 72
阅读量少 36 n 78
合计 90 60 150
计算得:χ2≈12.981,参照下表:
α 0.10 0.05 0.025 0.010 0.005 0.001
x 2.706 3.841 5.024 6.635 7.879 10.828
α
对于下面的选项,正确的为( )
A.根据小概率值α=0.010的独立性检验,可以认为“阅读量多少与幸福感强弱无关”
B.m=54
C.根据小概率值α=0.005的独立性检验,可以在犯错误的概率不超过0.5%的前提下认为
“阅读量多少与幸福感强弱有关”
D.n=52
答案 BC
解析 ∵ χ2≈12.981>7.879>6.635,
∴根据小概率值α=0.010的独立性检验,可以在犯错误的概率不超过1%的前提下认为“阅
读量多少与幸福感强弱有关”,
根据小概率值α=0.005的独立性检验,可以在犯错误的概率不超过0.5%的前提下认为“阅
读量多少与幸福感强弱有关”,
∴A错,C对,
∵m+36=90,18+n=60,
∴m=54,n=42,
∴B对,D错.
题型一 成对数据的相关性
例1 (1)对变量x,y有观测数据(x,y)(i=1,2,…,10),得散点图如图1,对变量u,v有
i i
观测数据(u,v)(i=1,2,…,10),得散点图如图2.由这两个散点图可以判断( )
i i图1 图2
A.变量x与y正相关,u与v正相关
B.变量x与y正相关,u与v负相关
C.变量x与y负相关,u与v正相关
D.变量x与y负相关,u与v负相关
答案 C
解析 由题图可得两组数据均线性相关,且图1的经验回归直线的斜率为负,图2的经验回
归直线的斜率为正,则由散点图可判断变量x与y负相关,u与v正相关.
(2)(多选)下列有关经验回归分析的说法中正确的有( )
A.经验回归直线必过点(,)
B.经验回归直线就是散点图中经过样本数据点最多的那条直线
C.当样本相关系数r>0时,两个变量正相关
D.如果两个变量的相关性越弱,则|r|就越接近于0
答案 ACD
解析 对于A,经验回归直线必过点(,),故A正确;
对于B,经验回归直线在散点图中可能不经过任一样本数据点,故B不正确;
对于C,当样本相关系数r>0时,则两个变量正相关,故C正确;
对于D,如果两个变量的相关性越弱,则|r|就越接近于0,故D正确.
教师备选
1.在一组样本数据(x ,y),(x ,y),…,(x ,y)(n≥2,x ,x ,…,x 不全相等)的散点图
1 1 2 2 n n 1 2 n
中,若所有样本点(x,y)(i=1,2,…,n)都在直线y=x+1上,则这组样本数据的样本相关
i i
系数为( )
A.-1 B.0 C. D.1
答案 D
解析 所有样本点均在同一条斜率为正数的直线上,则样本相关系数最大,为1.
2.(多选)下列选项中正确的是( )
A.经验回归分析中,R2的值越大,说明残差平方和越小
B.若一组观测数据(x ,y),(x ,y),…,(x ,y)满足y=bx+a+e(i=1,2,…,n),若e
1 1 2 2 n n i i i i
恒为0,则R2=1
C.经验回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法D.画残差图时,纵坐标为残差,横坐标一定是编号
答案 ABC
解析 对于A,经验回归分析中,R2的值越大,说明模型的拟合效果越好,则残差平方和越
小,A对;
对于B,若一组观测数据(x,y),(x,y),…,(x,y)满足y=bx+a+e(i=1,2,…,n),
1 1 2 2 n n i i i
若e恒为0,则R2=1,B对;
i
对于C,经验回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法,C对;
对于D,残差图中横坐标可以是样本编号,也可以是身高数据,还可以是体重的估计值等,
D错.
思维升华 判定两个变量相关性的方法
(1)画散点图:点的分布从左下角到右上角,两个变量正相关;点的分布从左上角到右下角,
两个变量负相关.
(2)样本相关系数:当r>0时,正相关;当r<0时,负相关;|r|越接近于1,相关性越强.
(3)经验回归方程:当b>0时,正相关;当b<0时,负相关.
跟踪训练1 (1)已知变量x和y满足关系y=-0.1x+1,变量y与z正相关.下列结论中正
确的是( )
A.x与y正相关,x与z负相关 B.x与y正相关,x与z正相关
C.x与y负相关,x与z负相关 D.x与y负相关,x与z正相关
答案 C
解析 因为y=-0.1x+1的斜率小于0,故x与y负相关.因为y与z正相关,可设z=by+
a,b>0,则z=by+a=-0.1bx+b+a,故x与z负相关.
(2)对四组数据进行统计,获得如图所示的散点图,关于其样本相关系数的比较,正确的是(
)
A.r0,r>0,图(2)与图(4)是负相关,故r<0,
1 3 2
r<0,且图(1)与图(2)的样本点集中在一条直线附近,因此rR=0.893.
∴甲建立的回归模型拟合效果更好.
②由①知,甲建立的回归模型拟合效果更好.
设20.3x+3.7≥100,
解得0.3x+3.7≥log 100=2+2log 5,
2 2
解得x≥9.7.
∴科技投入的费用至少要9.7百万元,下一年的收益才能达到1亿元.
教师备选
1.(2022·湖北九师联盟联考)下表是关于某设备的使用年限x(单位:年)和所支出的维修费用
y(单位:万元)的统计表.
x 2 3 4 5 6
y 3.4 4.2 5.1 5.5 6.8
由上表可得经验回归方程y=0.81x+a,若规定:维修费用y不超过10万元,一旦大于10万
元时,该设备必须报废.据此模型预测,该设备使用年限的最大值约为( )
A.7 B.8 C.9 D.10
答案 D
解析 由表格,得
=×(2+3+4+5+6)=4,
=×(3.4+4.2+5.1+5.5+6.8)=5,
因为经验回归直线恒过点(,),
所以5=0.81×4+a,
解得a=1.76,
所以经验回归方程为y=0.81x+1.76,
由y≤10,得0.81x+1.76≤10,
解得x≤≈10.17,
由于x∈N*,所以据此模型预测,该设备使用年限的最大值约为10.
2.用模型y=cekx拟合一组数据时,为了求出经验回归方程,设z=ln y,其变换后得到经验
回归方程为z=0.5x+2,则c等于( )
A.0.5 B.e0.5 C.2 D.e2
答案 D
解析 因为y=cekx,两边取对数得,ln y=ln(cekx)=ln c+ln ekx=kx+ln c,
则z=kx+ln c,而z=0.5x+2,
于是得ln c=2,即c=e2.
思维升华 求经验回归方程的步骤
跟踪训练2 为实施乡村振兴,科技兴农,某村建起了田园综合体,并从省城请来专家进行
技术指导.根据统计,该田园综合体西红柿亩产量的增加量 y(千克)与某种液体肥料每亩使
用量x(千克)之间的对应数据如下.
x(千克) 2 4 5 6 8
y(千克) 300 400 400 400 500
(1)由上表数据可知,可用经验回归模型拟合y与x的关系,请计算样本相关系数r并加以说
明(若|r|>0.75,则线性相关程度很高,可用经验回归模型拟合);
(2)求y关于x的经验回归方程,并预测当液体肥料每亩使用量为15千克时,西红柿亩产量
的增加量约为多少千克?
参考数据:≈3.16.
解 (1)由已知数据可得
==5,
==400,
所以(x-)(y-)=(-3)×(-100)+(-1)×0+0×0+1×0+3×100=600,
i i
==2,
==100,
所以样本相关系数r===≈0.95.
因为|r|>0.75,所以可用经验回归模型拟合y与x的关系.
(2)b===30,a=400-5×30=250,
所以经验回归方程为y=30x+250.
当x=15时,y=30×15+250=700,
即当液体肥料每亩使用量为15千克时,西红柿亩产量的增加量约为700千克.
题型三 列联表与独立性检验
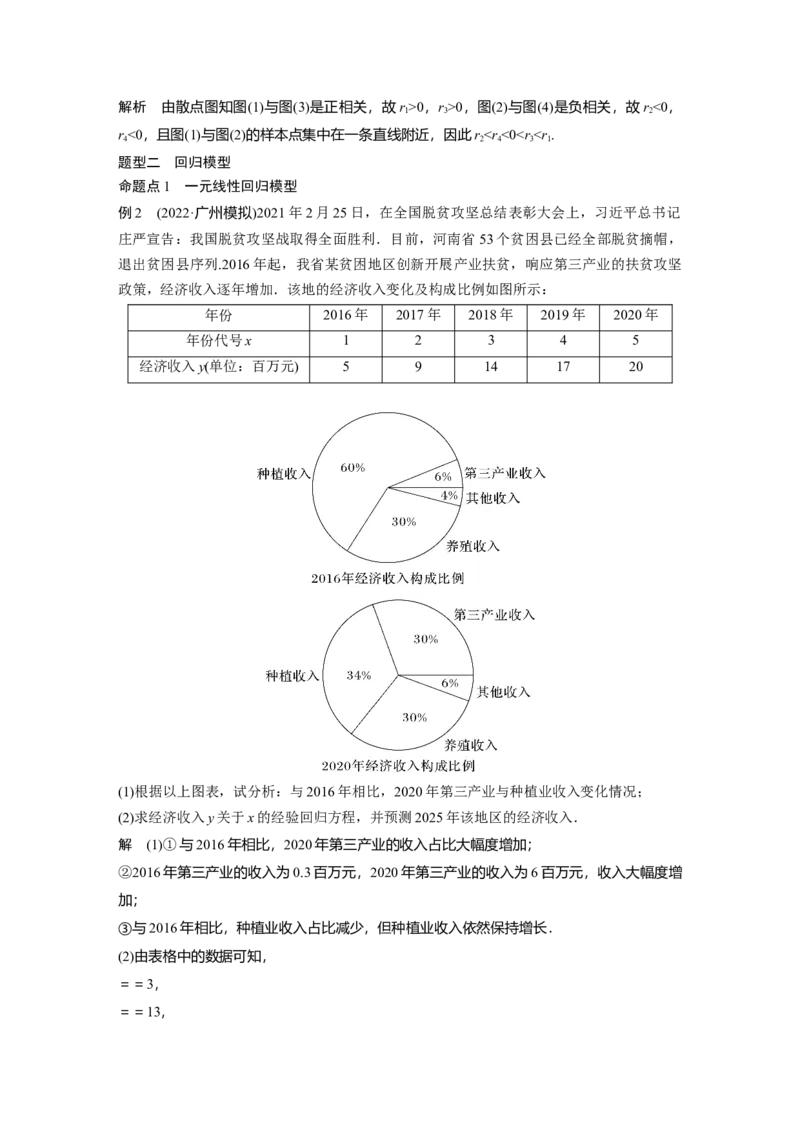
例4 (2021·全国甲卷改编)甲、乙两台机床生产同种产品,产品按质量分为一级品和二级品,
为了比较两台机床产品的质量,分别用两台机床各生产了200件产品,产品的质量情况统计如下表:
一级品 二级品 合计
甲机床 150 50 200
乙机床 120 80 200
合计 270 130 400
(1)甲机床、乙机床生产的产品中一级品的频率分别是多少?
(2)依据小概率值α=0.01的独立性检验,能否以此推断甲机床的产品质量与乙机床的产品质
量有差异?
解 (1)根据题表中数据知,甲机床生产的产品中一级品的频率是=0.75,乙机床生产的产品
中一级品的频率是=0.6.
(2)零假设为H:甲机床的产品质量与乙机床的产品质量无差异.根据2×2列联表,可得
0
χ2==
≈10.256>6.635=x .
0.01
根据小概率值α=0.01的独立性检验,我们推断H 不成立,即认为甲机床的产品质量与乙机
0
床的产品质量有差异.
教师备选
1.为了解某大学的学生是否爱好体育锻炼,用简单随机抽样方法在校园内调查了120位学
生,得到如下2×2列联表:
男 女 合计
爱好 a b 73
不爱好 c 25
合计 74
则a-b-c等于( )
A.7 B.8 C.9 D.10
答案 C
解析 根据题意,可得c=120-73-25=22,a=74-22=52,b=73-52=21,
∴a-b-c=52-21-22=9.
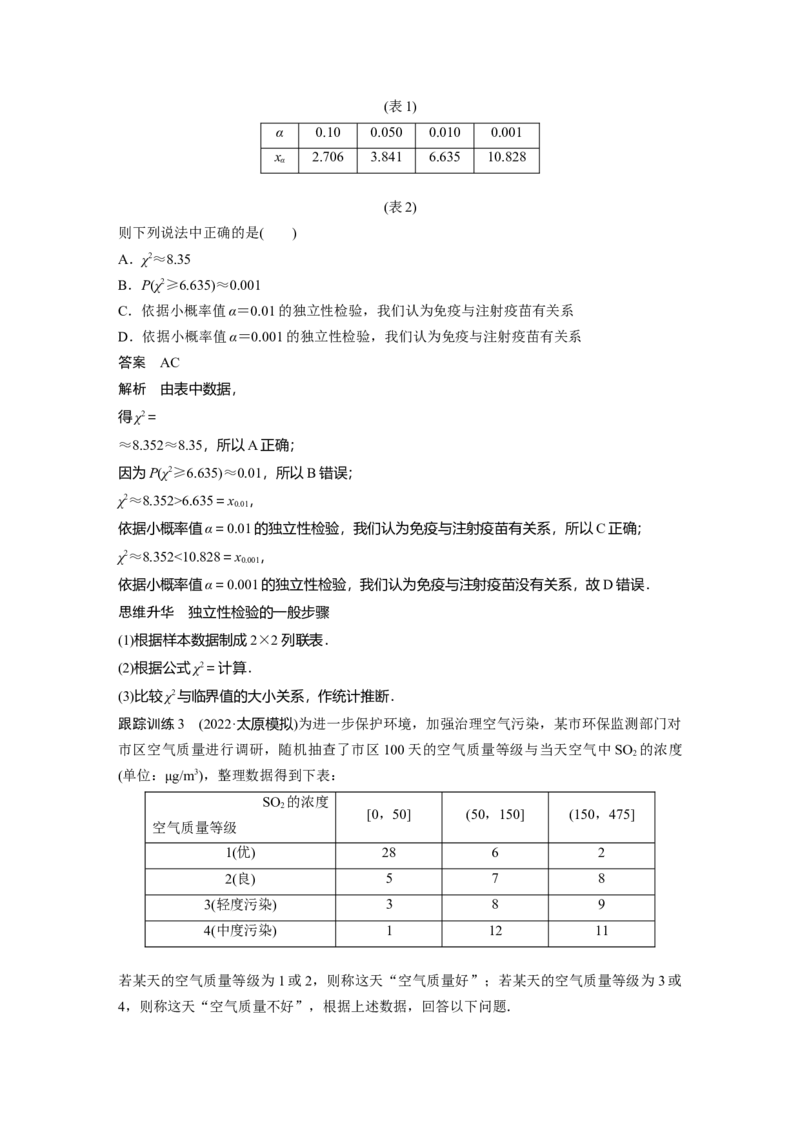
2.(多选)某医疗研究机构为了了解免疫与注射疫苗的关系,进行一次抽样调查,得到数据
如表1.
免疫 不免疫 合计
注射疫苗 10 10 20
未注射疫苗 6 34 40
合计 16 44 60(表1)
α 0.10 0.050 0.010 0.001
x 2.706 3.841 6.635 10.828
α
(表2)
则下列说法中正确的是( )
A.χ2≈8.35
B.P(χ2≥6.635)≈0.001
C.依据小概率值α=0.01的独立性检验,我们认为免疫与注射疫苗有关系
D.依据小概率值α=0.001的独立性检验,我们认为免疫与注射疫苗有关系
答案 AC
解析 由表中数据,
得χ2=
≈8.352≈8.35,所以A正确;
因为P(χ2≥6.635)≈0.01,所以B错误;
χ2≈8.352>6.635=x ,
0.01
依据小概率值α=0.01的独立性检验,我们认为免疫与注射疫苗有关系,所以C正确;
χ2≈8.352<10.828=x ,
0.001
依据小概率值α=0.001的独立性检验,我们认为免疫与注射疫苗没有关系,故D错误.
思维升华 独立性检验的一般步骤
(1)根据样本数据制成2×2列联表.
(2)根据公式χ2=计算.
(3)比较χ2与临界值的大小关系,作统计推断.
跟踪训练3 (2022·太原模拟)为进一步保护环境,加强治理空气污染,某市环保监测部门对
市区空气质量进行调研,随机抽查了市区100天的空气质量等级与当天空气中SO 的浓度
2
(单位:μg/m3),整理数据得到下表:
SO 的浓度
2
[0,50] (50,150] (150,475]
空气质量等级
1(优) 28 6 2
2(良) 5 7 8
3(轻度污染) 3 8 9
4(中度污染) 1 12 11
若某天的空气质量等级为1或2,则称这天“空气质量好”;若某天的空气质量等级为3或
4,则称这天“空气质量不好”,根据上述数据,回答以下问题.(1)估计事件“该市一天的空气质量好,且SO 的浓度不超过150”的概率;
2
(2)完成下面的2×2列联表,
SO 的浓度
2
[0,150] (150,475] 合计
空气质量
空气质量好
空气质量不好
合计
(3)根据(2)中的列联表,依据小概率值α=0.01的独立性检验,能否据此推断该市一天的空气
质量与当天SO 的浓度有关?
2
解 (1)由表格可知,该市一天的空气质量好,且 SO 的浓度不超过150的天数为28+6+5
2
+7=46,则“该市一天的空气质量好,且SO 的浓度不超过150”的概率P==0.46.
2
(2)由表格数据可得列联表如下,
SO 的浓度
2
[0,150] (150,475] 合计
空气质量
空气质量好 46 10 56
空气质量不好 24 20 44
合计 70 30 100
(3)零假设为H:该市一天的空气质量与当天SO 的浓度无关.
0 2
由(2)知χ2=
≈8.936>6.635=x ,
0.01
根据小概率值α=0.01的独立性检验,我们推断H 不成立,即认为该市一天的空气质量与当
0
天SO 的浓度有关.
2
课时精练
1.如表是2×2列联表,则表中的a,b的值分别为( )
y y 合计
1 2
x a 8 35
1
x 11 34 45
2
合计 b 42 80
A.27,38 B.28,38 C.27,37 D.28,37答案 A
解析 a=35-8=27,b=a+11=27+11=38.
2.(2022·湘豫名校模拟)根据如表样本数据:
x 2 3 4 5 6
y 4 2.5 -0.5 -2 -3
得到的经验回归方程为y=bx+a,则( )
A.a>0,b>0 B.a>0,b<0 C.a<0,b>0 D.a<0,b<0
答案 B
解析 由表中的数据可得,变量y随着x的增大而减小,则b<0,
==4,
==0.2,
又经验回归方程y=bx+a经过点(4,0.2),可得a>0.
3.某种产品的广告费支出x与销售额y(单位:万元)之间的关系如表:
x 2 4 5 6 8
y 30 40 60 50 70
y与x的经验回归方程为y=6.5x+17.5,当广告支出6万元时,随机误差的残差为( )
A.-5 B.-5.5
C.-6 D.-6.5
答案 D
解析 由题意结合经验回归方程的预测作用可得,当x=6时,y=6.5×6+17.5=56.5,则
随机误差的残差为50-56.5=-6.5.
4.(2022·泉州模拟)蟋蟀鸣叫可以说是大自然优美、和谐的音乐,殊不知蟋蟀鸣叫的频率
x(每分钟鸣叫的次数)与气温y(单位:℃)存在着较强的线性相关关系.某地观测人员根据如
表的观测数据,建立了y关于x的经验回归方程y=0.25x+k,则下列说法不正确的是( )
x(次数/分钟) 20 30 40 50 60
y(℃) 25 27.5 29 32.5 36
A.k的值是20
B.变量x,y呈正相关关系
C.若x的值增加1,则y的值约增加0.25
D.当蟋蟀52次/分鸣叫时,该地当时的气温预测值为33.5 ℃
答案 D
解析 由题意,得=×(20+30+40+50+60)=40,
=×(25+27.5+29+32.5+36)=30,
则k=-0.25=30-0.25×40=20,
故A正确;
由经验回归方程可知,b=0.25>0,
变量x,y呈正相关关系,故B正确;
若x的值增加1,则y的值约增加0.25,
故C正确;
当x=52时,y=0.25×52+20=33,
故D不正确.
5.(多选)下列说法正确的是( )
A.设有一个经验回归方程y=3-5x,变量x增加一个单位时,y平均增加5个单位
B.若两个具有线性相关关系的变量的相关性越强,则样本相关系数r的值越接近于1
C.在残差图中,残差点分布的水平带状区域越窄,说明模型的拟合精度越高
D.在一元线性回归模型中,决定系数R2越接近于1,说明回归的效果越好
答案 CD
解析 A选项,因为y=3-5x,所以变量x增加一个单位时,y平均减少5个单位,故A错
误;
B选项,线性相关性具有正负,相关性越强,则样本相关系数r的绝对值越接近于1,故B
错误;
C选项,在残差图中,残差点分布的水平带状区域越窄,说明波动越小,即模型的拟合精度
越高,故C正确;
D选项,在一元线性回归模型中,决定系数R2越接近于1,说明模型拟合的精度越高,即回
归的效果越好,故D正确.
6.(多选)2021年5月18日,《佛山市第七次全国人口普查公报》发布.公报显示,佛山市
常住人口为9 498 863人.为了进一步分析数据特征,某数学兴趣小组先将近五次人口普查
数据作出散点图(横坐标为人口普查的序号,第三次普查记为1,…,第七次普查记为5,纵
坐标为当次人口普查佛山市人口数(单位:万人),再利用不同的函数模型作出回归分析,如
图,以下说法正确的是( )A.佛山市人口数与普查序号呈正相关关系
B.散点的分布呈现出很弱的线性相关特征
C.经验回归方程2的拟合效果更好
D.应用经验回归方程1可以预测第八次人口普查时佛山市人口会超过1 400万人
答案 AC
解析 对于A,散点图中的点的分布从左下方至右上方,故呈正相关关系,故A正确;
对于B,利用模型1,样本点基本分布在直线的两侧,故具有较强的线性相关特征,故B错
误;
对于C,因为0.979 4>0.972 6,所以经验回归方程2的拟合效果更好,故C正确;
对于D,利用模型1,当x=6时,y=183.5×6-1.7=1 099.3<1 400,故D错误.
7.(2022·广州模拟)某车间为了提高工作效率,需要测试加工零件所花费的时间,为此进行
了5次试验,这5次试验的数据如下表:
零件数x(个) 10 20 30 40 50
加工时间y(min) 62 a 75 81 89
若用最小二乘法求得经验回归方程为y=0.67x+54.9,则a的值为________.
答案 68
解析 由已知==30,
==61+,
所以61+=0.67×30+54.9,解得a=68.
8.(2022·青岛模拟)某驾驶员培训学校为对比了解“科目二”的培训过程采用大密度集中培训与周末分散培训两种方式的效果,调查了105名学员,统计结果为:接受大密度集中培训
的55个学员中有45名学员一次考试通过,接受周末分散培训的学员一次考试通过的有 30
个.根据统计结果,认为“能否一次考试通过与是否集中培训有关”犯错误的概率不超过
________.
附:χ2=,其中n=a+b+c+d;
α 0.05 0.025 0.010 0.001
x 3.841 5.024 6.635 10.828
α
答案 0.025
解析 由题意可得列联表如下,
集中培训 分散培训 合计
一次考过 45 30 75
一次未考过 10 20 30
合计 55 50 105
χ2=≈6.109>5.024=x .
0.025
9.(2022·河南九师联盟联考)机动车行经人行横道时,应当减速慢行:遇行人正在通过人行
横道,应当停车让行,俗称“礼让行人”.如表是某市一主干路口监控设备所抓拍的1-5
月份驾驶员不“礼让行人”行为统计数据:
月份 1 2 3 4 5
违章驾驶员人数 120 105 100 95 80
(1)请利用所给数据求违章人数y与月份x之间的经验回归方程y=bx+a,并预测该路口10
月份的不“礼让行人”违章驾驶员人数;
(2)交警从这5个月内通过该路口的驾驶员中随机抽查70人,调查驾驶员不“礼让行人”行
为与驾龄的关系,如表所示:
不礼让行人 礼让行人
驾龄不超过1年 24 16
驾龄1年以上 16 14
依据小概率值α=0.1的独立性检验,能否据此判断“礼让行人”行为与驾龄有关?
解 (1)由表中的数据可知,==3,
==100,
所以b===-9,
故a=-b=100-(-9)×3=127,
所以所求的经验回归方程为y=-9x+127;令x=10,则y=-9×10+127=37.
(2)零假设为H:“礼让行人”行为与驾龄无关,
0
由表中的数据可得
χ2==
≈0.311<2.706=x ,
0.1
根据小概率值α=0.1的独立性检验,没有充分证据推断H 不成立,因此可以认为H 成立,
0 0
即依据小概率值α=0.1的独立性检验,不能判断“礼让行人”行为与驾龄有关.
10.现代物流成为继劳动力、自然资源外影响企业生产成本及利润的重要因素.某企业去年
前八个月的物流成本和企业利润的数据(单位:万元)如表所示:
月份 1 2 3 4 5 6 7 8
物流成本x 83 83.5 80 86.5 89 84.5 79 86.5
利润y 114 116 106 122 132 114 m 132
残差ei=y-yi 0.2 0.6 1.8 -3 -1 -4.6 -1
i
根据最小二乘法估计公式求得经验回归方程为y=3.2x-151.8.
(1)求m的值,并利用已知的经验回归方程求出8月份对应的残差值e;
8
(2)请先求出一元线性回归模型y=3.2x-151.8的决定系数R2(精确到0.000 1);若根据非线性
回归模型y=267.76ln x-1 069.2求得解释变量(物流成本)对于响应变量(利润)的决定系数R
=0.905 7,请说明以上两种模型哪种模型拟合效果更好?
(3)通过残差分析,怀疑残差绝对值最大的那组数据有误,经再次核实后发现其真正利润应
该为116万元.请重新根据最小二乘法的思想与公式,求出新的经验回归方程.
附(修正前的参考数据):y=78 880,
i i
=56 528,=84,(y-)2=904.
i
解 (1)因为y=3.2x-151.8,=84,
所以=3.2×84-151.8=117,
114+116+106+122+132+114+m+132
=117×8,
解得m=100,
所以8月份对应的残差值
e=132-3.2×86.5+151.8=7.
8
(2)由已知公式得(y-yi)2=0.22+0.62+1.82+(-3)2+(-1)2+(-4.6)2+(-1)2+72=84.8,
i
R2=1-=1-≈0.906 2>R,
所以一元线性回归模型y=3.2x-151.8拟合效果更好.
(3)第八组数据的利润应为116万元,此时 y=78 880-86.5×16=77 496,
i i
又=56 528,=84,
=117-=115,
所以b=
==2.7,
a=115-2.7×84=-111.8,所以重新采集数据后,经验回归方程为y=2.7x-111.8.
11.某中学调查了高一年级学生的选科倾向,随机抽取300人,其中选考物理的有220人,
选考历史的有80人,统计各选科人数如表,则下列说法正确的是( )
选择科目
思想政治 地理 化学 生物
选考类别
物理类 80 100 145 115
历史类 50 45 30 35
α 0.10 0.05 0.025 0.010 0.005 0.001
x 2.706 3.841 5.024 6.635 7.879 10.828
α
A.物理类的学生中选择政治的比例比历史类的学生中选择政治的比例高
B.物理类的学生中选择地理的比例比历史类的学生中选择地理的比例高
C.根据小概率值α=0.1的独立性检验,我们认为选择生物与选考类别无关
D.根据小概率值α=0.1的独立性检验,我们认为选择生物与选考类别有关
答案 C
解析 对于A,物理类的学生中选择政治的比例为=,
历史类的学生中选择政治的比例为=,
因为<,故选项A不正确;
对于B,物理类的学生中选择地理的比例为
=,
历史类的学生中选择地理的比例为=,
因为<,故选项B不正确;
对于C和D,零假设为H:选择生物与选考类别无关.
0
根据已知数据可得2×2列联表如表:
选生物 不选生物 合计
物理类 115 105 220
历史类 35 45 80合计 150 150 300
所以χ2==≈1.705<2.706=x ,
0.1
根据小概率值α=0.1的独立性检验,没有充分证据推断H 不成立,因此可以认为H 成立,
0 0
即认为选择生物与选考类别无关,故选项C正确,选项D不正确.
12.已知变量y与x的一组数据如表所示,根据数据得到y关于x的经验回归方程为y=ebx-1.
x 1 2 3 4
y e2 e3 e5 e6
若y=e13,则x等于( )
A.6 B.7 C.8 D.9
答案 B
解析 由y=ebx-1,得ln y=bx-1,
令z=ln y,则z=bx-1,
由题意知,==2.5,
==4,
因为(,)满足z=bx-1,
所以4=b×2.5-1,解得b=2,
所以z=2x-1,所以y=e2x-1,
令e2x-1=e13,解得x=7.
13.(多选)(2022·武汉联考)下列选项中,正确的是( )
A.对于回归分析,样本相关系数r的绝对值越小,说明拟合效果越好
B.以模型y=c·ekx去拟合一组数据时,为了求出经验回归方程,设 z=ln y,将其变换后得
到经验回归方程z=0.3x+4,则c,k的值分别是e4和0.3
C.经验回归方程y=bx+a中,b的符号和样本相关系数r的符号一致
D.通过经验回归直线y=bx+a及回归系数b,可以精确反映变量的取值和变化趋势
答案 BC
解析 对于A,回归分析中,样本相关系数绝对值越大,拟合效果越好,A不正确;
对于B,由y=c·ekx两边取对数得
ln y=kx+ln c,
依题意,k=0.3,ln c=4,即c=e4,B正确;
对于C,由公式知,C正确.
对于D,经验回归直线y=bx+a及回归系数b,不能精确反映变量的取值和变化趋势,D不
正确.14.(2022·漳州模拟)根据下面的数据:
x 1 2 3 4
y 32 48 72 88
求得y关于x的经验回归方程为y=19.2x+12,则这组数据相对于所求的经验回归方程的4
个残差的方差为________.(注:残差是指实际观测值与预测值之间的差)
答案 3.2
解析 把x=1,2,3,4依次代入经验回归方程
y=19.2x+12,所得预测值依次为y=31.2,
1
y=50.4,y=69.6,y=88.8,
2 3 4
对应的残差依次为0.8,-2.4,2.4,-0.8,它们的平均数为0,所以4个残差的方差为s2==
3.2.
15.(多选)已知由样本数据(x,y),i=1,2,3,4,5,6求得的经验回归方程为y=2x+1,且=3.现
i i
发现一个样本数据(8,12)误差较大,去除该数据后重新求得的经验回归直线l的纵截距依然
是1,则下列说法正确的是( )
A.去除前变量x每增加1个单位,变量y一定增加2个单位
B.去除后剩余样本数据中x的平均数为2
C.去除后的经验回归方程为y=2.5x+1
D.去除后样本相关系数r变大
答案 BCD
解析 当=3时,=2×3+1=7,
则 =6=18,=6=42,
i i
去除样本数据(8,12)后的新数据,
==2,==6,
设去除样本数据(8,12)后重新求得的经验回归方程为y=ax+1,
则2a+1=6,解得a=2.5,故去除后的经验回归方程为y=2.5x+1,C正确;
对于A选项,去除前变量x每增加1个单位,变量y大约增加2个单位,A错误;
对于B选项,去除后剩余样本数据中x的平均数为2,B正确;
对于D选项,去除了误差较大的样本数据后,线性相关性变强,因为y关于x为正相关,则
r>0,所以,样本相关系数r变大,D正确.
16.(2022·梅州模拟)某市某医疗器械公司转型升级,从9月1日开始投入呼吸机生产,该公
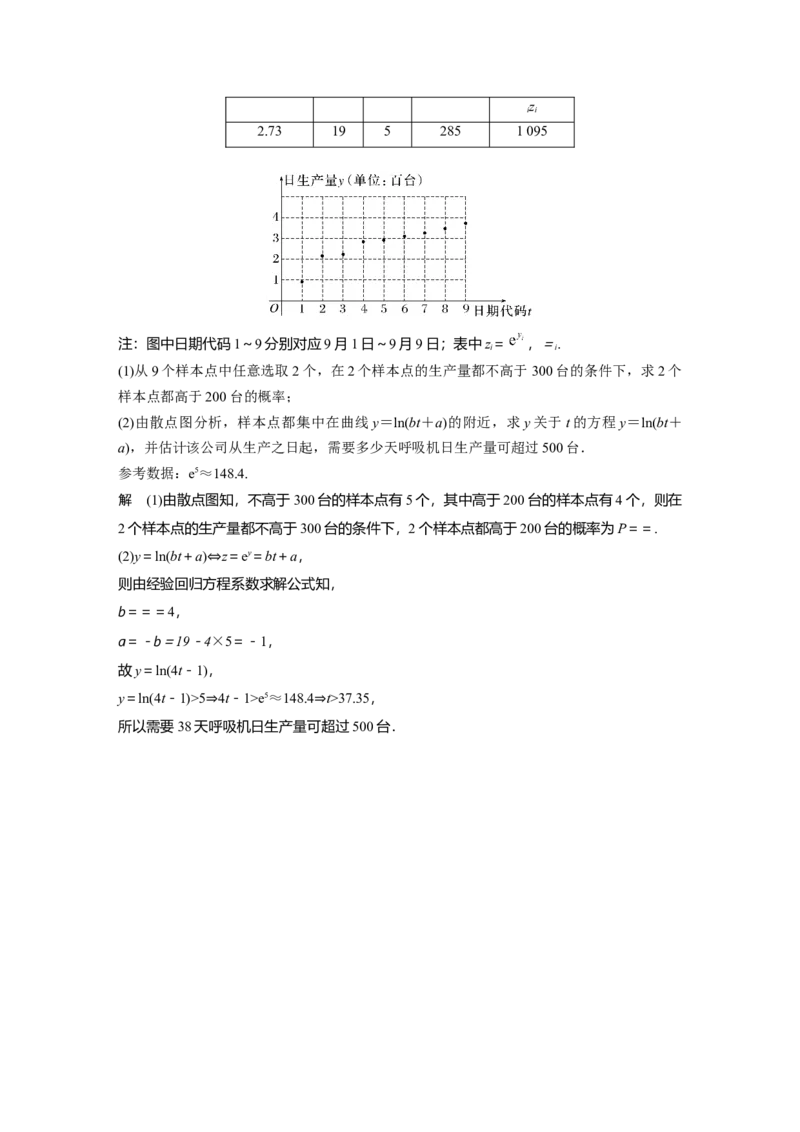
司9月1日~9月9日连续9天的呼吸机日生产量为y(单位:百台,i=1,2,…,9),数据作
i
了初步处理,得到如图所示的散点图.z
i i
2.73 19 5 285 1 095
注:图中日期代码1~9分别对应9月1日~9月9日;表中z= ,=.
i i
(1)从9个样本点中任意选取2个,在2个样本点的生产量都不高于300台的条件下,求2个
样本点都高于200台的概率;
(2)由散点图分析,样本点都集中在曲线y=ln(bt+a)的附近,求y关于t的方程y=ln(bt+
a),并估计该公司从生产之日起,需要多少天呼吸机日生产量可超过500台.
参考数据:e5≈148.4.
解 (1)由散点图知,不高于300台的样本点有5个,其中高于200台的样本点有4个,则在
2个样本点的生产量都不高于300台的条件下,2个样本点都高于200台的概率为P==.
(2)y=ln(bt+a) z=ey=bt+a,
则由经验回归方⇔程系数求解公式知,
b===4,
a=-b=19-4×5=-1,
故y=ln(4t-1),
y=ln(4t-1)>5 4t-1>e5≈148.4 t>37.35,
所以需要38天⇒呼吸机日生产量可⇒超过500台.

