 夜雨聆风
夜雨聆风





测试开发之python学习-第28讲:文件操作一

吴老的《selenium webdriver 实战宝典》出版了!
一.学习内容
* 文件操作
二.文件操作
1. open(file_name[,access_mode][,buffering])函数
open(file_name[,access_mode][,buffering])
file_name变量是一个包含你要访问的文件路径及文件名称的字符串值
access_mode:决定了打开文件的模式,只读(r)、写(w)、追加(a)等,默认为只读(r),该参数非强制。
buffering:为0就不会有缓存,如果为1访问文件会缓存行,如果值为大于1的整数,表明了这就是缓存区的缓冲大小,如果为负值,则缓存区的缓冲大小则为系统默认,该参数非强制。
open(file_name[,access_mode][,buffering])
该函数表示返回的是一个文件对象,当以只读模式(r)贷款一个不存在的文件时,就会报IOError异常(文件不存在),但如果是以写或追加模式打开一个不存在的文件时,默认会创建该文件,但如果是所在路径中有目录不存在,也会报IOError异常。
绝对路径:和你当前位置无关,完整路径 如:c:\test\test1\a.txt
相对路径:基于你当前的位置的路径如:我现在的位置为c:\test\test1,则相对路径为a.txt
一般网页源码中路径都是用的相对路径,这样可提高代码的移植性。
2. with open(file_name[,access_mode])函数执行完会自动关闭文件
文件为:utf-8
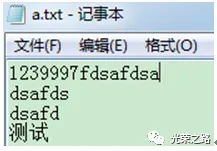
代码为:
#encoding=utf-8
with open(“C:\\Users\\yumeiling\\Desktop\\a.txt”,’r’) as f:
for line in f:
printline.decode(“utf-8”).encode(“gbk”,”ignore”),
运行结果:
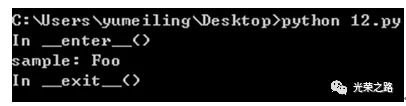
原理为:
#encoding=utf-8
class Sample:
def __enter__(self):
print “In __enter__()”
return “Foo”
def __exit__(self, type,value, trace):
print “In __exit__()”
def get_sample():
return Sample()
with get_sample() as sample:
print”sample:”,sample
运行结果:
3. r+,w+以后不指定游标位置,就read(),会打印和写入乱码的原因剖析
fp1 =open(“C:\\Users\\yumeiling\\Desktop\\a.txt”, “w+”)
fp1.write(‘test’)
fp1.read()
fp1.close()
运行结果:
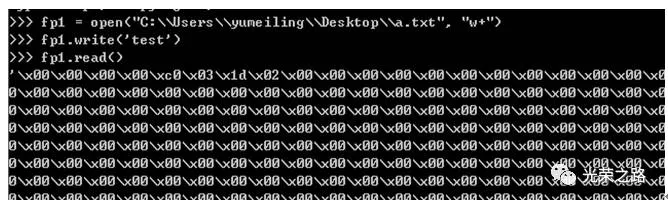
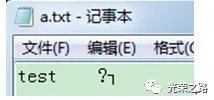
发现控制台打印了很多乱码或者说看不懂的字符,对fp1.close()后,打开桌面的a.txt文件:写入了一些乱码字符
解析:
fp1.write(‘test’)内容,游标移动到了文件末尾,此时没有将游标移动到开始位置fp1.seek(0,0),就执行了fp1.read()操作。
我们执行read()的时候,Python仍然去试图在磁盘的文件上,将指针从文件头向后跳3,再去读取到EOF为止。
也就是说,你实际上是跳过了该文件真正的EOF,为硬盘底层的数据做了一个dump,一直dump到了一个从前存盘文件的[EOF]为止。所以最后得到了一些根本不期待的随机乱字符,而不是编码问题造成的乱码。
4. type(fp)返回类型
代码为:
fp =open(“C:\\Users\\yumeiling\\Desktop\\a.txt”, “w”)
fp.write(“iamyml”)
print type(fp)
fp.close()
运行结果:

5. fp.readline()打印一行
文件内容为:

代码为:
fp =open(“C:\\Users\\yumeiling\\Desktop\\a.txt”, “r”)
print fp.readline()
fp.close()
运行结果为:

如果我想继续打印,可以继续用printfp.readline(),但是如果我想打印第3行呢
代码为:
fp =open(“C:\\Users\\yumeiling\\Desktop\\a.txt”, “r”)
print fp.readlines()[2] #这里的坐标从0开始,2为第3行的意思
fp.close()
运行结果为:

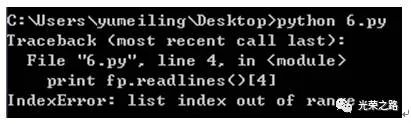
print fp.readlines()打印的结果是一个列表:

我们用坐标就可以取列表中的某个坐标的值。如果坐标取值范围超过列表本身的长度,则会报错越界,如下面我文件只有3行我却取坐标为4即第行的数据,就会报索引越界。
6. 小练习一-写一个函数,输出文件指定行
代码为:
# -*- coding:utf-8 -*-
def read_file_specific_row(fileName,rowNo):
try:
fp = open(fileName, “r”)
row=1
for line in fp: #读文件每行的的简单写法,fp是个迭代器
if row==rowNo:
fp.close()
return line
else:
row+=1
except Exception,e:
return ” file does not exist or row number exceeds the file rownumber!”
print read_file_specific_row(“C:\\Users\\yumeiling\\Desktop\\a.txt”,2)
源文件为:

运行结果为:读取第2行:

方法二:
# -*- coding:utf-8 -*-
def read_file_line(fileName,line):
try:
fp = open(fileName, “r”)
for i in range(line):
temp=fp.readline()
fp.close()
return temp
except Exception,e:
return “file does not exist or row number exceeds the file rownumber!”
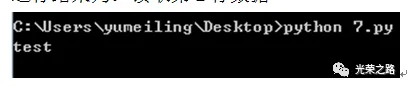
printread_file_line(“C:\\Users\\yumeiling\\Desktop\\a.txt”,2)
源文件为:
运行结果为:读取第2行数据
小记:
如何判断一个对象是不是可迭代的?
fp = open(“C:\\Users\\yumeiling\\Desktop\\a.txt”,”r”)
iter(fp) #判断对象是不是可迭代

参加光荣之路的测试开发班来实现你的测试开发梦想!
报名测试开发培训请联系:
微信:mengqiao626
qq:875821166

官网:www.gloryroad.cn
微信公众号:gloryroadtrain
性能测试QQ群:415987441
测试招聘QQ群: 203715128
Java2群:569534627
Python群:457561756
咨询V信:mengqiao626
咨询QQ:53617154
光荣之路公开课大讲堂:413908278
安装喜马拉雅app,搜索“光荣之路”可以收听吴老和他的朋友们分享的35小时测试知识语音
