为什么每次都被APP“猜中”心思?揭秘DeepFM如何自动揪出你“想买”和“爱看”的隐藏关联
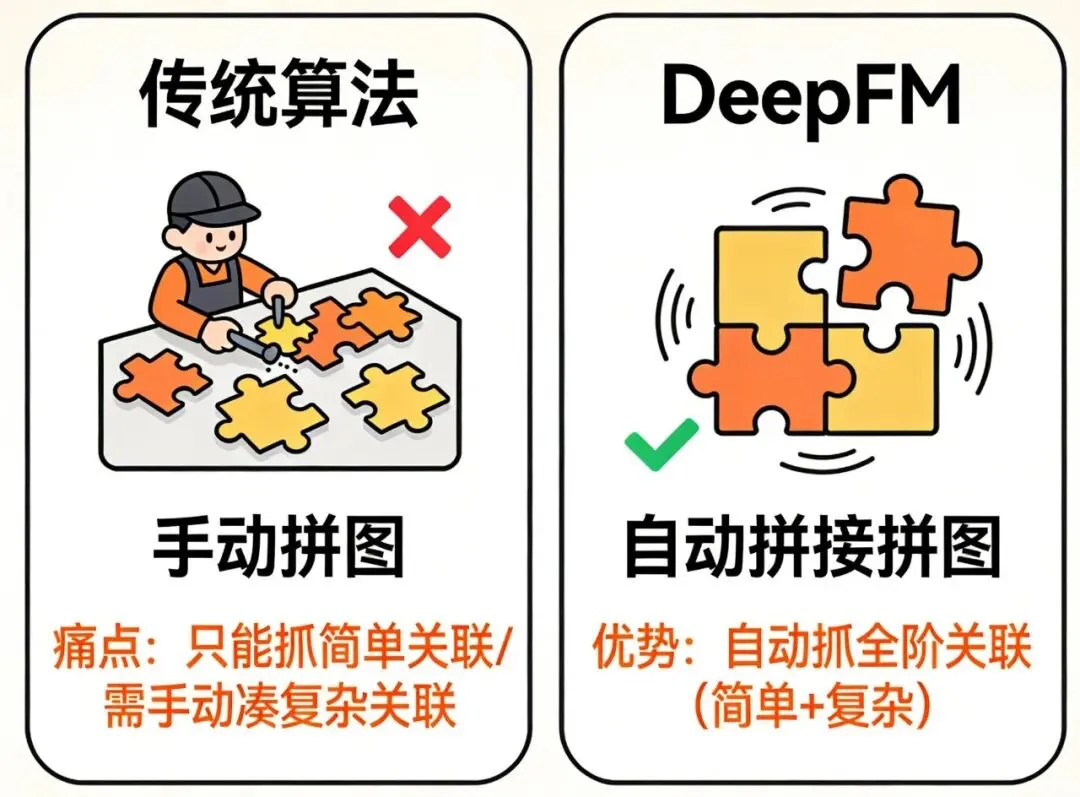
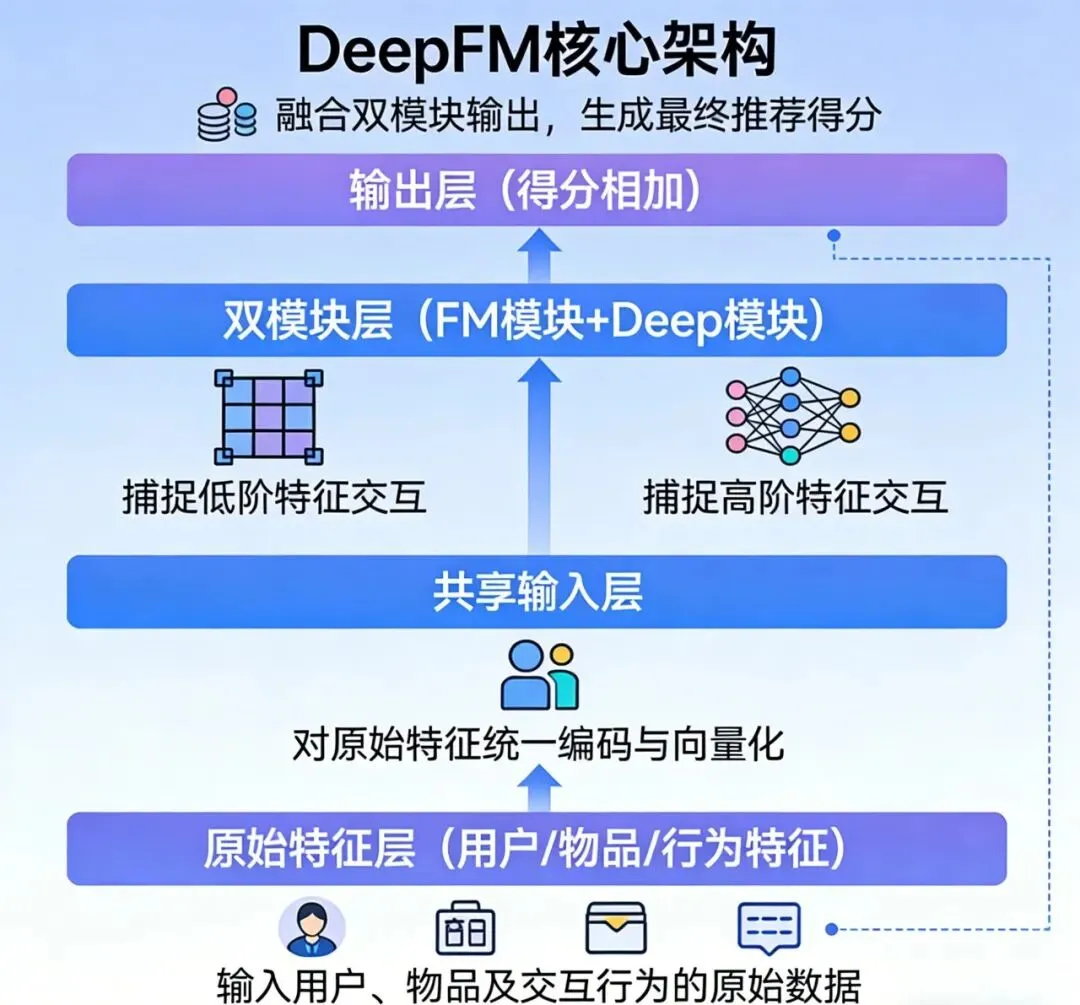
平时刷短视频、逛购物APP,是不是总被精准 “ 拿捏 ” ?刷到的都是想看的,推荐的全是想买的——其实这背后,推荐系统里藏着个大功臣:DeepFM。 很多新手一听到 “ 特征交互 ” “ 因子分解机 ” “深度学习 ” 这些词就犯怵,别怕!这篇文章全程大白话,把DeepFM拆成 “ 基础筛选+精准深挖 ” 两个简单模块,保证你不用啃文献,就能搞懂它为啥能让推荐这么准。 一、先搞懂:推荐系统的核心难题,就差“找对关联” 讲DeepFM之前,先聊个简单的:推荐系统的目标就是把对的东西推给对的人。 比如给爱喝奶茶的人推新品,给喜欢悬疑剧的人推高分片。要做到这一点,关键是找到 “ 用户特征”和 “ 物品特征 ” 的关联,这就是咱们常说的 “ 特征交互 ” 。 举个超通俗的例子: “ 25岁女性 ” (用户特征)和 “ 低糖奶茶 ” (物品特征)搭在一起,就是个超有价值的交互——大概率能判断出,这个用户会喜欢低糖奶茶。 但传统推荐算法有个致命问题:要么只能找简单的关联(比如只看性别和商品类别),要么得靠人手动凑复杂关联(比如 “ 25岁+女性+白领+低糖 ” ),不仅费时间,还容易漏关键信息。 而DeepFM的出现,就是来解决这个痛点的:不用人动手,它自己就能把 “ 简单到复杂 ” 的所有关联都找出来,还能保证推荐精度。 二、DeepFM核心原理:两个模块联手,先筛选再深挖 DeepFM的名字很好懂: “ Deep ” 是深度学习模块, “ FM ” 是因子分解机模块。核心思路超简单:让这两个模块分工合作,一个负责 “ 初步筛选”,一个负责 “ 精准深挖 ” ,联手搞定推荐。 用个比喻理解:推荐就像给你挑衣服,FM模块是导购,先根据你的基础需求(比如性别、身高)筛选出一批合身的;Deep模块是资深搭配师,再从这批衣服里,结合你的风格、场合等细节,挑出最适合你的那几件。 上一篇我们说LightGBM是给XGBoost配了高效工具包的超级助理,那DeepFM就是给树模型找了个深度学习超搭档——核心不是推翻原有逻辑,而是把因子分解机(FM)的线性建模能力和深度学习(Deep)的非线性拟合能力融合在一起,实现1+1>2的效果。 ✅ 通俗理解:DeepFM = FM模块 + Deep模块 + 共享输入层 还是用「电商商品推荐」举例,DeepFM的工作逻辑就像这样: 基础逻辑:一边用FM模块捕捉简单的低阶交互(比如25岁女性+连衣裙),一边用Deep模块捕捉复杂的高阶交互(比如25岁白领女性+月薪8k+法式连衣裙+近30天浏览3次); 核心优势:不用手动设计任何交互特征,两个模块共享同一批原始特征,自动完成从低阶到高阶的全阶交互捕捉; 最终输出:把两个模块的预测得分相加,得到最终的用户偏好得分,得分越高越优先推荐。 DeepFM(Deep Factorization Machine)是融合因子分解机(FM)和深度学习(Deep Neural Network)的端到端推荐算法,通过共享输入层让FM模块捕捉低阶线性交互特征,Deep模块捕捉高阶非线性交互特征,无需人工进行特征工程,就能高效处理高维稀疏数据,在推荐系统、广告点击率预测等场景中广泛应用。 一句话核心:DeepFM = FM的线性交互能力 + Deep的非线性拟合能力 + 自动特征交互,兼顾可解释性和高精度。 1. 模块一:FM模块——抓简单关联,打好基础 FM全称是因子分解机,它的活儿很简单:专门找 “ 两两之间的简单关联 ” (也就是低阶特征交互),比如 “ 用户年龄+商品类别 ” “ 性别+价格 ” 。 为啥非要它来打基础?因为很多推荐的核心逻辑,都藏在简单关联里。比如 “ 男性更爱买运动装备 ” “ 学生党偏爱低价商品 ” ,先把这些找出来,才能缩小推荐范围,避免瞎推荐。 这里给个简化的核心公式,不用怕,看逻辑就行: 大白话翻译:FM算出来的基础得分,就三件事加起来: :基础偏置项(比如默认给所有商品一个基础分,避免极端情况); :单个特征的重要性(比如 “ 女性 ” 这个特征对 “ 买连衣裙 ” 的影响程度); :两个特征的关联价值(比如 “ 25岁女性 ” 和 “ 低糖奶茶 ” 的匹配度)。 通俗比喻:FM模块就像餐厅的前台接待,能快速记住每个顾客的基础需求(比如爱吃辣、不吃香菜),把符合基础需求的菜品先筛选出来,打好后续推荐的基础。 关键是最后一项:它能自动算出任意两个特征的关联,不用人手动设置,这就比传统算法省了大功夫 。 2. 模块二:Deep模块——抓复杂关联,挖深层需求 FM只能找两两关联,但用户的真实需求往往更复杂。比如 “ 25岁上班族女性+月薪8k+周末+高颜值+低糖奶茶 ” ,这种多个特征凑在一起的复杂关联(高阶特征交互),FM就搞不定了,这时候Deep模块就该上场了。 Deep模块就是咱们熟悉的神经网络,它的本事是 “ 非线性变换 ” ——能把多个特征揉在一起,挖出藏在背后的深层需求。比如上面那个例子,它能精准判断出:这个用户周末大概率想买一杯高颜值的低糖奶茶,这些深层需求是FM挖不出来的。 这里有个关键细节:两个模块用的是同一批原始特征(也就是共享输入层)。好处很明显:不用重复处理数据,省时间;还能保证两个模块的判断标准一致,不会出现 “ 导购选的是休闲装,搭配师按正装挑 ” 的混乱情况。 3. 最终结果:两个得分加起来,精准排序 FM算出基础得分,Deep算出深层需求得分,把这两个分加起来,就是用户对这件商品的 “ 偏好总分 ” 。得分越高,说明用户越可能喜欢,推荐系统就把这件商品排在前面。 DeepFM的优势全在双模块融合上,这也是大厂推荐系统面试的高频考点。我们把两个核心模块拆解开,每个模块都用电商推荐案例+通俗比喻讲透,再搭配核心逻辑,新手也能理解原理! ✨ 模块1:FM模块——捕捉低阶交互,打好推荐基础 传统树模型处理低阶交互时,要么需要手动组合特征(比如把用户年龄和商品类别拼在一起),要么容易遗漏关键的基础交互。FM模块的作用就是自动捕捉所有两两低阶交互,不用人工干预,还能保证推荐的基础精度。 特征嵌入:把高维稀疏的原始特征(比如用户ID、商品ID、性别、类别)转换成低维稠密的隐向量(可以理解成给每个特征贴个简洁的标签); 计算交互:通过隐向量的内积计算,自动算出任意两个特征的交互价值,比如25岁女性和连衣裙的交互价值是0.8(高价值),25岁男性和连衣裙的交互价值是0.2(低价值); 输出得分:汇总所有单个特征的权重和两两交互的价值,得到低阶交互得分,作为推荐的基础依据。 ✨ 模块2:Deep模块——捕捉高阶交互,挖透深层偏好 FM模块只能处理两两交互,但用户的真实偏好往往更复杂,比如25岁白领女性+月薪8k+周末+法式连衣裙+高颜值+低价这种多特征组合的高阶交互,传统树模型和FM都搞不定,这就需要Deep模块登场了。 共享嵌入层:和FM模块共用同一个特征嵌入层,保证特征信息的一致性(不用重复处理特征,提升效率); 非线性变换:把低维稠密的隐向量输入到多层神经网络中,通过激活函数(比如ReLU)进行非线性变换,自动捕捉多特征的高阶交互; 输出得分:经过多层神经网络的计算,输出高阶交互得分,反映用户的深层潜在偏好。 比如在电商推荐中,Deep模块能捕捉到25岁白领女性+月薪8k+周末+法式连衣裙这个高阶交互的价值,判断出用户在周末更倾向于购买高性价比的法式连衣裙,而这些深层偏好是FM模块和传统树模型都难以挖掘的。 通俗比喻:Deep模块就像餐厅的资深厨师,在前台筛选出基础菜品后,能根据顾客的深层需求(比如周末聚餐要性价比高、颜值高),精准搭配出最符合需求的套餐。 很多新手会问,为什么要让两个模块共享输入层?其实原因很简单:一是避免重复处理特征,减少计算量,提升效率;二是保证两个模块的特征信息一致,不会出现FM模块认的特征和Deep模块认的特征不一样的情况,确保最终推荐结果的稳定性。 三、落地案例:电商推荐里,DeepFM是怎么干活的? 光说理论太抽象,咱们拿电商推荐的真实场景举例,看看DeepFM全程是怎么操作的。 物品特征:连衣裙、法式风格、299元、销量1000+; 自动算出 “ 28岁女性+连衣裙 ” “ 白领+299元商品 ” “ 浏览过连衣裙+推荐连衣裙 ” 这些简单关联的价值,快速筛选出一批符合基础需求的法式连衣裙,排除掉明显不匹配的(比如男士外套、高价奢侈品)。 进一步挖深层需求,算出 “ 28岁白领女性+法式连衣裙+299元+近30天浏览3次 ” 这个复杂关联的价值,判断出用户大概率想要“高性价比的法式连衣裙”。 把FM的基础得分和Deep的深层得分相加,从所有候选连衣裙里挑出得分最高的3-5件,推给这位用户——这就是你刷APP时看到的 “ 精准推荐 ” 。 四、DeepFM为啥能成大厂标配?4个核心优势 1.不用手动凑特征:全阶关联(简单+复杂)自动抓,省了大量人工成本,还不会漏关键信息; 2.效率高:两个模块共享数据,不用重复处理,能适配大规模数据(百万级、千万级用户); 3.精度高:结合了FM的基础判断和Deep的深层挖掘,比传统算法推荐更准; 4.好落地:模型结构不复杂,有成熟的开源框架(比如TensorFlow、PyTorch)支持,新手也能快速上手跑通案例。 五、新手入门:3步快速掌握DeepFM 1.先懂逻辑再啃公式:不用一上来就死磕复杂推导,先搞明白 “ FM筛选+Deep深挖 ” 的分工逻辑,再慢慢看公式细节; 2.跟着案例跑一遍:找个简单的电商推荐数据集(网上很多公开数据),用开源代码跑一遍,直观感受数据怎么输入、模块怎么工作、结果怎么输出; 3.对比着学更清晰:把DeepFM和之前讲的XGBoost、GBDT对比,重点记它的优势——处理高维数据、自动抓特征交互,这是它在推荐场景的核心竞争力。 六、一句话总结:DeepFM到底是什么? DeepFM就是推荐系统的 “ 精准匹配小能手 ” ,靠 “ FM模块找简单关联、Deep模块挖深层需求 ” 的组合,不用人工凑特征,就能高效、精准地给用户推喜欢的东西。 也正因为它解决了传统算法 “ 费人工、漏关联 ” 的痛点,现在成了大厂推荐系统的核心算法——你刷到的每一条精准推荐,大概率都有它的功劳。 七、DeepFM的核心优势与缺点(实战必看) 作为高维数据建模的王牌,DeepFM的优势很突出,但也有需要注意的短板,整理成大白话版,方便你实战选择: 自动捕捉全阶交互:不用人工设计任何交互特征,从低阶两两交互到高阶多特征交互全覆盖,大幅降低特征工程成本; 高维稀疏数据适配性强:通过嵌入层把高维稀疏特征转换成低维稠密特征,完美解决树模型处理文本、用户ID等特征的痛点; 端到端训练:从原始特征输入到最终预测得分输出,全程自动化,不用分阶段处理,落地效率高; 精度高:融合线性和非线性建模能力,比单一树模型或深度学习模型的预测精度更高,适合核心业务场景。 训练速度较慢:相比LightGBM,深度学习模块需要更多的计算资源,训练时间更长,不适合对实时性要求极高的场景; 可解释性一般:虽然FM模块的低阶交互可解释,但Deep模块的高阶交互是黑箱,难以说清具体是哪些特征组合影响了结果; 参数调优复杂:深度学习模块的参数(比如隐藏层节点数、学习率、批次大小)比树模型多,需要更多的调优经验,新手上手门槛略高; 小数据集易过拟合:在小数据集(万级以下)上,深度学习模块容易过度拟合训练数据,导致泛化能力下降。 八、本期核心知识点+逻辑总结(收藏版) 本期内容聚焦高维稀疏数据建模,只要抓住树模型+深度学习强强联合这个核心,就能很容易记住所有知识点: DeepFM是融合FM和深度学习的端到端算法,核心是自动捕捉全阶特征交互,不用手动设计特征; 2大核心模块:FM模块捕捉低阶线性交互,打好基础;Deep模块捕捉高阶非线性交互,挖透深层偏好; 高维稀疏数据适配性强、精度高,适合电商推荐、广告CTR预测等场景,小数据集需注意防过拟合,实时场景需权衡速度。 共享嵌入层:把高维稀疏特征转换成低维稠密隐向量,供两个模块共用; 双模块并行:FM算低阶交互,Deep算高阶交互,各自发挥优势; 得分融合:把两个模块的得分相加,得到最终预测结果,兼顾基础精度和深层偏好。 九、互动思考 结合本期内容,思考一个小问题:如果你是某个购物APP的工程师,在 商品推荐 场景(用户逛得快,选择多),你可能更倾向用哪个?为什么?是更需要 LightGBM 的闪电速度,快速抓住用户一闪而过的兴趣?还是更需要 DeepFM 的深度洞察,去挖掘 “ 买咖啡机的人,大概率也会看精致咖啡杯 ” 这种复杂关联? ❤️ 关注我(硬核 AI 通俗讲),从KNN到DeepFM,从原理到实战,机器学习入门的每一步都走得稳稳当当,下期继续解锁硬核干货,我们不见不散~
 夜雨聆风
夜雨聆风