 夜雨聆风
夜雨聆风





和DeepSeek-OCR撞车了?!
也是第一次真切地体验到——和顶流公司撞paper的感觉
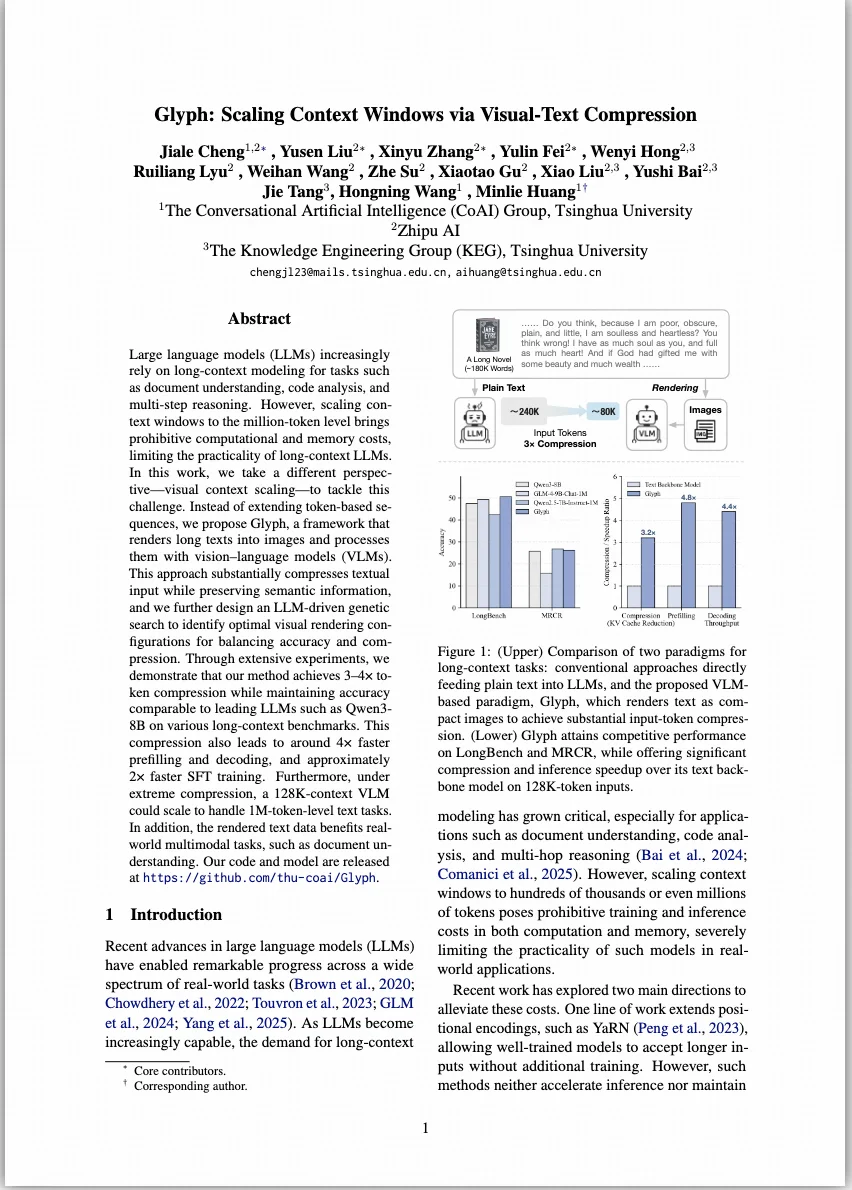
我们最近探索了一个有趣的方向:Glyph —— Scaling Context Windows via Visual-Text Compression。
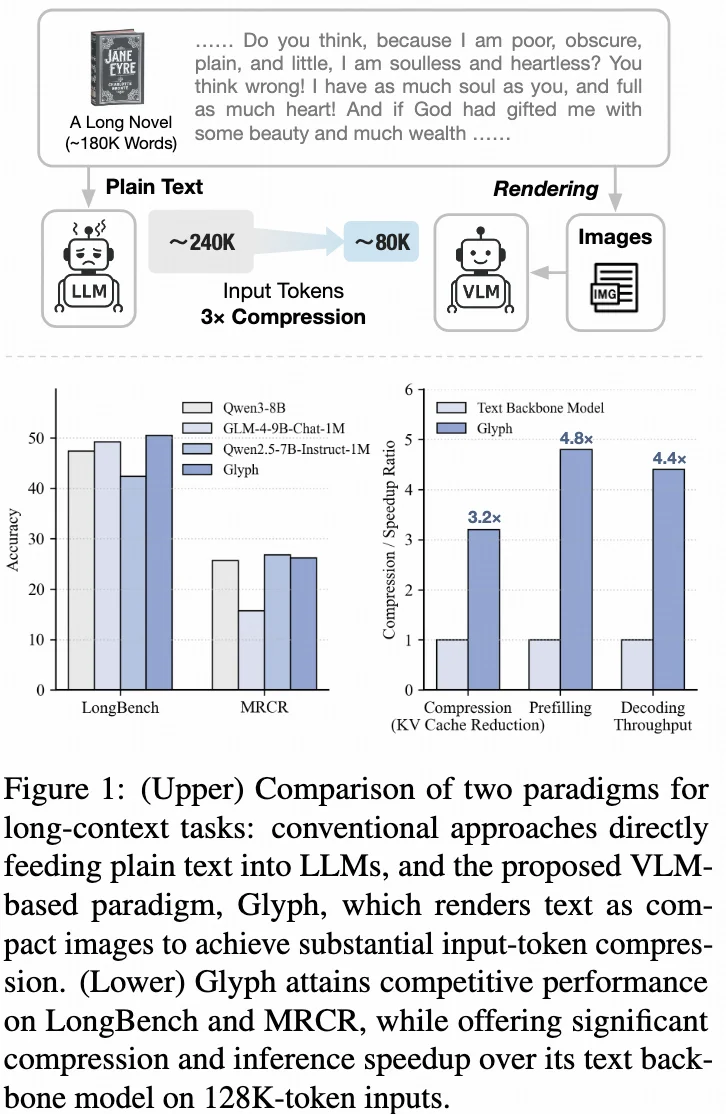
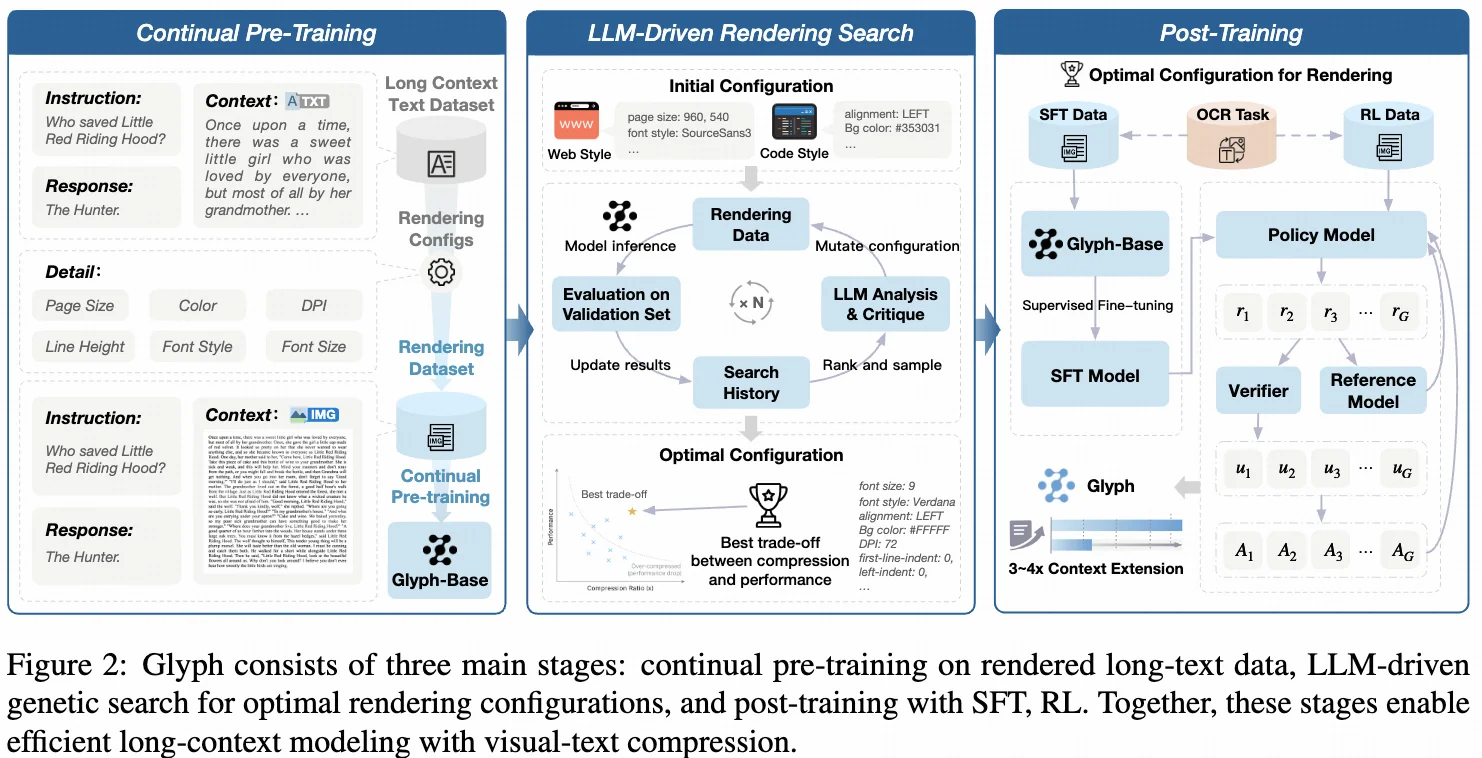
一句话总结:让大模型“看”文本,而不是“读”文本。 Glyph 从输入端出发,把长文本“画”成图像,让模型以视觉方式理解语义。这样就能用图像输入取代传统的文本 token,在不改变模型结构的前提下处理更长的上下文,轻松突破计算与显存的瓶颈。
也进一步说明:用 VLM 扩展长上下文确实是一条可行且潜力巨大的路径,希望未来能构建出千万token的模型
我们最近探索了一个有趣的方向:Glyph —— Scaling Context Windows via Visual-Text Compression。
一句话总结:让大模型“看”文本,而不是“读”文本。 Glyph 从输入端出发,把长文本“画”成图像,让模型以视觉方式理解语义。这样就能用图像输入取代传统的文本 token,在不改变模型结构的前提下处理更长的上下文,轻松突破计算与显存的瓶颈。
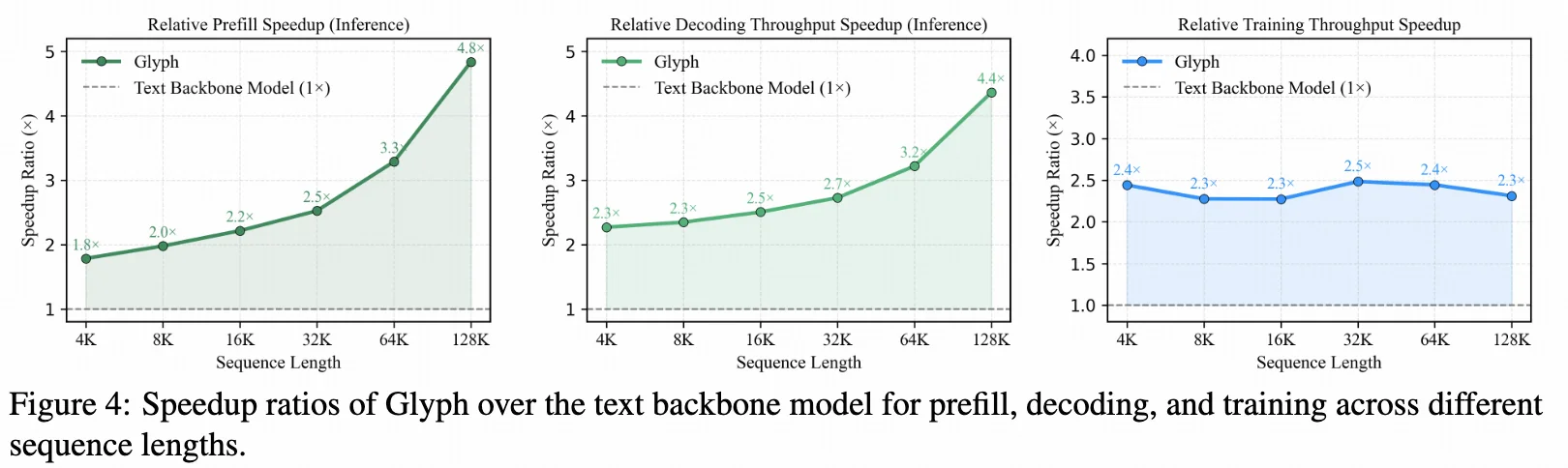
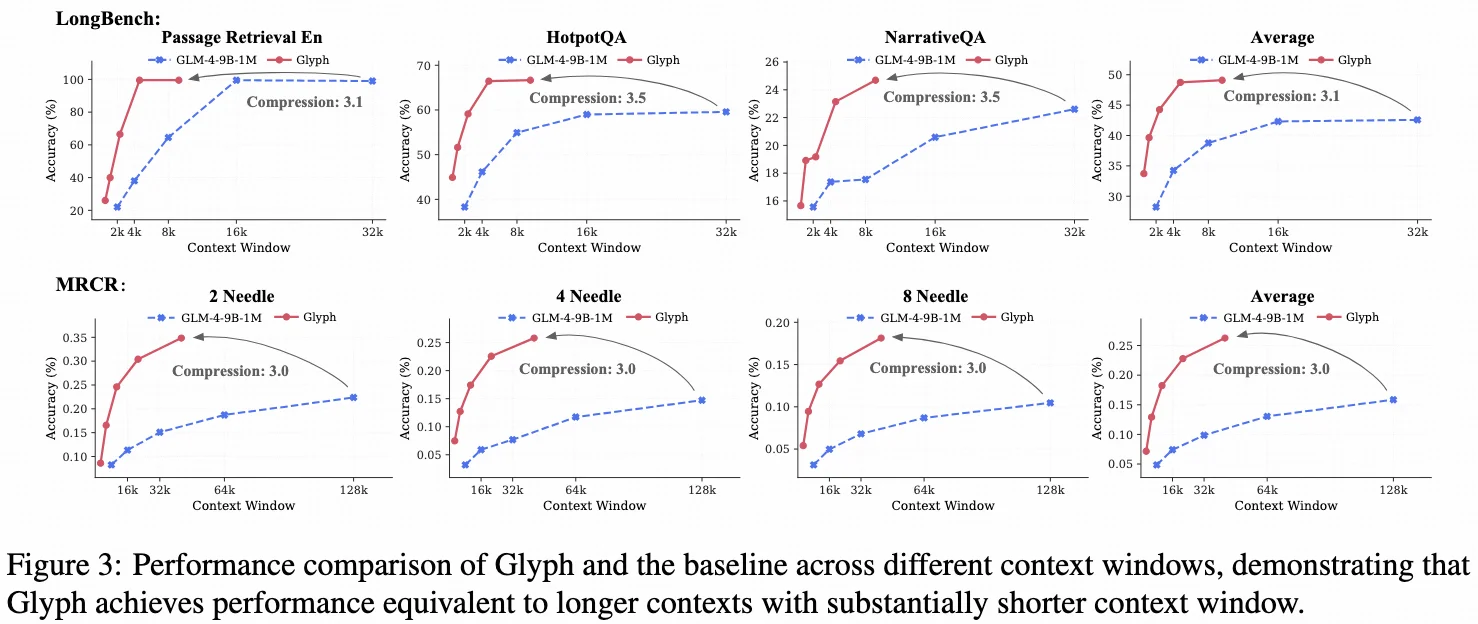
在 LongBench、MRCR 等基准上,Glyph 在 3–4× 压缩 下依然表现强劲;在极致压缩下,128K 模型也能处理百万级 token,展示出巨大的上下文扩展潜力!
更巧的是,DeepSeek-OCR 最近也在探索类似的视觉压缩思路,也算是被“平行验证”了我们的想法
也进一步说明:用 VLM 扩展长上下文确实是一条可行且潜力巨大的路径,希望未来能构建出千万token的模型
代码和模型即将开源,欢迎关注 Glyph!
#大模型 #科研学习 #学术 #deepseek #paper #深度学习与神经网络 #深度学习 #科技前沿与未来