 夜雨聆风
夜雨聆风





开源大模型微调框架 防止 过拟合 灾难遗忘


正在被 大模型微调 :过拟合、灾难遗忘
折磨的
小伙伴有福了
#信息化
#前沿AI
#人工智能
#强化学习
折磨的
小伙伴有福了
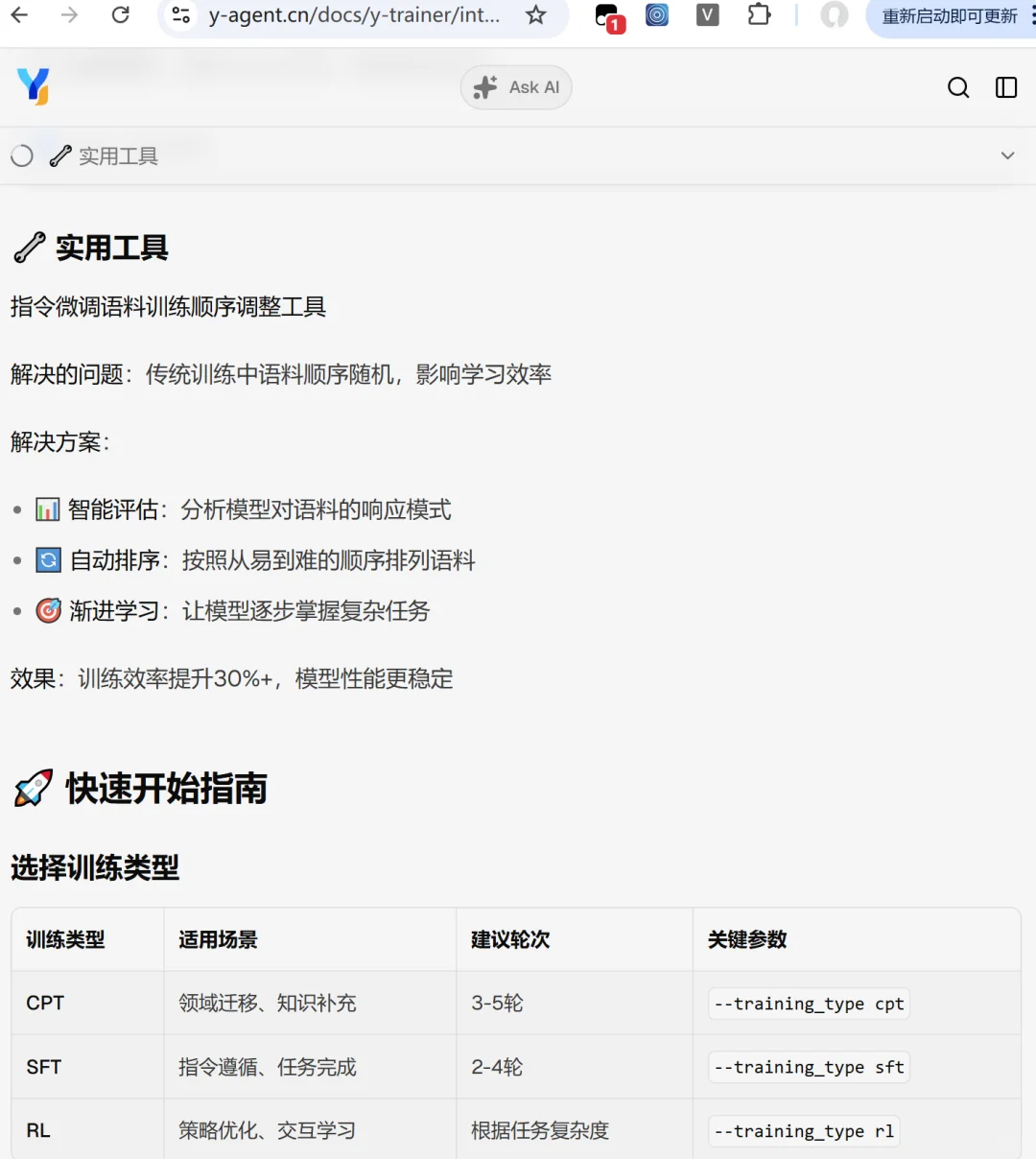
我们最近抽空开源Y-Trainer训练框架,git上可以下载源码,链接🔗在图6
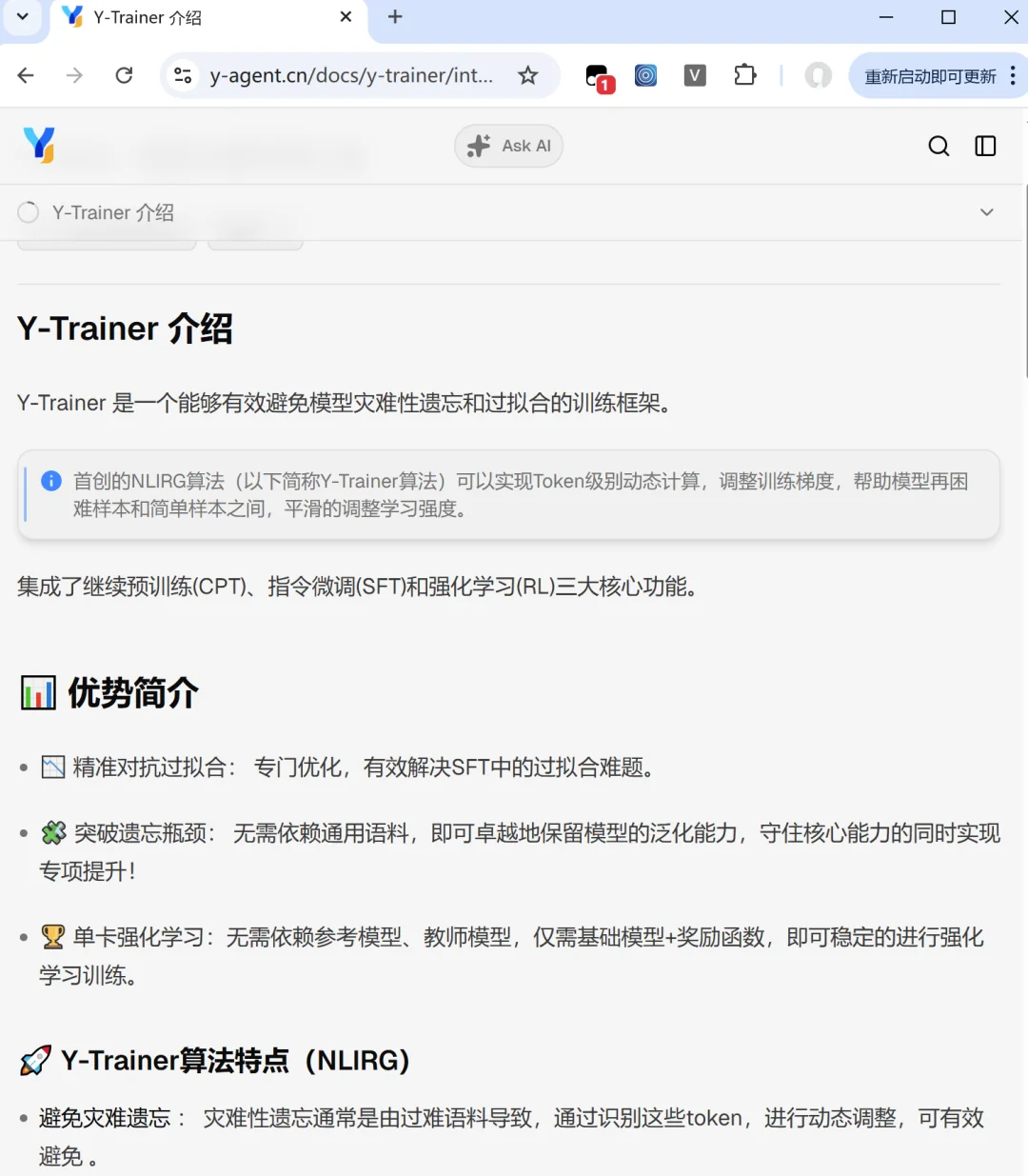
📊 简介
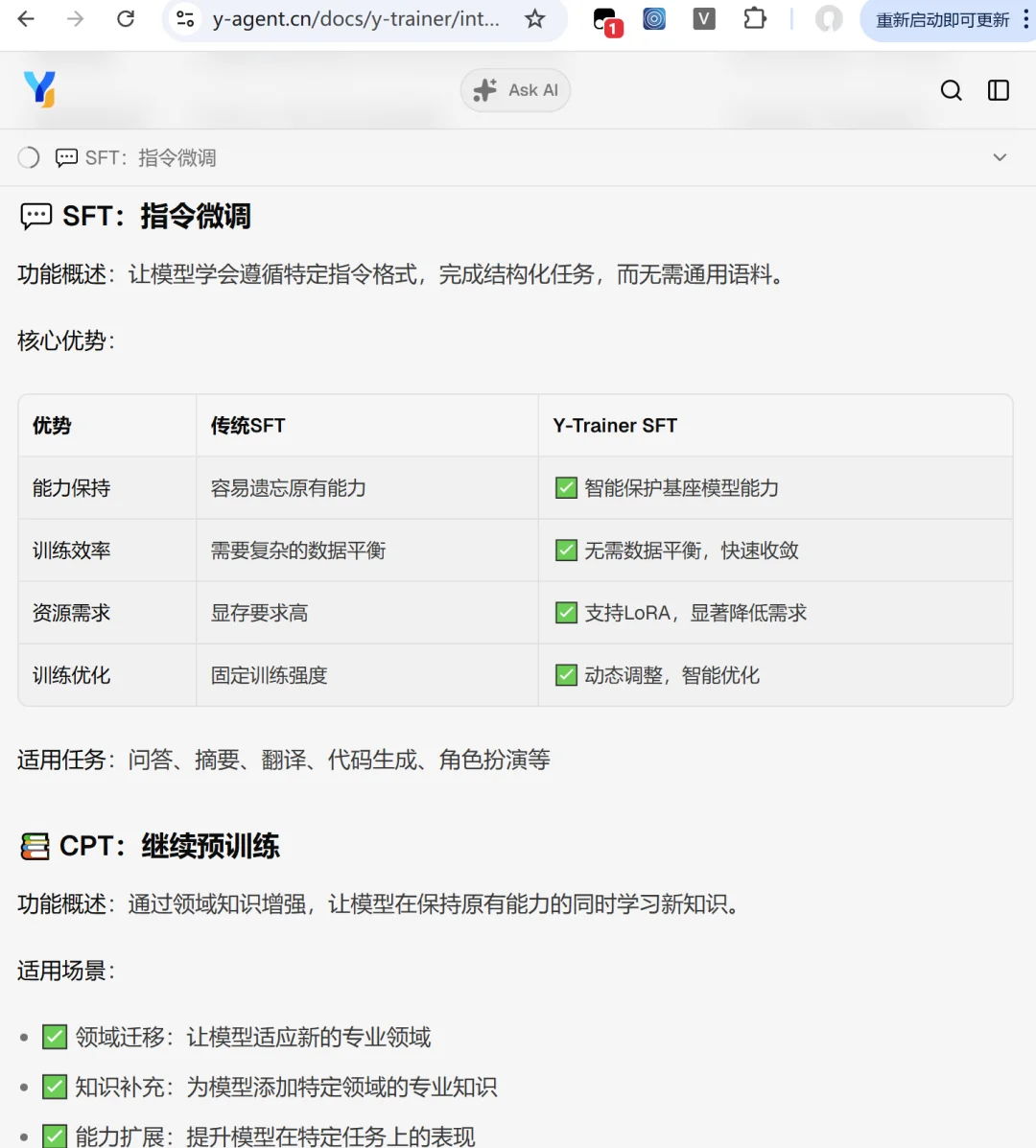
📉 精准对抗过拟合: 专门优化,有效解决SFT中的过拟合难题。
🧩 突破遗忘瓶颈: 无需依赖通用语料,即可卓越地保留模型的泛化能力,守住核心能力的同时实现专项提升!
🏆 单卡强化学习:无需依赖参考模型、教师模型,仅需基础模型+奖励函数,即可稳定的进行强化学习训练。
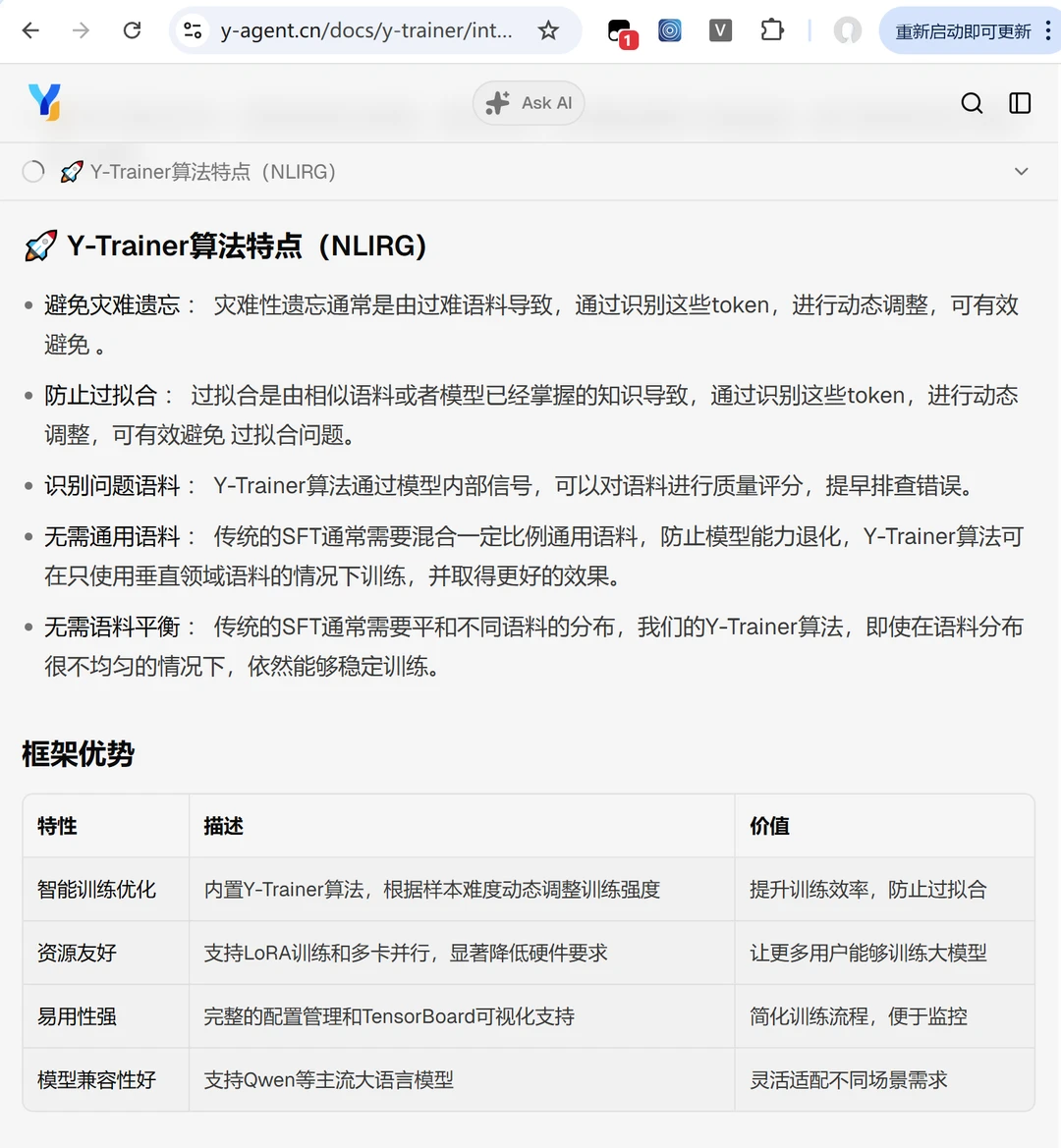
🚀 核心算法特点(NLIRG)
避免灾难遗忘 : 灾难性遗忘通常是由过难语料导致,通过识别这些token,进行动态调整,可有效避免 。
防止过拟合 : 过拟合是由相似语料或者模型已经掌握的知识导致,通过识别这些token,进行动态调整,可有效避免 过拟合问题。
识别问题语料 : Y-Trainer算法通过模型内部信号,可以对语料进行质量评分,提早排查错误。
无需通用语料 : 传统的SFT通常需要混合一定比例通用语料,防止模型能力退化,Y-Trainer算法可在只使用垂直领域语料的情况下训练,并取得更好的效果。
无需语料平衡 : 传统的SFT通常需要平和不同语料的分布,我们的Y-Trainer算法,即使在语料分布很不均匀的情况下,依然能够稳定训练。
说人话就是,通过在训练过程动态调整每个token的loss,保证梯度准确,将模型已经学会的少学或者不学,对模型太难的悠着学,精细投喂,保证训练效果。
代价就是稍微有点慢。。。
#信息化
#前沿AI
#人工智能
#强化学习
