 夜雨聆风
夜雨聆风





【2026计算机毕设项目】–附源码+视频+资料+测试文件–基于Hadoop的个人网盘系统领取
关注本公众号点击领取源码即可领取或者添加vx:java_bishe。
点击上面文字也可以👆
今天,小编分享一个项目,利用大数据领域的基石——Hadoop,来设计和实现一个属于你自己的分布式个人网盘系统。(包括项目介绍,选题意义,演示视频,功能结构图)
一、项目介绍
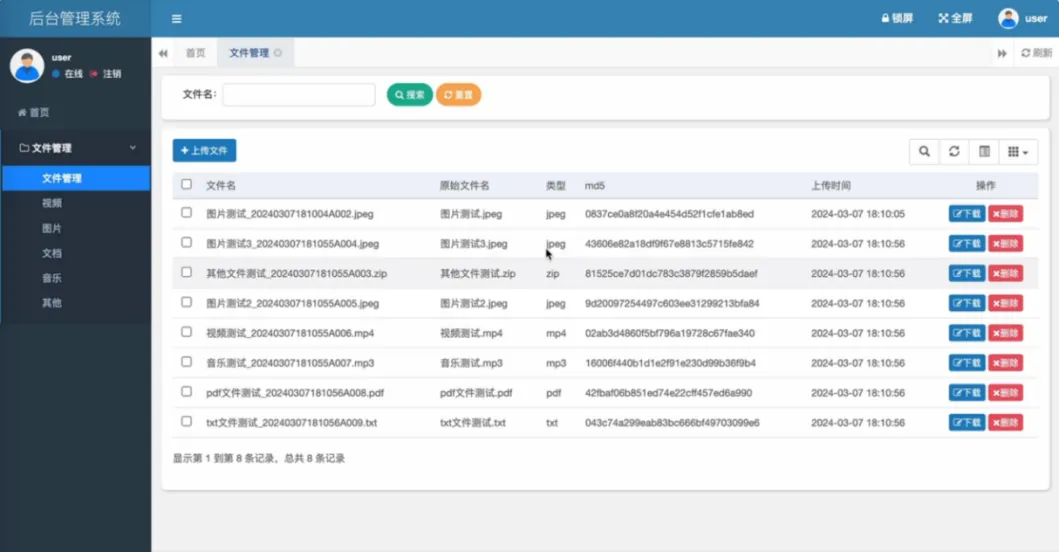
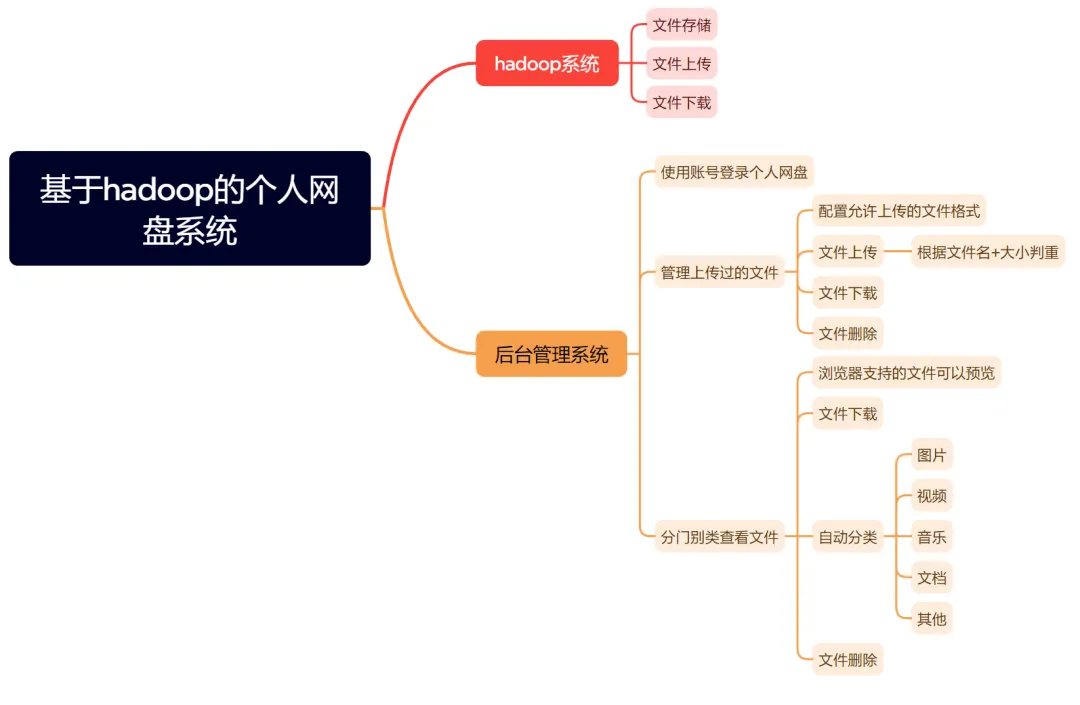
本项目是一个基于Hadoop分布式文件系统构建的个人网盘Web应用系统。系统采用微服务架构思想,后端使用Spring Boot框架构建核心业务服务,以HDFS作为海量文件的底层存储引擎,前端为响应式Web界面,支持多终端访问。
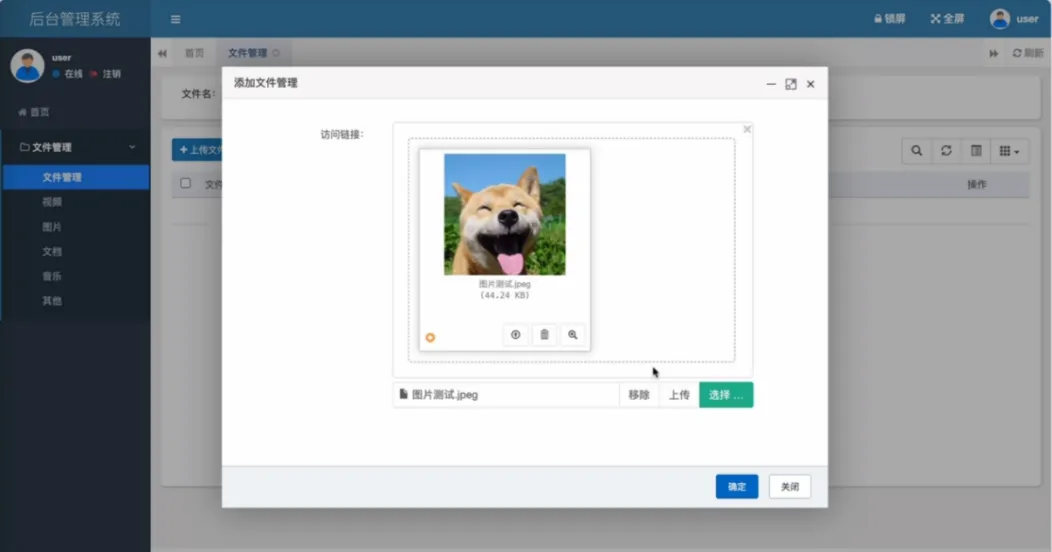
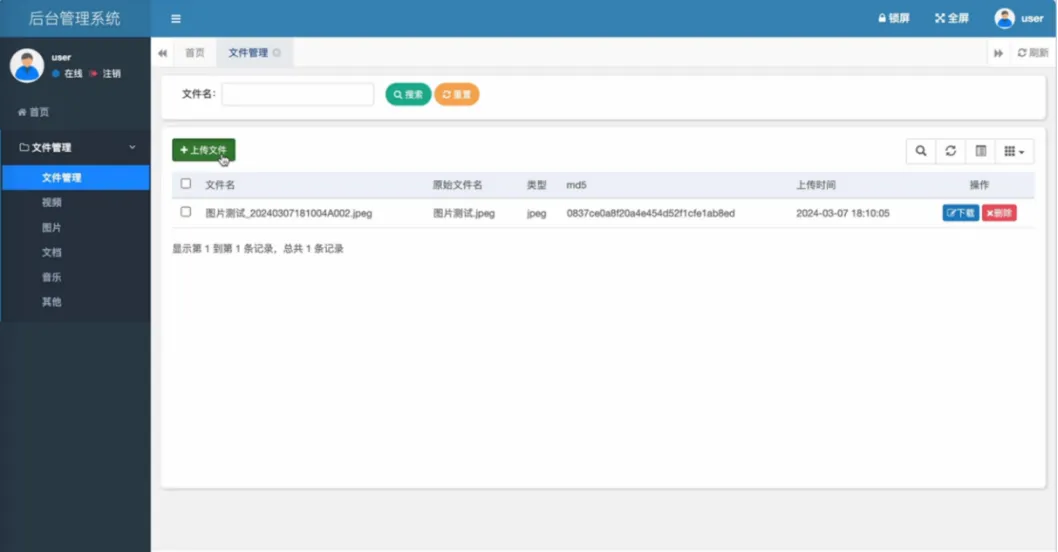
系统核心功能分为存储引擎与后台管理两大部分。存储引擎层基于Hadoop实现,负责文件的物理分布式存储、多副本容灾保障以及高吞吐量的上传与下载。后台管理层提供完整的网盘应用功能,包括用户账号登录与数据隔离、可配置的上传文件格式策略、基于文件名与大小校验的文件上传、全面的文件管理(列表、下载、删除)、以及图片、视频等浏览器支持文件的在线预览。系统还集成了智能文件分类功能,可自动将文件按音乐、文档、图片等类型分门别类展示,极大提升了文件管理效率。通过将HDFS的企业级存储能力与易用的Web管理界面相结合,系统在保证数据高可靠性与海量扩展性的同时,提供了媲美商业网盘的流畅用户体验。
二、选题背景与意义
演示视频
三、关键技术栈:Hadoop HDFS
Hadoop HDFS(分布式文件系统)是本系统的核心存储引擎,是Apache Hadoop项目的基石。相比传统集中式存储(如单机硬盘或NAS),HDFS具有海量扩展、高容错性、高吞吐量和成本低廉等核心优势,特别适合海量非结构化数据的存储场景。
HDFS的架构设计主要围绕三个关键角色展开:客户端(Client)、名称节点(NameNode)和数据节点(DataNode),共同构建了一个可靠的文件存储层。在数据存储层面,系统将用户上传的任何文件物理切分为固定大小的数据块(Block,默认为128MB),并以多副本(默认3份)形式分布式存储在集群的多个DataNode上,确保了硬件故障时的数据安全与读写并行性。名称节点(NameNode) 作为系统的“大脑”,以元数据形式在内存中高效维护整个文件系统的目录树及文件与数据块的映射关系,确保了文件访问的敏捷性。数据节点(DataNode) 负责底层磁盘上数据块的存储、检索与完整性校验,并通过心跳机制定期向NameNode汇报,构成系统的“肌肉”。客户端在上传或下载文件时,首先从NameNode获取元数据指引,随后直接与相关的DataNode建立管道进行高速数据传输,这种设计避免了中心化流量瓶颈,实现了卓越的聚合I/O带宽。
四、技术架构图
代码获取方法
关注本公众号点击领取源码即可领取或者添加vx:java_bishe
