 夜雨聆风
夜雨聆风





Claude code失忆不要慌,记忆插件来帮忙,拯救AI金鱼脑,AI编程没烦恼
防止迷路,请点击上方蓝色字 AI陆的研习社 -> 右上角三个点… -> 设为星标⭐
我们的口号是:
AI打工我躺平,周报它写我刷屏。方案它改我追星,功劳它攒我躺赢。
让我们普通人抓住AI的红利

各位同学久等了,这次文章发布的间隔实在是有点长,这里给大家赔个不是。
你要问最近老陆我拖更这么久在干吗?当然是在帮大家踩坑,一直在找claude code能用的持久记忆插件。
然后还彻底掉坑里了,刚刚才爬上来。
爬上来就马上发文章给大家避坑。
记忆插件的作用
这里我先说说记忆插件是干什么的,这就要从我们平时实际使用AI编程的情形讲起。
很多时候,AI编程中的最大痛点在于,怎么让AI记住对话内容。别惊讶,因为AI本质上就是个金鱼,它的记忆容量一般只有200K左右,也就是大部分支持AI编程的大模型的上下文空间。
当然有人会说,这不对啊,我们使用claude code时,它在对话中会一直记得一开始的事情。
那是因为claude code针对这个问题,在背后做了一系列的工作。
claude code中的CLAUDE.md会保存本项目中的编程规则,上下文压缩功能会在上下文窗口已满,需要开启新的上下文时,自动对前一个上下文内容进行总结(压缩)。当前对话的上下文也会在后台被保存到本地的文件中,我们可以通过/resume指令找回来。
所以我们会认为AI能记住所有的对话内容,然而这其实是错觉。实际上claude code所做的所有努力都只能缓解这个问题。
CLAUDE.md不可能记住所有内容,上下文压缩也会丢失一部分信息的细节。只要AI编程用得足够频繁,你一定会发现,AI不可能记得一个小时前喂给它的资料全貌、编程规则细节。 这种时候,我们只能一遍遍地告诉AI,把这些信息重新喂给它。这个工作特别繁琐,低效,浪费生命。
更可怕的是,上下文窗口一旦满了,claude code就要压缩上下文,或者需要我们手动清空上下文,然后我们发现AI失忆了,刚刚喂文档的工作白干了,我的天!
大家都不满意这种状况,自然而然的,有人开始给AI编程工具开发持久记忆插件。
这些插件的原理这里就不展开了,基本原理就是AI来识别、抽取、总结对话内容,用数据库来存储这些内容。
避坑
相关背景就先说到这里,关于持久记忆插件的选择,首先我在这里就要给大家避坑。
首先排除最近有很多人推荐的claude-mem,这就是个巨坑!
不要安装!不要安装!不要安装!
重要的事情说三遍。
安装指令确实超级简单,就两条,这里我就不放了,反正国内网络没法用。
好不容易挂梯子,下源码包,手动挂载,结果一堆报错。找了官方资料,一点也没用。
这玩意儿就是个半成品,这坑我进去过了,搞了一个多星期没爬上来,大家绕过吧。
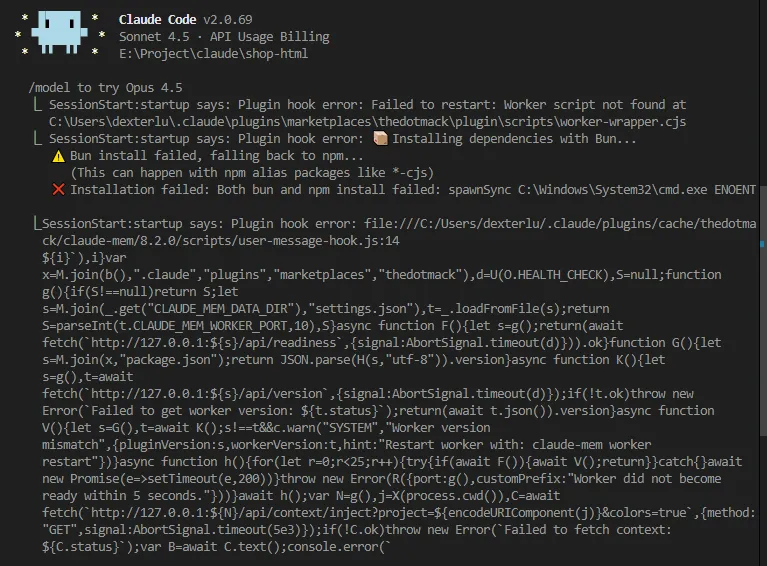
好在我又找到个claude code能用的外挂记忆插件:mcp-memory-service。
mcp-memory-service介绍
github上的项目地址:
https://github.com/doobidoo/mcp-memory-service
Stars 1.1K
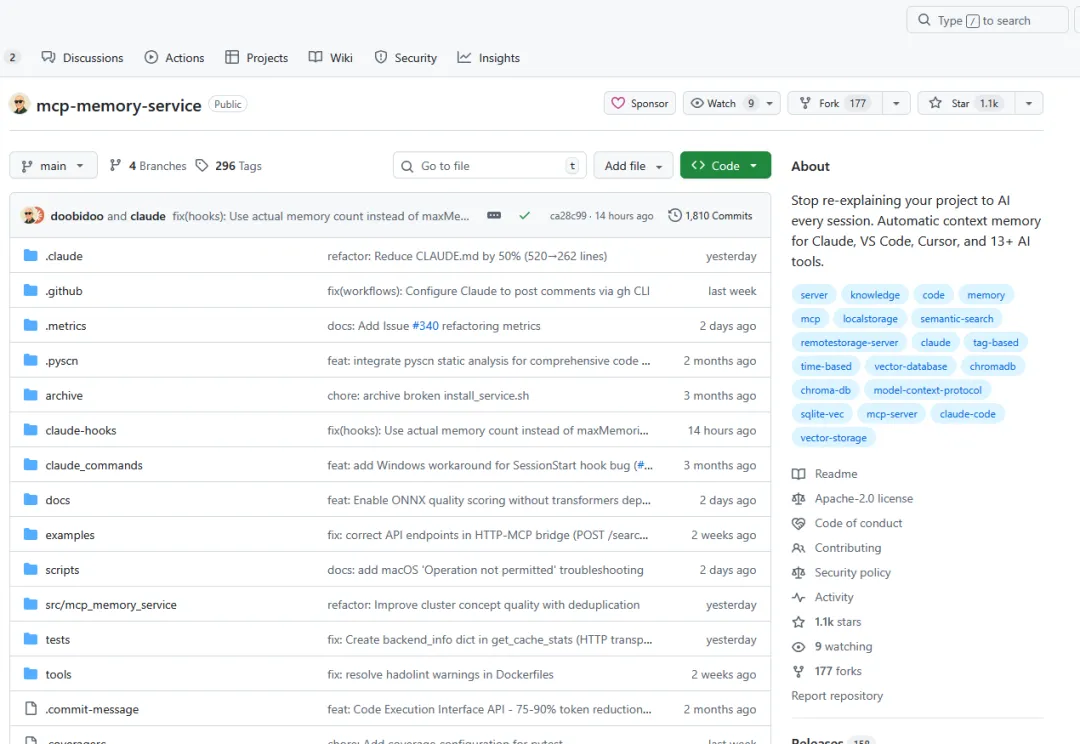
东西确实不错,就是文档写得真的不敢恭维,信息很分散,这也算是个小坑吧,为了搞明白安装流程就坑了我一周时间 ( ´•̥ו̥` )。
这个插件确实是可以正常工作的,功能比claude-mem强,还支持多种AI编程工具,而且人家还是开源免费的,更新超级快,大概几天一更(比我快多了),也就没什么好抱怨的了。
这工具强在哪里呢,给大家看看。
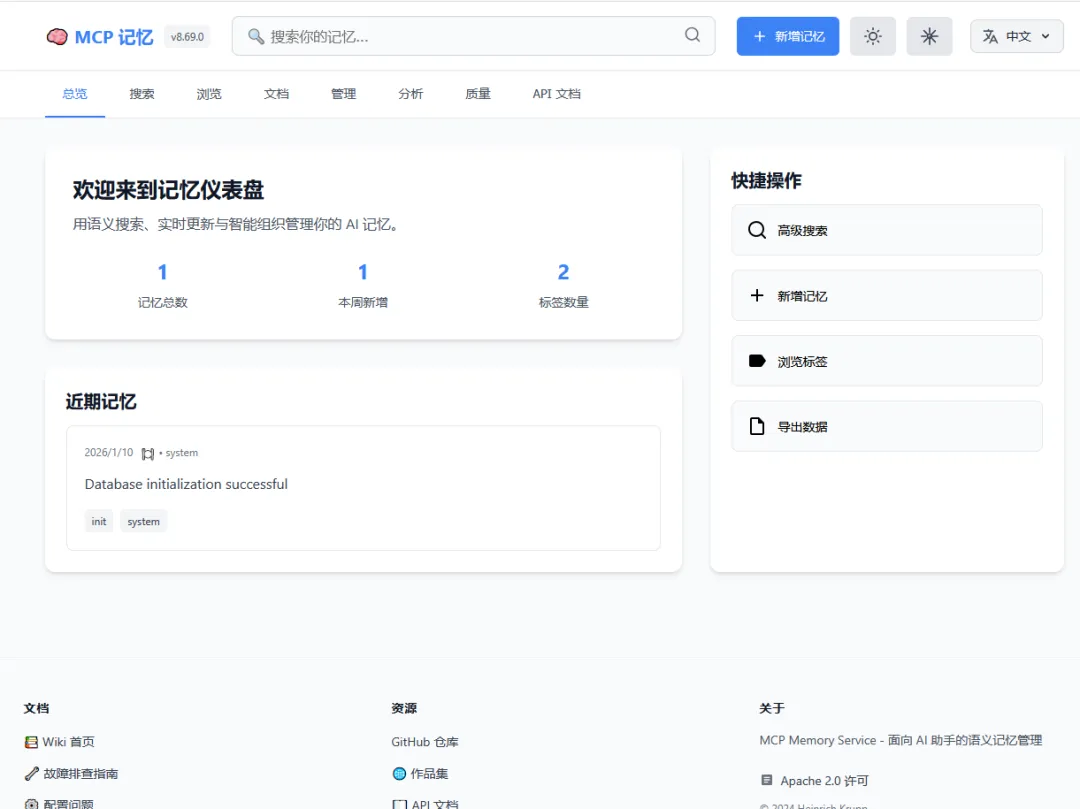
它不光可以自动捕获我们和AI的对话(这是基本功能),在web端的管理页面还可以管理所有的对话记忆(额外功能)
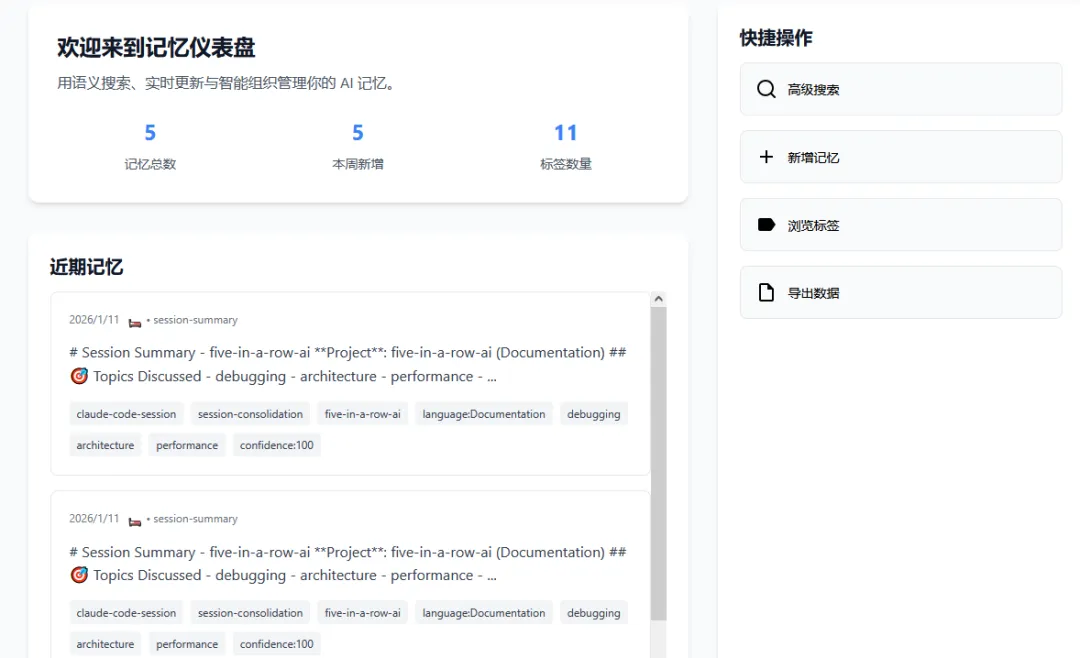
比如手动添加记忆
搜索记忆
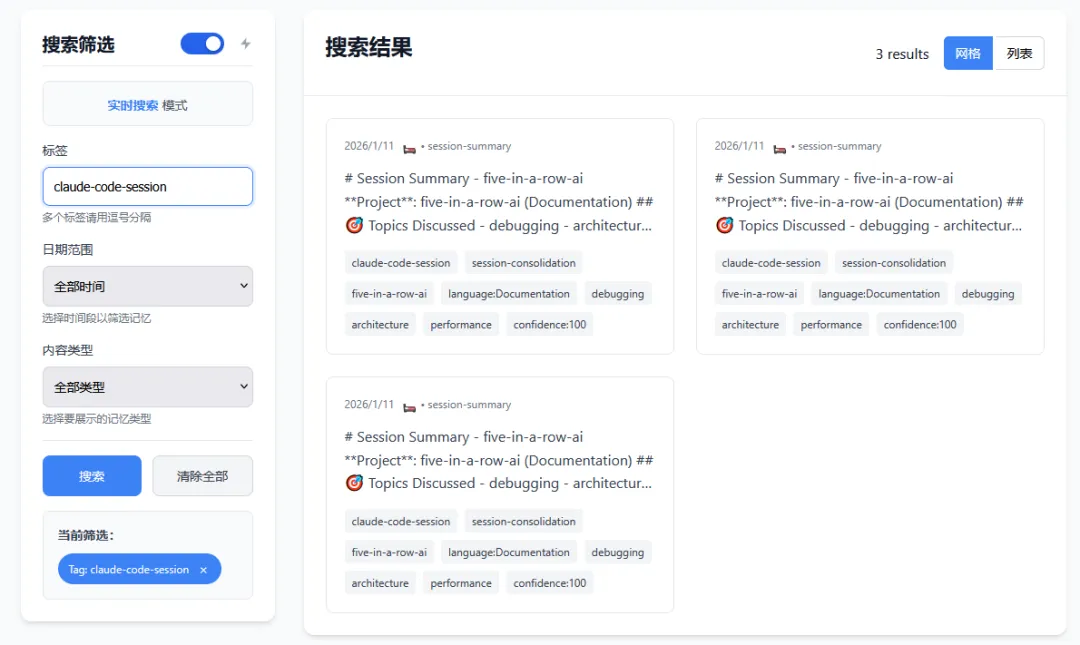
还能直接导入文档,比如软件包手册,开发文档等内容。
这个功能真的是瞄准了AI编程最大的痛点来设计的,我们甚至不用在和AI的对话上下文中输入这些信息。有相关经验的同学肯定知道,让AI来阅读这些东西有多消耗token,AI阅读文档也很费时间,这能帮我们省下多少钱啊。
有了这个功能,感觉钱包和寿命都被节省下来了。
功能介绍就到这里,具体怎么用,大家可以自行探索。我马上来讲讲怎么安装这款工具。
安装流程
下载源代码
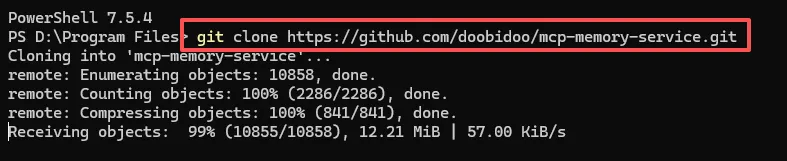
第一步自然是下载源代码,网络条件好的同学可以直接从github克隆项目。
# 克隆仓库
git clone https://github.com/doobidoo/mcp-memory-service.git
#然后进入克隆的项目中
cd mcp-memory-service
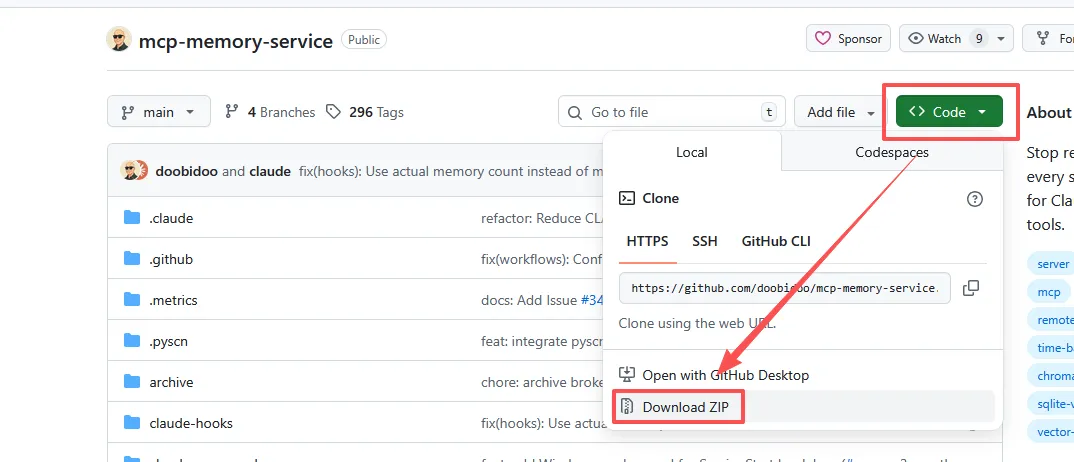
网络情况不好的大部分同学,比如我(原因你懂的),可以点击页面上的“code”按钮,选择下拉菜单中的Download ZIP,直接下载源代码压缩包。
注意:
-
克隆仓库的文件夹或者解压缩后的文件路径上不能有中文,文件夹名称中也不能带空格 -
启动终端工具后,必须进入源代码目录,我们后续的操作一定要在这个源代码目录中进行

编译和安装服务
然后启动安装脚本,脚本会自动检查环境
python .\install.py
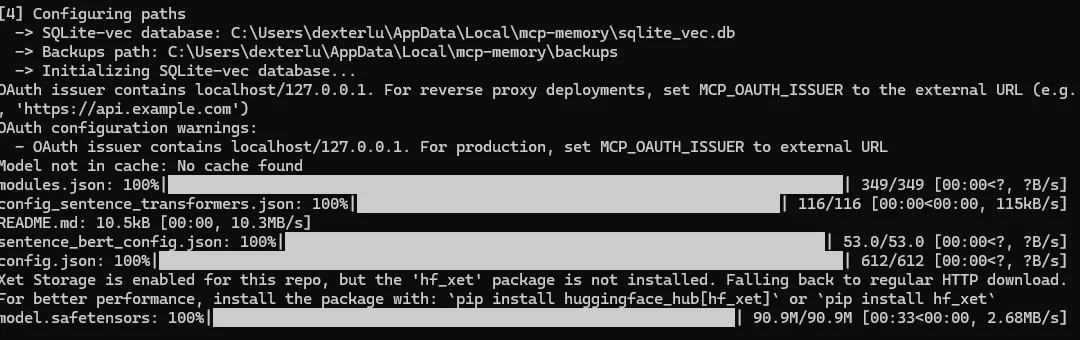
要注意的是,安装程序探测到我们克隆了项目,它会以为我们是开发人员,建议我们用EDITABLE模式安装。但是我们只是使用者,所以我们看到这个提问的时候要输入”N”(NO)。
之后,在安装的中途会有配置方面的提问,如果需要适配多种不同的AI编程工具,需要选“y”。

安装脚本有很多参数可以选,我们可以用“-h”参数查看
python .\install.py -h
这里我把相关信息用AI翻译了一下,专业名词也做了说明,供大家参考。大家也不用担心参数该怎么选,安装时关于配置方面的参数,可以在配置文件种进行设置,达到同样的效果,一些软件包也可以后面分步骤安装。
用法:install.py [-h] [--dev] [--chroma-path CHROMA_PATH] [--backups-path BACKUPS_PATH] [--force-compatible-deps]
[--fallback-deps] [--storage-backend {cloudflare,sqlite_vec,hybrid,auto_detect}] [--skip-pytorch]
[--use-homebrew-pytorch] [--force-pytorch] [--legacy-hardware] [--server-mode] [--enable-http-api]
[--migrate-from-chromadb] [--configure-claude-code] [--help-detailed] [--generate-docs]
[--setup-multi-client] [--skip-multi-client-prompt] [--install-claude-commands]
[--skip-claude-commands-prompt] [--non-interactive]
安装 MCP Memory Service
选项:
-h, --help 显示此帮助信息并退出
--dev 以开发模式安装
--chroma-path CHROMA_PATH
ChromaDB 存储路径
--backups-path BACKUPS_PATH
备份存储路径
--force-compatible-deps
强制使用兼容版本的 PyTorch (2.0.1) 和 sentence-transformers (2.2.2)
--fallback-deps 使用回退版本的 PyTorch (1.13.1) 和 sentence-transformers (2.2.2)
--storage-backend {cloudflare,sqlite_vec,hybrid,auto_detect}
选择存储后端:cloudflare (生产云环境), sqlite_vec (本地开发), hybrid
(生产环境+本地同步) 或 auto_detect (自动检测)
--skip-pytorch 跳过 PyTorch 安装,改用 ONNX 运行时配合 SQLite-vec 后端
--use-homebrew-pytorch
使用现有的 Homebrew PyTorch 安装而非 pip 版本
--force-pytorch 强制安装 PyTorch(即使使用 SQLite-vec 后端,覆盖自动跳过行为)
--legacy-hardware 为旧硬件优化安装(2013-2017 年 Intel Mac 设备)
--server-mode 为服务器/无头部署安装(最小化 UI 依赖)
--enable-http-api 启用 HTTP/SSE API 功能
--migrate-from-chromadb
将现有 ChromaDB 安装迁移到选定的后端
--configure-claude-code
自动配置 Claude Code MCP 集成(应用优化设置)
--help-detailed 显示详细的硬件特定安装建议
--generate-docs 为当前硬件生成个性化设置文档
--setup-multi-client 配置多客户端访问(支持任何兼容 MCP 的应用:Claude, VS Code, Continue 等)
--skip-multi-client-prompt
跳过多客户端设置的交互式提示
--install-claude-commands
安装用于记忆操作的 Claude Code 命令
--skip-claude-commands-prompt
跳过 Claude Code 命令的交互式提示
--non-interactive 以非交互模式运行(所有提示使用默认值)
### 专有名称解释
- **PyTorch**:开源深度学习框架,提供张量计算和动态神经网络,广泛用于AI研究和部署。
- **sentence-transformers**:Python库,用于生成文本嵌入向量,支持语义搜索和相似度计算。
- **Homebrew**:macOS/Linux包管理器,通过命令行安装软件,简化依赖管理。
- **ONNX**:开放神经网络交换格式,实现不同AI框架间模型的互操作和部署优化。
- **SQLite-vec**:SQLite的向量搜索扩展,支持局部敏感哈希(LSH)算法实现高效相似性查询。
- **ChromaDB**:轻量级向量数据库,专为AI应用设计,提供嵌入存储和语义检索功能。
- **Claude**:Anthropic开发的AI助手,支持代码理解、多轮对话和文件分析等高级功能。
- **HTTP/SSE**:服务器发送事件技术,基于HTTP协议实现服务器向客户端的单向实时数据推送。
配置参数
安装完毕后,让我们对软件进行配置,根据软件手册中的信息,我们自己的配置文件名称必须是.env。
在我们下载的mcp-memory-service源代码包里面,自带一个名叫.env.example的配置范例。手册上说我们可以参考里面的内容来写自己的配置
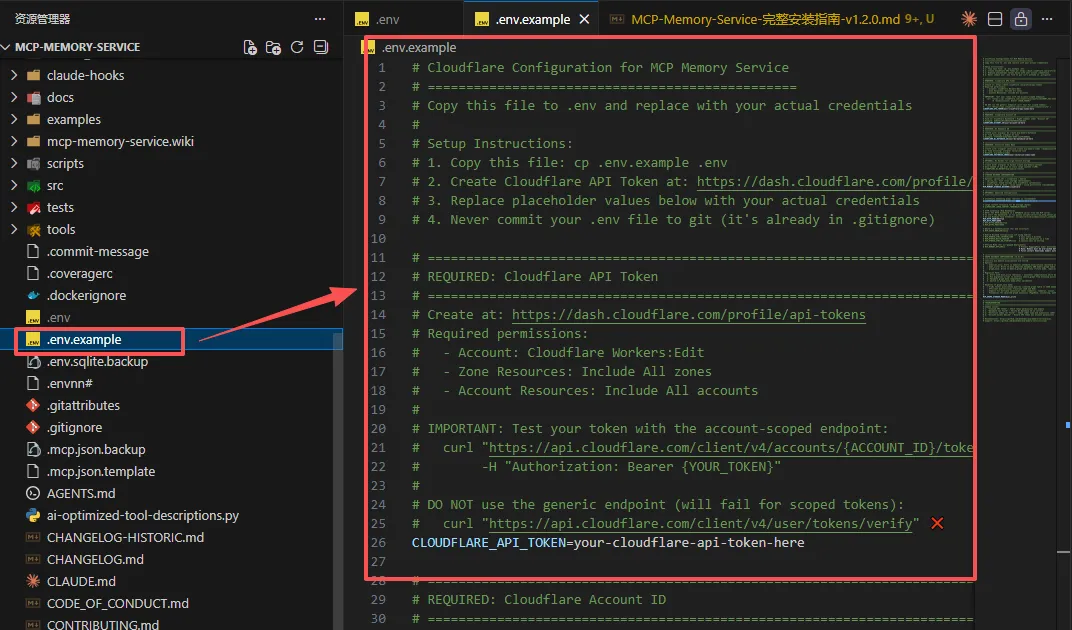
实际上这个配置文件样板内容不全,而且是全英文的,不太好用。
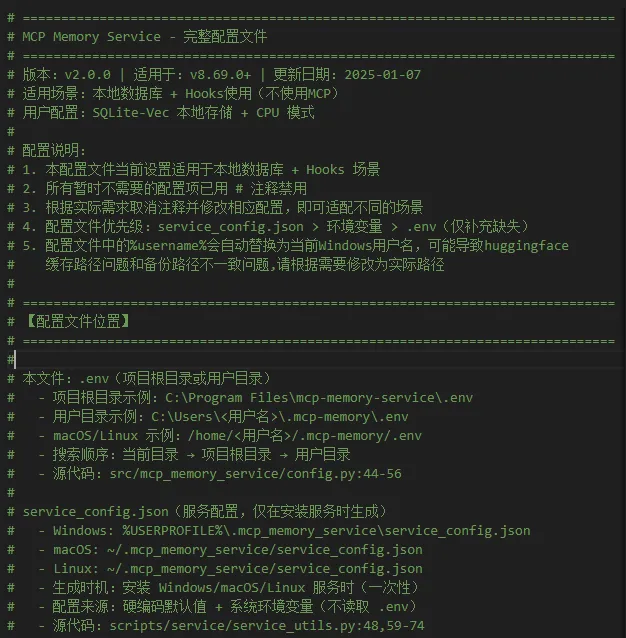
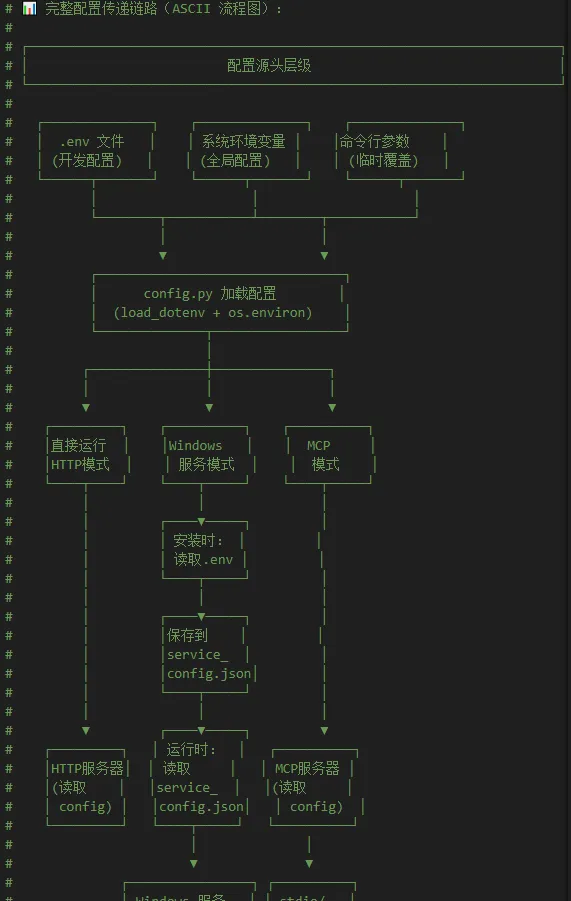
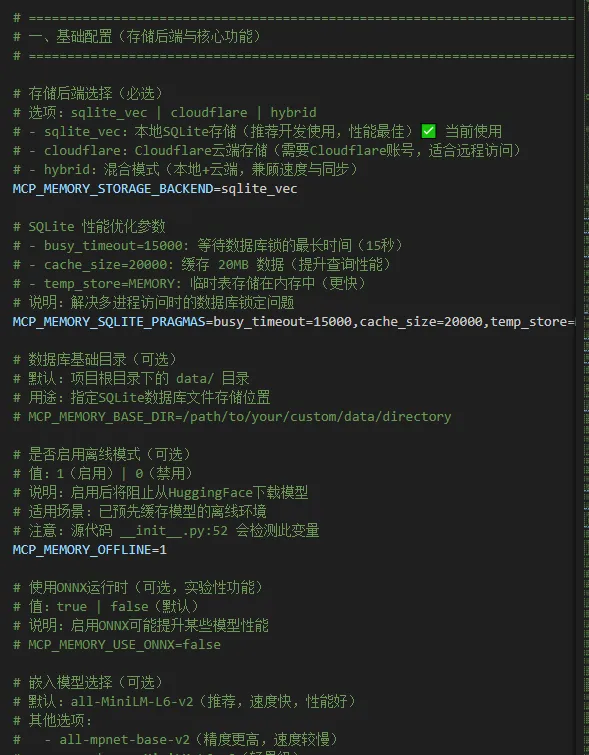
这里我给大家提供一份AI帮我写的配置文件模板:.env.template,内容比较全面,其中分类罗列了所有可选的设置,还有相关的详细中文说明。由于文件内容太长,这里我就不全部贴出来了,喜欢的小伙伴可以直接从我提供的链接下载。
通过网盘分享的文件:自制工具和配置模板
链接:
https://pan.baidu.com/s/1anT2qKxEYLvs_MkRoUhLQA?pwd=k6vv 提取码: k6vv
给大家预览一下一部分内容
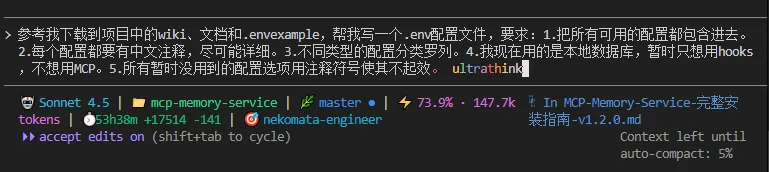
如果你要问我这种文档如何生成,我这里提供相关提示词供大家参考。
参考我下载到项目中的wiki、文档和.envexample,帮我写一个.env配置文件,要求:
1.把所有可用的配置都包含进去。
2.每个配置都要有中文注释,尽可能详细。
3.不同类型的配置分类罗列。
4.我现在用的是本地数据库,暂时只想用hooks,不想用MCP。
5.所有暂时没用到的配置选项用注释符号使其不起效。
当然,也不是一次就能达到这种效果,如果你感觉不满意可以多次对话,提出具体修改要求,迭代几次就可以了。
比如一开始我没有让AI从源代码中进行核实,想起来这个问题后,我让它再次进行核实。

言归正传,咱们继续说安装软件的事。
我们先在.env中配置这几个选项,保证服务可运行即可:
# - sqlite_vec:本地SQLite存储(推荐开发使用,性能最佳)
MCP_MEMORY_STORAGE_BACKEND=sqlite_vec
# SQLite 性能优化参数,解决多进程访问时的数据库锁定问题
MCP_MEMORY_SQLITE_PRAGMAS=busy_timeout=15000,cache_size=20000,temp_store=MEMORY
# 禁用 CUDA,强制使用 CPU(用于兼容性问题)
CUDA_VISIBLE_DEVICES=-1
# 启用HTTP服务器(Hooks用户必选)
MCP_HTTP_ENABLED=true
# HTTP监听主机地址(可选)说明:127.0.0.1 仅本地访问,0.0.0.0 允许局域网访问
MCP_HTTP_HOST=127.0.0.1
# HTTP监听端口(必选)
MCP_HTTP_PORT=8000
# 禁用OAuth 2.1认证(可选)
MCP_OAUTH_ENABLED=false
#图存储模式dual_write:同时写入两者(默认,迁移模式)为未来迁移做准备
MCP_GRAPH_STORAGE_MODE=dual_write
# 日志级别(可选)已配置
# 选项:DEBUG | INFO | WARNING | ERROR
LOG_LEVEL=INFO
首次启动准备
软件安装完毕,配置也设定好之后,按照常理,接下来我们就可以启动它了。
但由于软件第一次启动时需要从Hugging Face下载本地运行用的语义模型,然而国内网络众所周知的原因,这个模型下载会失败,如下图所示:
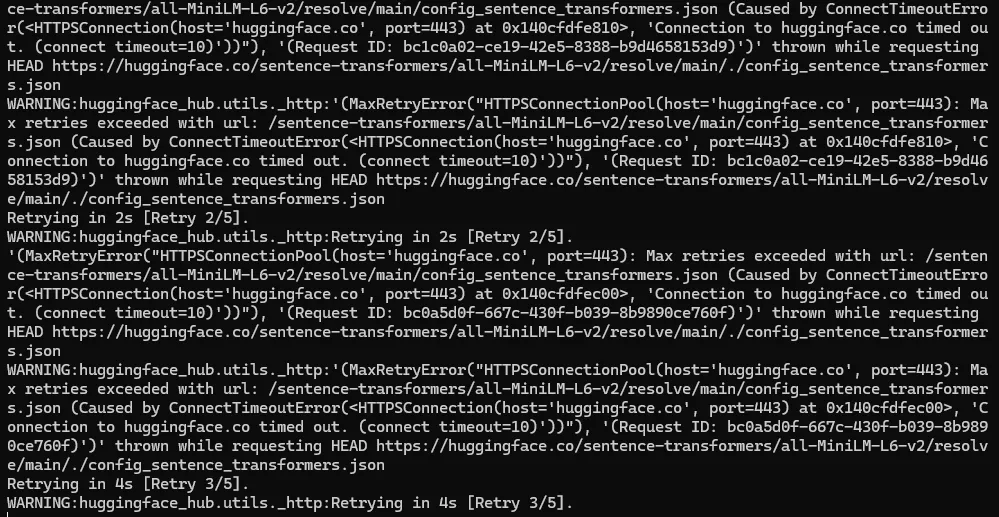
所以我们先不启动软件,使用国内镜像,先手动下载好该模型
具体方法如下:
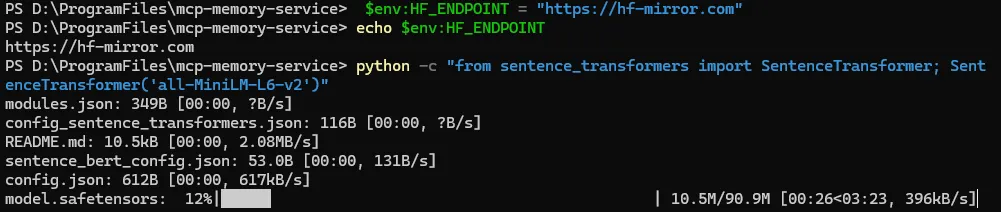
Windows用户(CMD或PowerShell):
# CMD终端用这个命令设置临时变量
set HF_ENDPOINT=https://hf-mirror.com
验证
echo %HF_ENDPOINT%
# powershell终端用这个命令设置临时变量
$env:HF_ENDPOINT = "https://hf-mirror.com"
# 验证
echo $env:HF_ENDPOINT
# 然后执行这个命令,手动下载模型
python -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('all-MiniLM-L6-v2')"
macOS/Linux用户:
export HF_ENDPOINT=https://hf-mirror.com
python -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('all-MiniLM-L6-v2')"
下载完语义模型后,我们终于可以试运行了。
试运行
首次运行,我们使用这个指令,它会读取我们刚刚在mcp-memory-service根目录中,.env文件中的配置,然后启动HTTP服务:
uv run python .\scripts\server\run_http_server.py

可以看到HTTP服务器被启动了,端口号是8000。
我们可以用浏览器访问http://127.0.0.1:8000/查看服务页面,如果能够顺利打开,就说明软件运行环境没有问题
我们也可以用这个命令测试当前服务的状态,如果显示healthy,就说明运行一切正常
curl http://localhost:8000/api/health

run_http_server.py能够正常启动,说明后台服务的运行环境都准备好了,接下来我们按 ctrl + c终止服务,用这个脚本把HTTP服务安装到操作系统的后台启动服务中去:
.\scripts\service\windows\install_scheduled_task.ps1
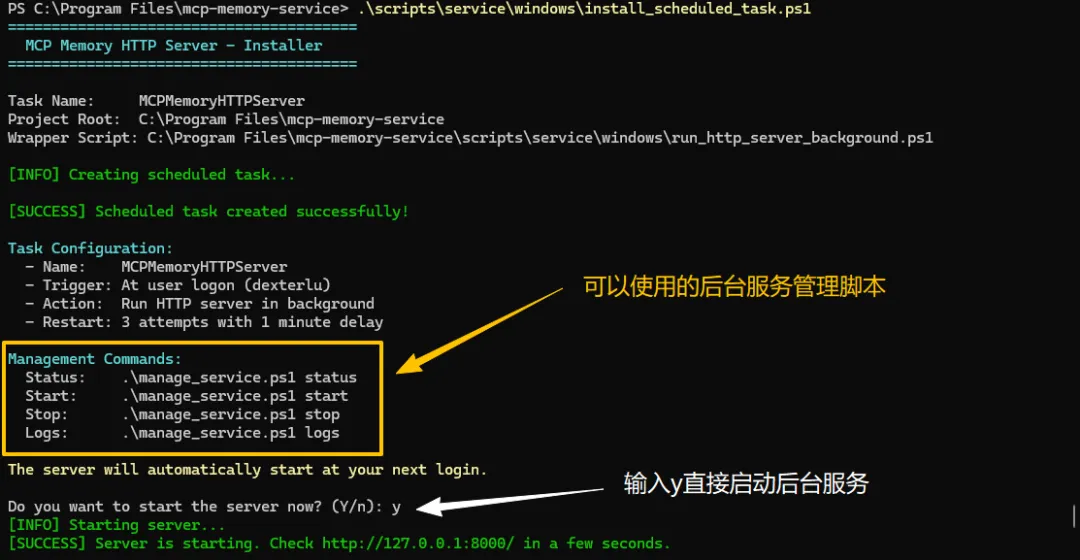
管理工具的位置和用法:
.\scripts\service\windows\manage_service.ps1 stop

.\scripts\service\windows\manage_service.ps1 start

不过由于管理脚本使用了过时的 .NET API,而我的系统中的相关软件包是最新的,这些管理工具暂时不能用了。 如果和我有同样问题的小伙伴,可以用我修改好的管理脚本,否则只能等待官方更新了。
如果和我有同样问题的小伙伴,可以用我修改好的管理脚本,否则只能等待官方更新了。
文件就在刚才分享的网盘链接里面
安装claude code hooks
接下来用这个脚本安装claude code相关的工具,它会安装claude code hooks和MCP(虽然安装的位置其实不太对,后面我会讲到怎么手动配置)
python .\claude-hooks\install_hooks.py --all
安装完毕后,打开这个位置的配置文件config.json
#把<用户名>替换成自己实际的用户名称
C:\Users\<用户名>\.claude\hooks
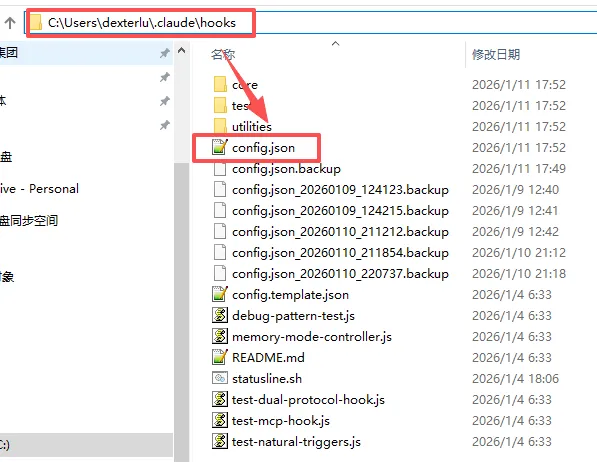
这是install_hooks.py自动生成的配置文件,所以这两个地方和我们之前在.env中的配置有出入,需要做一些调整
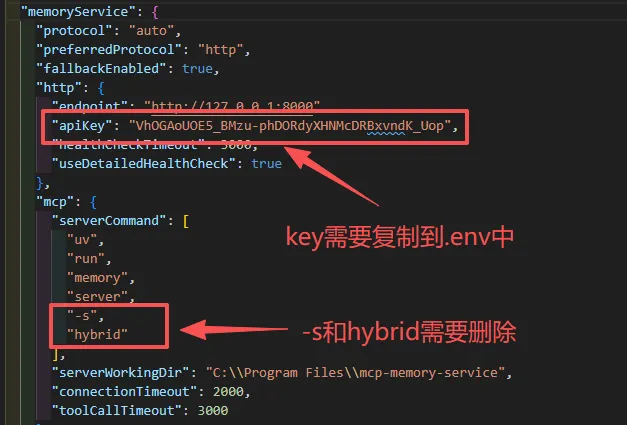
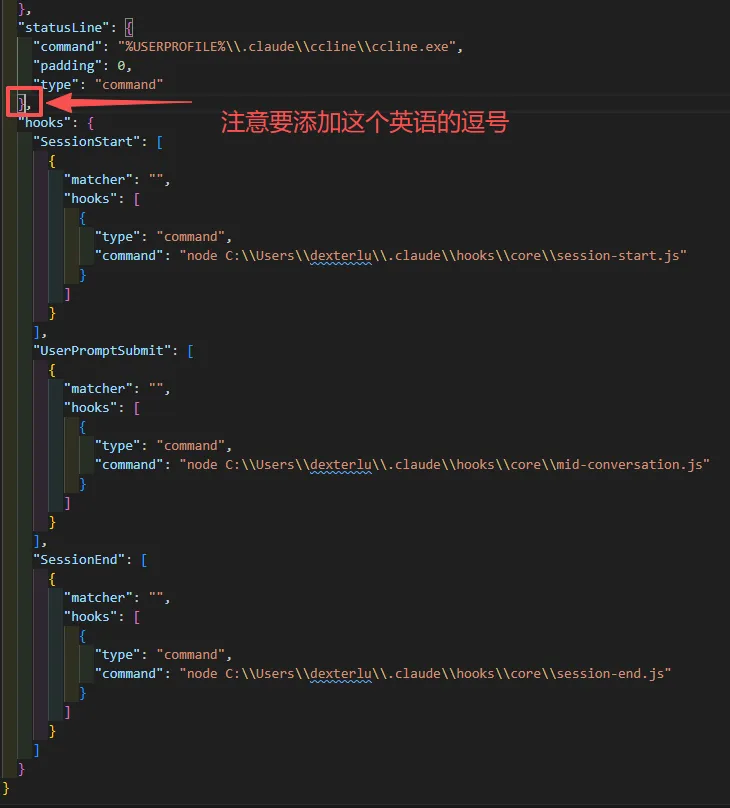
注意:要连带把”server”后面的逗号” , “也删除掉,否则不符合json的格式要求。
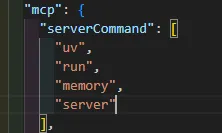
在.env文件中(就是我们一开始放在mcp-memory-service根目录下的配置文件),把刚刚复制的api key配置到MCP_API_KEY这个项目中。
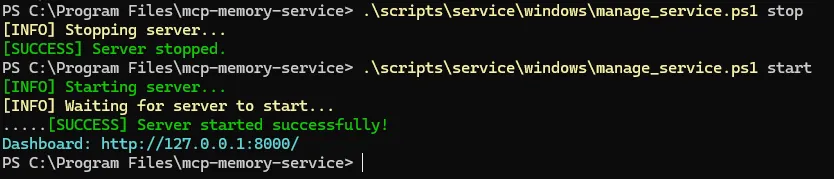
然后重启后台服务,或者重启电脑
#停止后台服务
.\scripts\service\windows\manage_service.ps1 stop
#启动后台服务
.\scripts\service\windows\manage_service.ps1 start
下一步打开这个文件,配置hooks:
#把<用户名>替换成自己实际的用户名称
C:\Users\<用户名>\.claude\settings.json
windows用户添加这部分内容,特别注意,要把<用户名>替换成自己实际的用户名称:
#把<用户名>替换成自己实际的用户名称
"hooks": {
"SessionStart": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "node C:\\Users\\<用户名>\\.claude\\hooks\\core\\session-start.js"
}
]
}
],
"UserPromptSubmit": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "node C:\\Users\\<用户名>\\.claude\\hooks\\core\\mid-conversation.js"
}
]
}
],
"SessionEnd": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "node C:\\Users\\<用户名>\\.claude\\hooks\\core\\session-end.js"
}
]
}
]
}
Linux和mac用户添加这个内容
"hooks": [
{
"pattern": "session-start",
"command": "node ~/.claude/hooks/core/session-start.js"
},
{
"pattern": "user-prompt-submit",
"command": "node ~/.claude/hooks/core/mid-conversation.js"
},
{
"pattern": "session-end",
"command": "node ~/.claude/hooks/core/session-end.js"
}
]
安装claude code斜杠命令
接下来我们安装claude code的斜杠命令,这个特别简单。
找到claude_commands目录,把全部的md文件(除了README),复制到这个位置就安装完成了:
#把<用户名>替换成自己实际的用户名称
C:\Users\<用户名>\.claude\commands
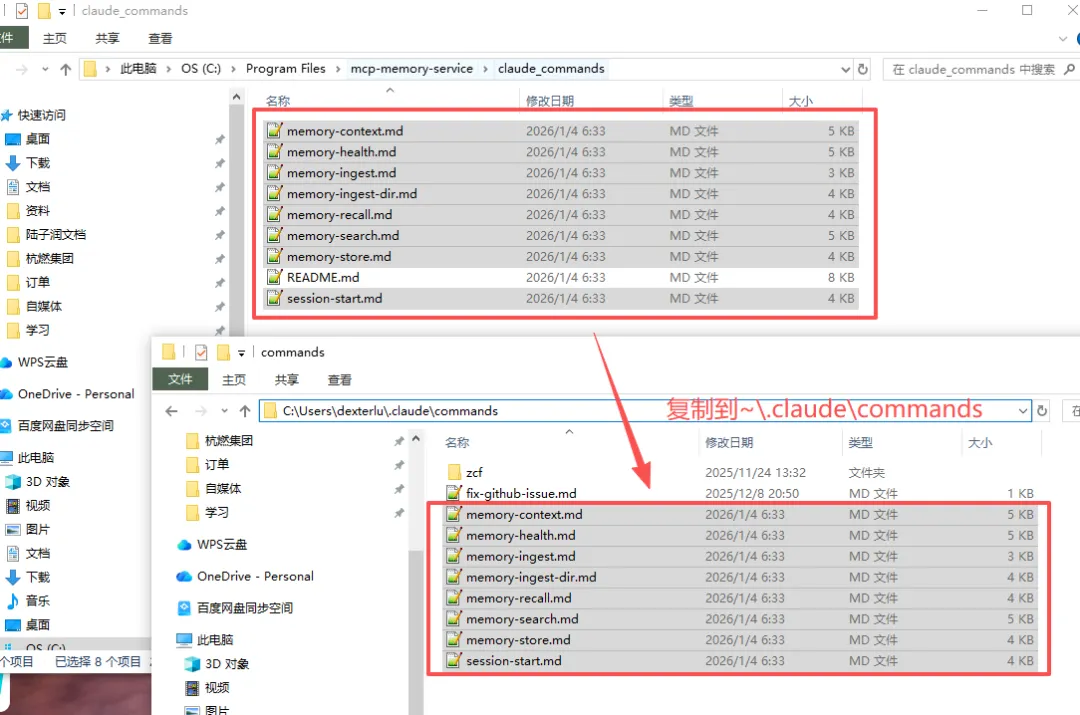
最后我们如果有正在使用的claude code,必须退出,然后关闭当前的终端后,再次打开claude code。
使用方法
windows下的claude code暂时受制于兼容问题,每次启动后必须手动调用斜杠命令 /session-start,初始化对话记忆。
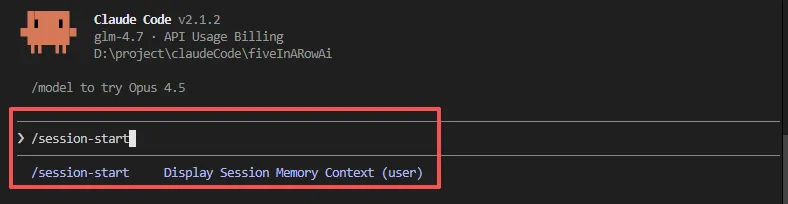
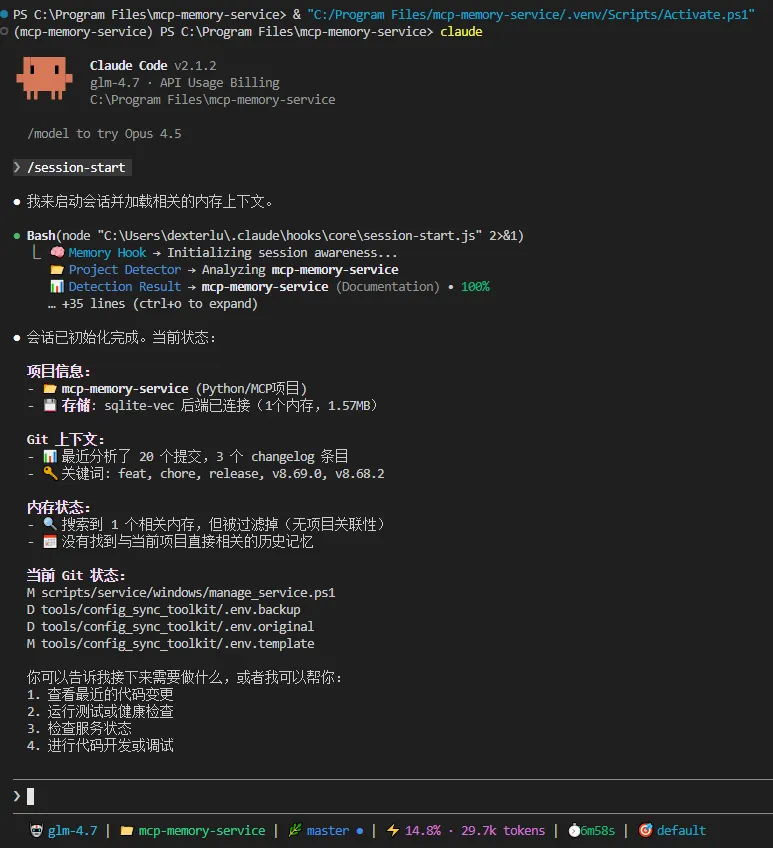
我们来测试一下,让AI帮我们确认hooks是否启动:
我现在已经重启了claude code和后台服务,并且在.env中拷贝了api key,帮我检查hooks是否正确连接到了后台服务中

通过看板页面,我们成功发现刚刚那条对话被自动捕获并记录了下来
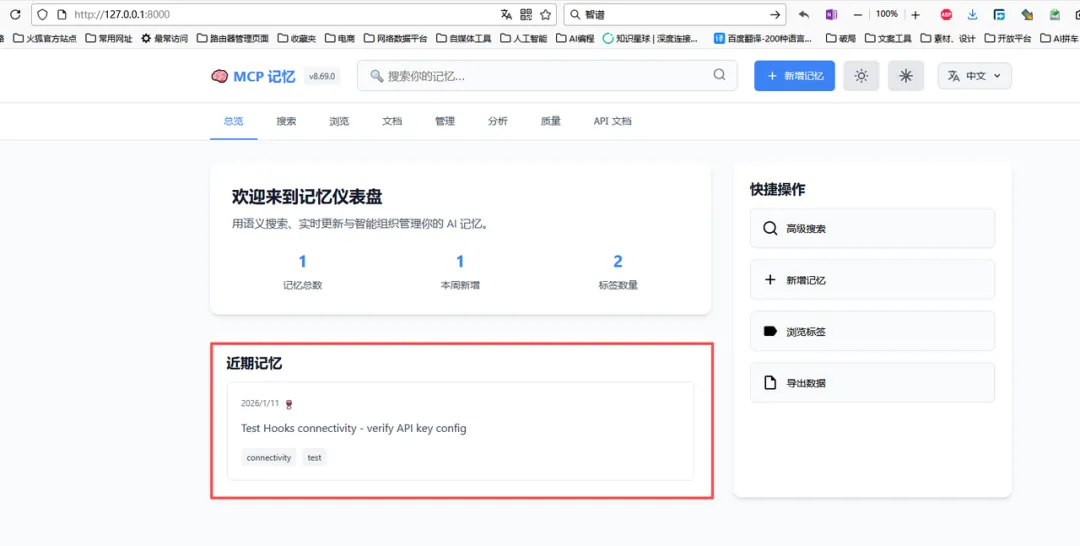
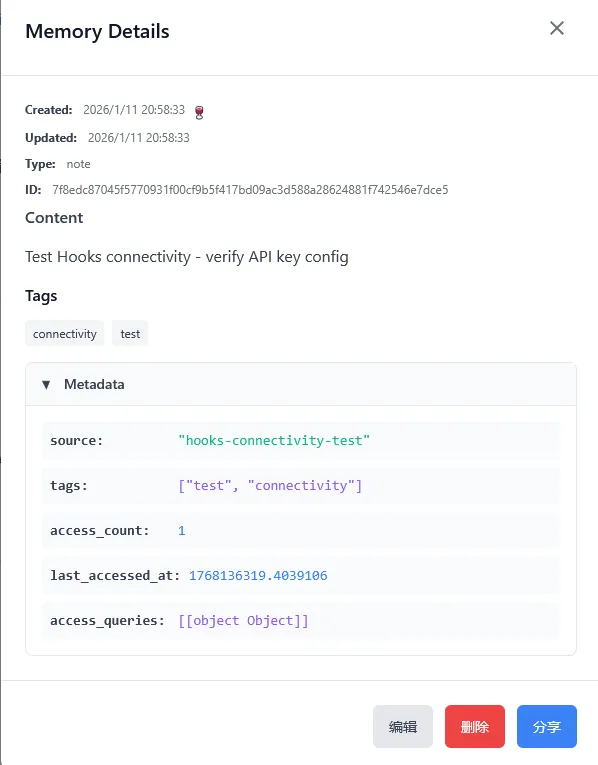
到这里,mcp-memory-service就安装好了,接下来就可以享受AI有长期记忆的爽快感觉了。
额外提醒
对了,还有几个问题要提醒大家:
-
后台的数据库sqlite-vec可能还没有Python 3.13以上版本的预编译组件,大家不要盲目求新。我实际测试发现3.12可以用。 -
macOS系统Python默认缺少SQLite扩展支持,可以用Homebrew Python
brew install python && rehash
或者用pyenv编译时启用扩展:
PYTHON_CONFIGURE_OPTS='--enable-loadable-sqlite-extensions' pyenv install 3.12.0
-
如果想用显卡加速本地模型的推理速度,先要确认显卡是否支持,这里我给大家提供一份表格
GPU 兼容性矩阵
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
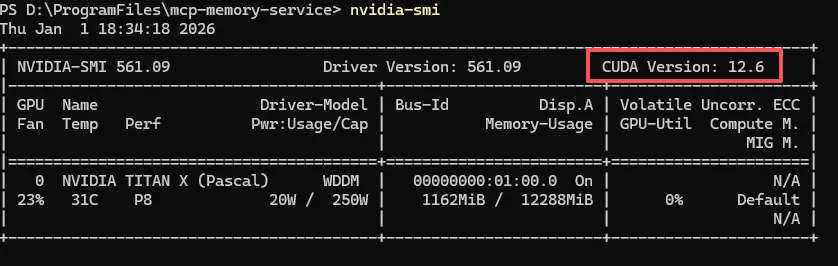
如果你的显卡支持加速,想要用GPU运行本地的语义模型,先确认CUDA是否安装
nvidia-smi
然后卸载当前只支持CPU加速的PyTorch
# 1. 卸载当前 CPU 版本
pip uninstall torch torchvision torchaudio -y

然后安装支持CPU加速的PyTorch(以支持CUDA12.6的版本为例)
# 2. 安装 GPU 版本(CUDA 12.6)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
如果自己的CUDA版本和例子中的不一样,可以先查看一下这个页面,把后边的cuxxx换成和自己的CUDA Version对应的版本
https://download.pytorch.org/whl/
这是网页的部分截图,大家可以参考

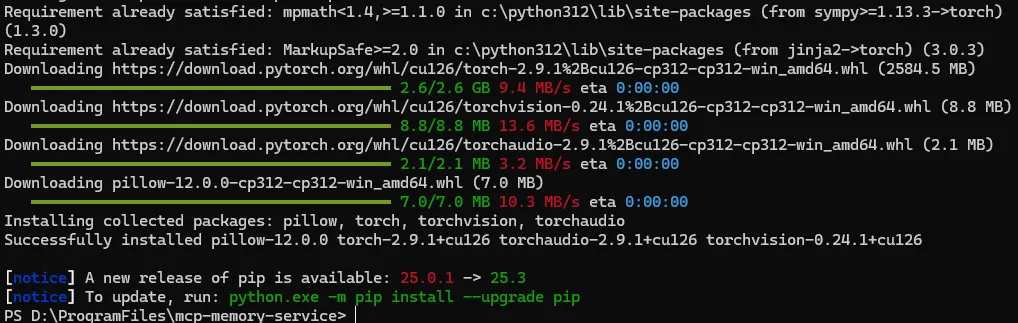
由于安装包很大,解压时间很长,整个安装过程可能会需要十几分钟,不要着急。
看到Successfully installed信息就说明安装成功了。
还有,不要忘记重新启动后台服务
#停止服务
.\scripts\service\windows\manage_service.ps1 stop
#启动服务
.\scripts\service\windows\manage_service.ps1 start
最后说两句
说实话,现阶段的mcp-memory-service并没有完全成熟,安装过程其实有很多问题。
典型的问题就是安装脚本对claude code的适配不是太好,写入配置的位置其实不对,所以前面有很多手动写配置的步骤。
还有,在windows系统下,配置中的很多文件路径有问题,实际在windows下的路径要用反斜杠 \ ,甚至有些地方需要用双反斜杠 \ 保证兼容问题。但是安装脚本写入的是正斜杠 / (linux、mac风格)。
最大也是最坑的问题是,官方文档和wiki内容信息分散,甚至有些地方有矛盾,让我蒙圈了好几天,连AI都被绕进去了。
这些问题虽然最终在人类(我)+ AI的通力配合下解决了,但属实曲折了一点。
毕竟是免费工具,而且版本迭代超级快,咱们也没有资格说什么怨言就是了。
说了一大堆,我其实想问的是:官方在哪里?
AI编程的痛点大家都知道,而现阶段没有哪怕一个官方站出来提供相关工具,也没有看到官方赞助哪个项目组的工作,导致现阶段的记忆插件要么就不能用,要么就和mcp-memory-service一样安装过程繁琐。
这属实不应该了,毕竟这世上大多数人都不是专家,如果能有官方支持,我相信相关工具一定会更好用。让普通人能享受AI带来的便利,这难道不是发展AI的初衷吗?
既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,我们,下次再见。
