 夜雨聆风
夜雨聆风





AutoGLM被吹上天?扒个源码:别信神话









# AutoGLM被吹上天?扒个源码后:能力有限,别信神话
## 前言
首先我是带着敬畏来写这个文章的,任何技术诞生都不一定完美,但是它能够解决或接近解决某些用户的痛点,这就已经足够。能够有人迈出第一步,已经是难能可贵的事情。对于商业活动而言,一定会被某些人无限放大它的作用。写这个文章,一是从源码角度分析找到改进的地方,二也是让那些炒作概念的人冷静一下头脑。
## 概述
open-AutoGLM 作为基于视觉语言模型的手机自动化框架,虽然在很多场景下表现出色,但仍然存在诸多**架构性**和**技术性**的局限。本文从源码层面深入分析这些限制。
## 1. 视觉理解局限
### 图像信息丢失
**原理**
在对话上下文记忆区每次处理后把最后一条图像数据移走。
**影响分析**:
– **历史盲区**: 模型无法访问历史页面的视觉信息
– **上下文断裂**: 长任务中后期决策缺乏视觉上下文
– **空间权衡**: 为节省 token 牺牲了历史视觉记忆
### 视觉模型本身的限制
**原理**
根据ADB Keyboard的键盘特征,判断已经是否激活
**核心问题**:
– **依赖三方输入法**: 必须让用户安装ADB Keyboard
– **必须手动配置**: 新输入法必须得激活,对于很多手机小白,基本重未装过三方输入法,也没用过在哪里去激活
## 2. 手动交互依赖
### Take_over 机制的限制
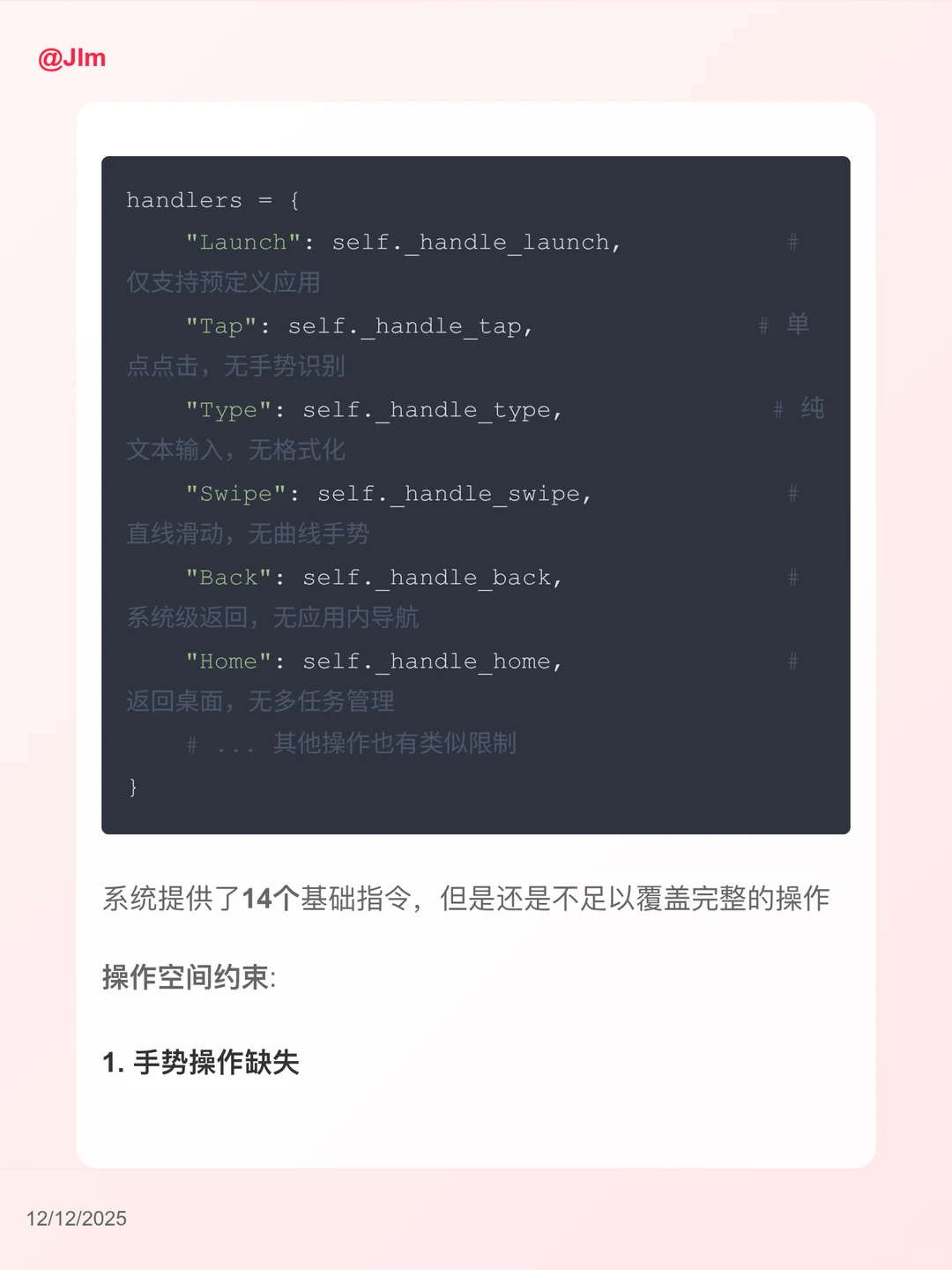
## 3. 操作指令范围限制
### 原子操作的局限性
#### 1. 手势操作缺失
#### 2. 应用操作限制
## 总结
AutoGLM 的局限性主要来源于**模型处理模式依赖**、**部分依赖人工交互**和**应用及操作原子覆盖不足**三个核心约束。这些局限在当前技术水平下是合理的,但也为适用场景及未来的改进指明了方向。
## 思考
这里智谱的视觉模型针对常用的电商和社交场景,以及部分游戏场景进行了适配。相当于是让模型“记忆”了特定APP的操作方式进行规划,但是如果希望良好的支持任意APP,是否可以针对性的训练规划用的模型或prompt上下文呢。既然第一步要启动APP。那么是否可以根据APP自动切换规划模型或规划引导上下文,从“大而全”向“专而精”方面改进呢?
