【2026计算机毕设项目】–附源码+视频+资料+测试文件–个性化小说推荐系统领取
关注本公众号点击领取源码即可领取或者添加vx:java_bishe。
点击上面文字也可以👆
今天,小编分享一个项目,利用推荐系统中的经典核心——协同过滤推荐算法,来设计和实现一个属于你自己的个性化小说推荐系统。(包括项目介绍,选题意义,演示视频,功能结构图)
一、项目介绍
本项目是一个面向小说阅读爱好者的微信小程序平台。系统采用前后端分离架构,后端基于Spring Boot框架提供核心业务接口与数据服务,前端为微信小程序形态,支持便捷的移动端访问。
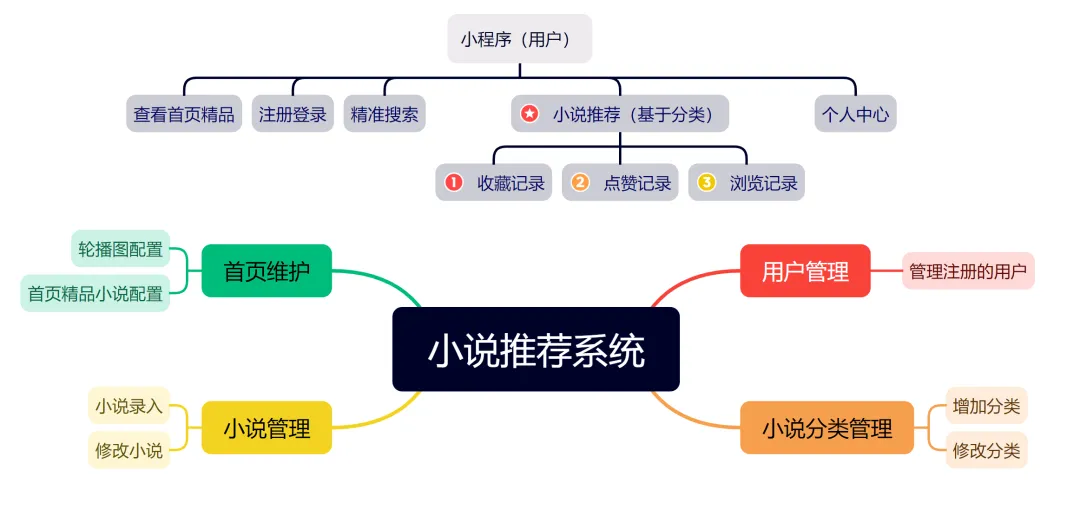
系统核心功能分为用户阅读与管理后台两大部分。用户端提供完整的阅读体验功能,包括首页精品推荐、分类精准搜索、基于用户偏好与分类的小说智能推荐,以及个人中心的收藏、点赞与浏览记录管理。管理后台提供全面的内容与用户运维能力,包括首页轮播图与精品区块的灵活配置、注册用户的信息查询与管理、小说资源的录入与分类管理(支持分类的增加与修改),以及对已上架小说信息的编辑与维护。通过将系统化的内容管理后台与轻便易用的小程序前端相结合,平台在保障内容更新效率与运营管控能力的同时,为用户提供了流畅、个性化的移动阅读体验。
二、选题背景与意义
随着数字阅读的普及,小说阅读平台已成为人们日常娱乐的重要部分,但传统平台在内容发现效率、个性化服务及运营管理方面存在局限。本系统的设计与实现可以有效提升用户的阅读体验与平台管理效能,使其能够更便捷、精准地发现和阅读感兴趣的作品。从而提升了个人阅读体验与平台运营效率。
数据挖掘与智能推荐技术通常被应用于电商和社交领域,本系统将这些技术引入小说阅读推荐场景,为用户提供更个性化和精准的内容推荐服务,推动了智能推荐技术在数字文化消费领域的应用和普及。从而促进了智能推荐在内容领域的落地。小说阅读平台中的用户偏好数据与阅读记录是重要的数字资产,也是用户隐私的关键部分。本系统通过完善的权限控制、行为记录与数据保护机制,增强了用户数据的安全性与可控性,为读者提供了更可信赖的阅读环境。从而加强了用户数据与隐私保护。
本系统的设计与实现融合了推荐算法、移动应用开发与内容管理技术,涉及计算机科学、数据科学、文化传播等多个学科领域,对相关领域的学术研究与应用实践具有一定参考和推动价值,为内容型产品的系统构建提供了可复用的思路与方案。从而拓展了跨学科研究与产业应用的结合路径。
演示视频
三、关键技术栈:Hadoop HDFS
协同过滤推荐算法是本系统的核心推荐引擎,是当前个性化推荐领域的经典范式。相比基于规则或简单热门的推荐方式,协同过滤具有自动发现兴趣关联、不依赖内容深度分析以及可解释性较强等核心优势,特别适用于用户行为丰富、物品数量庞大的小说推荐场景。
在系统运行层面,算法首先基于用户的行为记录(如收藏、点赞、阅读时长)构建一个庞大的用户-小说交互矩阵,并以此为基础进行离线或实时的相似度计算与预测。系统最终将推荐结果高效集成至“小说推荐”与“首页精品”等模块,实现了从“人找书”到“书找人”的体验转变,显著提升了内容分发的精准度与用户阅读满意度。
四、功能架构图
代码获取方法
关注本公众号点击领取源码即可领取或者添加vx:java_bishe
 夜雨聆风
夜雨聆风