 夜雨聆风
夜雨聆风





DeepEP源码分析1——internode notify_dispatch
整理早期的代码笔记;
notify_dispatch 主要做了两件事:
1.在 sm_id == 0 上:全局等待并清理旧RDMA状态,在 RDMA/NVL 对称缓冲中构造“混合计数块”,通过RDMA交换这些计数;在本节点做多级规约(per‑expert、per‑rank、全局)并计算前缀和;把结果写入 host‑mapped 计数器和接收前缀数组;通过 NVL 缓冲把 per‑rank/per‑expert 信息广播到节点内所有 GPU;在末尾做跨节点 + 节点内barrier,形成“元数据阶段完成”的全局同步点。
2.在sm_id != 0 上:并行按 channel 和 RDMA rank,用 is_token_in_rank 重新统计每个 (global rank, channel) 的 token 数;写入gbl_channel_prefix_matrix 和 rdma_channel_prefix_matrix,并对每一行做前缀和。
最终输出就是 一整套“谁要收多少、从哪里开始收、每个通道上分布如何”的元数据,为后续 dispatch 数据搬运内核提供所有路由与布局信息。
首先介绍一下函数参数,这个函数参数比较多,不过可以分为4类:
1. 输入统计信息(per‑rank / per‑expert / per‑token)
-
const int* num_tokens_per_rank:每个 global rank(节点×GPU)要接收多少 token 的初始统计数组,长度为 num_ranks。
-
int num_ranks:全局 rank 总数,一般等于kNumRDMARanks * NUM_MAX_NVL_PEERS。
-
const int* num_tokens_per_rdma_rank:每个 RDMA 节点要接收的 token 数(按节点聚合),长度为 kNumRDMARanks。
-
const int* num_tokens_per_expert:每个 expert 要接收的 token 数,长度为 num_experts。
-
int num_experts:全局 expert 总数。
-
const bool* is_token_in_rank:一个大布尔表,表示 “token i 是否属于 global rank j”,用于按 token 维度重新统计各 rank / channel 的负载。逻辑上是[num_tokens][num_ranks] 的布尔矩阵线性展开。
-
int num_tokens:token 总数(本次dispatch 的输入 token 数)。
-
int num_worst_tokens:落入“最坏路径”(worst‑path) 的 token 数,用来判断是否可以走 fast‑path(直接写 counter)还是要走保守路径。
-
int num_channels:将 token 空间切成多少个“通信通道”(用于并行/流水发送)的通道数。
-
int expert_alignment:每个 expert 的 token 数在最终分配时需要对齐的粒度(向上取整到该倍数)。
2. 输出到 host‑mapped 的统计 / 前缀和
-
int* moe_recv_counter_mapped:映射到 host/其他 stream 的单一计数器:所有 rank 总共要接收的 token 数(全局总数)。
-
int* moe_recv_rdma_counter_mapped:映射到 host 的 RDMA 级计数器:所有 RDMA 节点接收的 token 总和,或节点级汇总后写入的位置。
-
int* moe_recv_expert_counter_mapped:映射到 host 的 per-expert 计数器数组,长度为num_experts 或每节点experts 数:每个expert 要处理的(对齐后的)token 总数。
-
int* rdma_channel_prefix_matrix:二维矩阵[kNumRDMARanks][num_channels] 线性展开:对每个 RDMA 节点、每个 channel,记录该 channel 上该节点要接收的 token 数,后续会就地转为前缀和。
-
int* recv_rdma_rank_prefix_sum:RDMA 级前缀和数组,长度 kNumRDMARanks:按 RDMA 节点累积的 token 数前缀和,用于确定每个节点在大缓冲区中的区间。
-
int* gbl_channel_prefix_matrix:三维[global_rank][num_channels] 压平成二维:每个 global rank 在每个 channel 的 token 数,后续同样会转成前缀和。
-
int* recv_gbl_rank_prefix_sum:按 global rank 的前缀和数组,长度 num_ranks:用于把所有 token 放入一个连续 recv buffer 时,为每个 rank 分配连续区间。
3. 缓冲区布局与清理参数
-
const int rdma_clean_offset:RDMA 对称缓冲区中,从哪一个 int 位置开始是“需要清零的数据区域”的起始 offset。
-
const int rdma_num_int_clean:在 RDMA 缓冲区中,从 rdma_clean_offset 开始,要清零多少个 int。
-
const int nvl_clean_offset:NVLink 对称缓冲区中,数据区域清零的起始 offset(单位也是 int)。
-
const int nvl_num_int_clean:NVL 缓冲区中,从 nvl_clean_offset 开始,要清零多少个 int。
4. 设备端缓冲区与同步资源
-
void* rdma_buffer_ptr:RDMA 对称缓冲区的基址(NVSHMEM 对称分配的那块,用于节点间交换元数据)。
-
void** buffer_ptrs:节点内各 GPU 的NVLink 对称缓冲区指针数组:buffer_ptrs[nvl_rank] 是本 GPU 的 NVL 缓冲区;也会用buffer_ptrs[peer_nvl_rank] 访问其它 GPU 的 NVL 缓冲区。
-
int** barrier_signal_ptrs:用于 barrier_block 实现节点内/块内 barrier 的信号数组,每个NVL rank 一组信号。
-
int rank:当前进程/线程块所在的 global rank ID(编码了 rdma_rank 和nvl_rank)。
-
const nvshmem_team_t rdma_team:NVSHMEM 的 team 句柄:表示一组要一起参与 nvshmem_sync 的 PE 集合(例如“所有节点上同一GPU index 的进程”)。
SM 0专门负责通信同步
最开始是几个关键变量初始化。

首先,SM 0专门负责通信同步:第一个warp用于节点内同步(NVLink),第二个warp用于节点间同步(RDMA)。我们先看SM 0的逻辑。
qps_per_rdma_rank表示每个rdma_rank(也就是一个node)的qp数量。通过ibgda_get_state()获取IBGDA的全局状态结构,IBGDA是NVSHMEM用于实现GPU直接RDMA通信的底层机制。num_rc_per_pe是每个pe上的rc qp数量,pe是NVSHMEM的概念,类似一个rank。num_devices_initialized表示已初始化的设备(GPU)数量,通常是节点内参与通信的GPU数量。
假设配置:- num_rc_per_pe = 1(每对GPU一个RC连接)- num_devices_initialized = 8(每节点8个GPU则 qps_per_rdma_rank = 1 × 8 = 8,含义:当前节点到另一个节点共有8个QP
然后开始循环等待所有qp上的RDMA传输完成,因为要防止在上次RDMA传输完成前重写缓冲区。nvshmemi_ibgda_quiet等待指定QP上所有未完成的RDMA操作完成,这是NVSHMEM的底层IBGDA接口。
接下来,thread_id == 32只让第32号线程(第二个warp的第一个线程)执行,前面讲过第二个warp用于节点间同步(RDMA)。nvshmem_sync_with_same_gpu_idx用于NVSHMEM的跨节点同步操作,rdma_team是NVSHMEM的概念,包含所有节点的对应GPU,这个调用确保所有节点的对应GPU都到达这个同步点,才能继续执行。注意,仅同步具有相同GPU索引的节点(比如每个node的GPU0之间,每个node的GPU1之间),而不是所有GPU。其内部是通过RDMA的atomic操作实现的同步,每个GPU向其他节点的对应GPU用RDMA原子加或写操作,同时等待收到所有其他节点的信号。
然后barrier_block用于节点内同步,确保节点内所有GPU都完成前面的操作,再继续执行。其内部是通过通过barrier_signal_ptrs基于IPC共享内存 + 原子操作实现的,原理如下图所示。

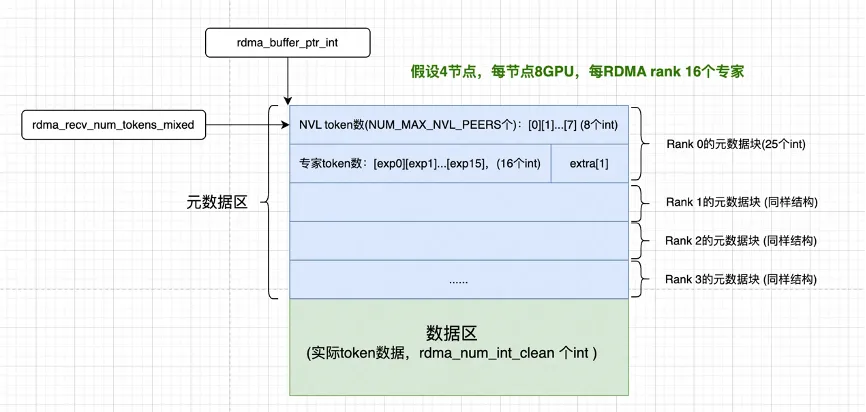
接下来rdma_buffer_ptr_int和rdma_recv_num_tokens_mixed分别初始化为RDMA缓冲区的元数据区。为了方便理解,这里先看一下DeepEP RDMA缓冲区的布局。如下图所示,RDMA缓冲区由元数据和数据区两部分构成,假设有4个节点,则有4个rdma rank,每个rdma rank都有各自的元数据区和数据区。每个rdma rank的元数据区用于存放“从各个来源会收到多少token”,具体包括两部分:每个NVL rank发来的token数量,告诉接收方节点内每个GPU会收到多少来自本节点(发送方)的token(NUM_MAX_NVL_PEERS个);每个专家收到的token数量,告诉接收方本节点的每个专家会处理多少token(num_rdma_experts个);即有rank和expert两个维度的token数量通知。
rdma_recv_num_tokens_mixed就是描述RDMA缓冲区中元数据区的结构。他是一个SymBuffer对象,关于SymBuffer对象我们单独展开讲一下。在这之前先看接下来的循环,这个就是当前block中的每个thread并行的把数据区的元素清零,总共rdma_num_int_clean个,它是函数入参传进来的。
SymBuffer
SymBuffer(Symmetric Buffer,对称缓冲区)是DeepEP中用于管理跨节点共享内存的抽象数据结构。先解释一下对称内存的概念,在NVSHMEM中,对称内存是指所有参与通信的节点都分配了相同布局、相同大小的内存区域,且每个节点可以通过相同的偏移量访问其他节点的对应内存。SymBuffer的定义如下:
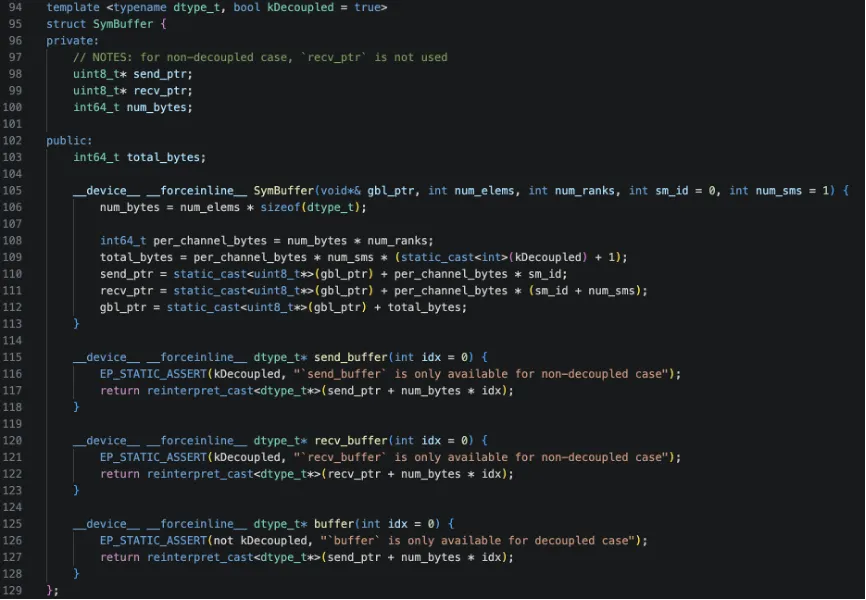
然后结合rdma_recv_num_tokens_mixed的创建过程解释一下。模版参数kDecoupled = true(默认)表示发送和接收缓冲区分离,否则表示共用缓冲区。
auto rdma_recv_num_tokens_mixed = SymBuffer<int>(rdma_buffer_ptr, NUM_MAX_NVL_PEERS + num_rdma_experts + 1, kNumRDMARanks);其参数对应关系如下(假设4节点,每节点8GPU,每RDMA rank 16个专家);

按照这个传入参数相关成员的计算逻辑如下:
num_bytes = 25 * 4 = 100 字节(每个rank的数据)
per_channel_bytes = 100 * 4 = 400 字节(所有rank的发送或接收区)
total_bytes = 400 * 1 * 2 = 800 字节(发送+接收)
对应内存布局如下图:

具体使用方式如下:
发送数据(写入send_buffer)
// 准备发给RDMA Rank 1的数据rdma_recv_num_tokens_mixed.send_buffer(1)[0] = gpu0_tokens; // NVL分布rdma_recv_num_tokens_mixed.send_buffer(1)[8] = expert0_tokens; // 专家分布
RDMA发送(从send_buffer到远程recv_buffer)
nvshmemi_ibgda_put_nbi_warp(rdma_recv_num_tokens_mixed.recv_buffer(rdma_rank), // 远程目标:对方的recv_buffer[我的rank]rdma_recv_num_tokens_mixed.send_buffer(i), // 本地源:我的send_buffer[对方rank]...);
nvshmemi_ibgda_put_nbi_warp是NVSHMEM的warp级非阻塞RDMA PUT操作,从其名字也大概能看出作用,nbi表示Non-Blocking Immediate,非阻塞立即返回;warp表示整个warp协作执行。
接收数据(读取recv_buffer)
// 读取来自RDMA Rank 2的数据int tokens_from_rank2 = rdma_recv_num_tokens_mixed.recv_buffer(2)[0];
继续向下看代码,接下来这段代码是dispatch操作中元数据准备阶段,将本地计算的token分布信息组织成适合RDMA传输的格式,后续会通过RDMA发送给各个目标节点,让接收方知道会收到多少数据,具体就是将本地统计的token数量信息复制到rdma_recv_num_tokens_mixed的发送缓冲区。

首先,复制每个rank的token数量,i / NUM_MAX_NVL_PEERS计算目标RDMA rank(节点),i % NUM_MAX_NVL_PEERS计算目标NVL rank(节点内GPU);接着,复制每个专家的token数量,i / num_rdma_experts计算专家所在的RDMA rank(节点),i % num_rdma_experts计算专家在节点内的索引NUM_MAX_NVL_PEERS + …偏移到专家区域(跳过NVL区域);最后,复制每个RDMA rank的总token数量。
接下来,这段代码实际发送元数据到其他节点,告知各节点会收到多少token。首先是一个循环,i代表目标RDMA rank(目标节点的编号),i的范围0 到 kNumRDMARanks – 1,每个i值对应一个目标节点,循环遍历所有需要发送的目标节点。此外,这是warp-stride loop模式,目的是让多个warp并行处理不同的目标节点,假设4个节点,2个warp:
warp_id=0: i = 0, 2 (处理节点0和节点2)warp_id=1: i = 1, 3 (处理节点1和节点3)并行执行:├─ Warp 0: 发送到节点0 →发送到节点2└─ Warp 1: 发送到节点1 →发送到节点3
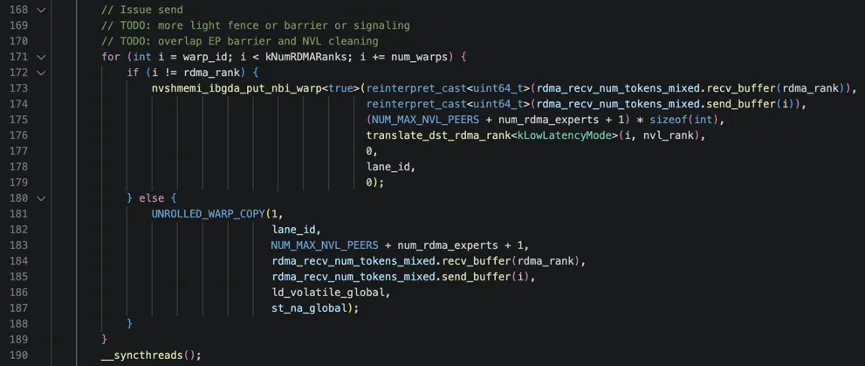
i != rdma_rank说明目的不是本机的rdma_rank,需要RDMA发送,nvshmemi_ibgda_put_nbi_warp是NVSHMEM的warp级非阻塞RDMA PUT操作,这个函数有7个参数:
● 第1个:远程目标地址:目标节点上“我的数据块“的地址
●第2个:本地源地址:本地准备好的发给目标节点的数据,send_buffer(i)就是要本地要发给i节点的数据;
● 第3个:数据大小:NVL分布 + 专家分布 + 总数
● 第4个:目标PE:目标节点的PE编号
● 第5个:QP索引:使用哪个Queue Pair
● 第6个:lane_id:warp内线程ID,用于协作
● 第7个:标志:额外控制标志
否则目的是本节点的rdma_rank,调用UNROLLED_WARP_COPY进行内存复制,其中ld_volatile_global参数表示加载方式(volatile全局读取),st_na_global表示存储方式(non-atomic全局写入)。最后,调用__syncthreads()确保所有warp完成发送操作后再继续。
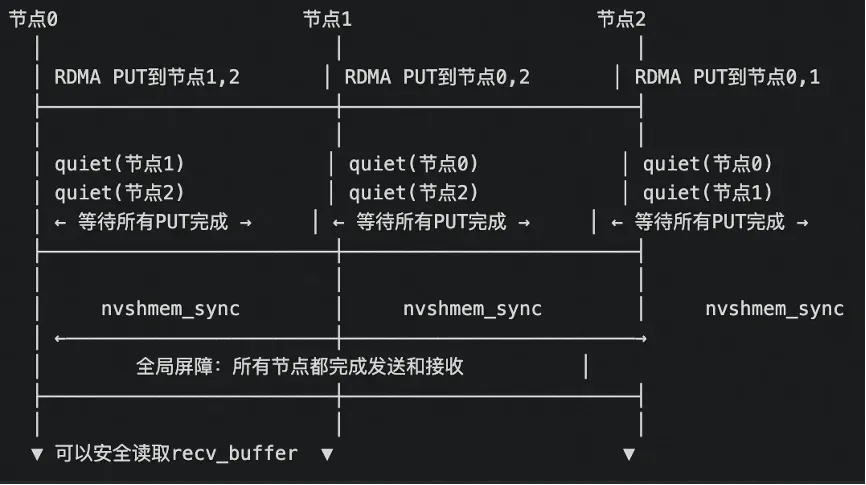
继续看下面代码,这段代码确保所有RDMA发送操作完成,然后进行跨节点同步,保证所有节点都已收到元数据。首先看循环条件,thread_id < kNumRDMARanks表示只有前N个线程执行(N=节点数),thread_id != rdma_rank表示不等待发给自己的(因为本地复制不走RDMA)。
nvshmemi_ibgda_quiet函数用于等待到指定目标节点的所有未完成RDMA操作完成,参数1表示目标节点PE,参数2表示QP索引(0)。假设有4个节点(对应4个rdma_rank),thread0等待发送给rdma_rank0的操作完成,thread1等待发送给rdma_rank1的操作完成,以此类推,thread4等待发送给rdma_rank4的操作完成。
另外不知道大家有没有注意到,前面发送元数据的时候是warp并行,为什么这里等待发送完成是thread并行?主要是因为发送的数据量较大,warp协作可以提高内存访问效率,而等待只是检查/等待一个QP的完成状态,比较轻量,并且Thread级并行可以同时等待更多节点。(注意这里的thread和前面的warp也没有什么对应关系)
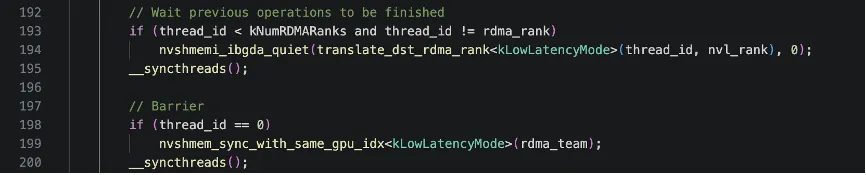
此外,这里为什么先用quiet然后在用sync,首先明确一下quiet和sync的区别,quiet涉及的是本地操作,等待本节点发出的操作完成,不会涉及跨节点通讯,sync是全局同步,等待所有节点都到达同步点,会涉及跨节点通讯。quiet确保本节点发出的RDMA PUT已经到达目标内存,不关心其他节点的状态,sync只是一个“会合点“,不保证之前的RDMA操作已完成,只保证所有节点都到达这个点。
接着,thread_id == 0的线程执行同步操作,nvshmem_sync_with_same_gpu_idx,同步所有节点中相同GPU索引的进程都到达这个同步点。对应时间线如下:
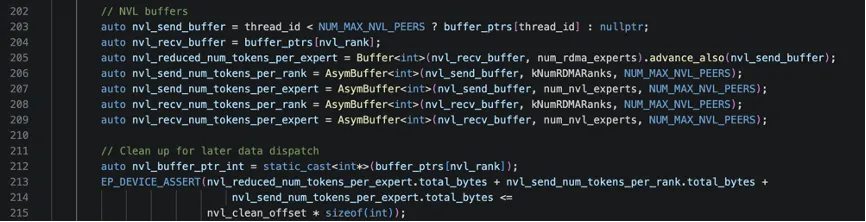
下面这段代码是设置NVLink缓冲区,用于节点内GPU间的通信。这里面涉及了几个变量,为了更好的理解这几个变量的含义,下面我举一个具体的例子。假设:2个节点(节点0、节点1),每节点4个GPU(GPU0-3),总共8个rank(rank0-7),当前是节点0的GPU2(nvl_rank=2)。nvl_send_buffer指向目标GPU的缓冲区(用于写入),nvl_recv_buffer指向自己的缓冲区(用于接收),具体如下:
Thread 0: nvl_send_buffer → GPU0的缓冲区Thread 1: nvl_send_buffer → GPU1的缓冲区Thread 2: nvl_send_buffer → GPU2的缓冲区Thread 3: nvl_send_buffer → GPU3的缓冲区Thread 4+: nvl_send_buffer → nullptr所有Thread: nvl_recv_buffer → GPU2的缓冲区(当前GPU)
第一步:每个GPU统计自己要发送的token数,对应nvl_send_num_tokens_per_rank,如以当前GPU2为例,其需要发送给其他rank的数据如下(注意这里有跨节点的rank):
发给rank0(节点0-GPU0): 12个发给rank1(节点0-GPU1): 8个发给rank2(节点0-GPU2): 0个(自己)发给rank3(节点0-GPU3): 15个发给rank4(节点1-GPU0): 20个← 需要RDMA发给rank5(节点1-GPU1): 18个← 需要RDMA发给rank6(节点1-GPU2): 10个← 需要RDMA发给rank7(节点1-GPU3): 22个← 需要RDMA
计算当前GPU要发给每个本地专家的token数,注意这里只有本节点的专家,对应变量nvl_send_num_tokens_per_expert,以当前GPU2为例:
发给专家0(GPU0): 18个发给专家1(GPU0): 14个发给专家2(GPU1): 20个发给专家3(GPU1): 11个发给专家4(GPU2): 0个(自己的专家)发给专家5(GPU2): 0个(自己的专家)发给专家6(GPU3): 25个发给专家7(GPU3): 17个
第二步:通过NVLink交换,GPU2收集所有GPU的发送计划,对应变量nvl_recv_num_tokens_per_rank,例如如下,第一列表示GPU0的发送计划,可以看到第三列就是本GPU2,其实就是GPU2的nvl_send_num_tokens_per_rank。
来自GPU0 来自GPU1 来自GPU2 来自GPU3发rank0: 15 10 12 8发rank1: 20 0 8 14发rank2: 0 18 0 11发rank3: 12 15 15 0发rank4: 25 22 20 18 ← 需要汇总发给节点1发rank5: 18 16 18 20发rank6: 10 12 10 15发rank7: 22 19 22 25
nvl_recv_num_tokens_per_expert的含义类似,表示从其他GPU收到的每专家发送计划。
第三步:规约汇总,GPU0汇总整个节点要发给其他节点的token总数:
发给节点1的总token数 =GPU0发给节点1: 25+18+10+22 = 75+ GPU1发给节点1: 22+16+12+19 = 69+ GPU2发给节点1: 20+18+10+22 = 70+ GPU3发给节点1: 18+20+15+25 = 78 = 292
GPU2的缓冲区(nvl_recv_buffer = buffer_ptrs[2])如下图所示:
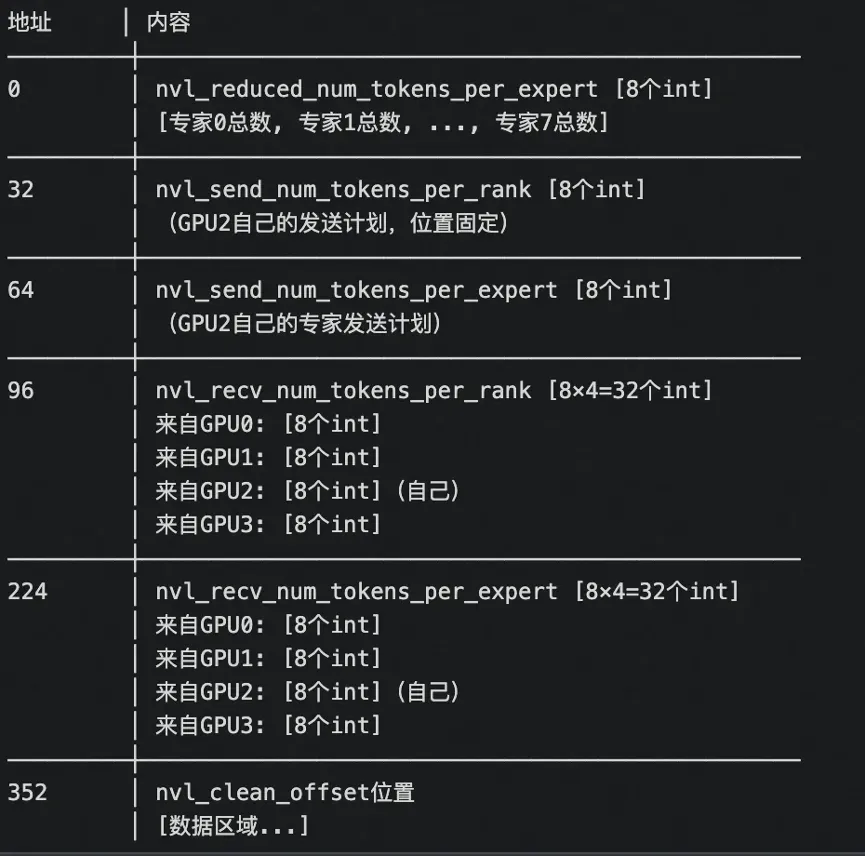
有了上面的铺垫,下面的代码就相对比较好理解了,首先就是并行清零NVLink缓冲区的数据区域(注意这里清理的数据区,不是元数据区),接下来一段逻辑规约专家token数量,每个线程负责一个专家,汇总来自所有RDMA rank的token数,数据来源为rdma_recv_num_tokens_mixed.recv_buffer(i),这是之前通过RDMA接收到的各节点元数据,recv_buffer(i)[NUM_MAX_NVL_PEERS + expert_id]存储节点i发给该专家的token数。
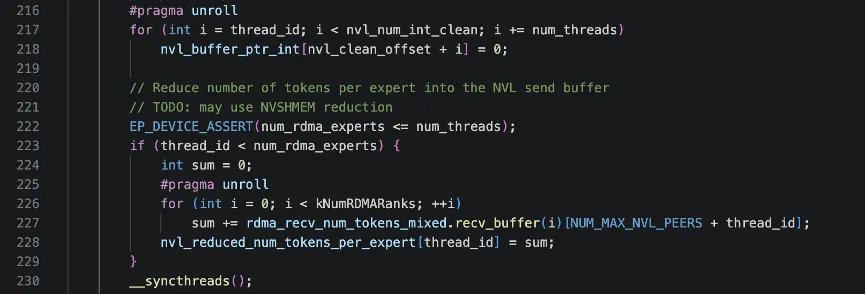
前面的流程通过 RDMA把“各节点间”的 token 统计信息已经汇总到rdma_recv_num_tokens_mixed中了,接下来这段代码在每个节点内,把这些统计信息重新分发/写入到每个 GPU 自己的 NVLink 缓冲区(nvl_send_*),按 rank 和 expert 组织好。
具体而言,每个 thread 代表一个NVL rank,第一个循环遍历每个RDMA rank,右边(回忆 rdma_recv_num_tokens_mixed 的布局,每个 RDMA rank一块)recv_buffer(i)[thread_id]表示“RDMA rank i 发给 NVL rank = thread_id 的 token 数”;左边nvl_send_num_tokens_per_rank是在 nvl_send_buffer 上构造的AsymBuffer,buffer(nvl_rank)[i] 可以理解为:在 “目标 NVL rank = p 的缓冲区里,为 NVL rank = nvl_rank(当前 GPU)存一行,索引 i 是 RDMA rank”。这是一个“转置 + 广播”的过程:把rdma_recv_num_tokens_mixed 这个“按(RDMA rank → NVL rank)”的 view,重排/写入到各个 GPU 自己的 NVL 缓冲区里,变成每个 GPU都能按“(NVL rank → RDMA rank)”方便地访问。
同理接下来一个循环对于每个 NVL rank = thread_id,以及该 NVL rank 上的每个本地专家 i,我把“这个专家的全节点规约 token 数”写入到它的 NVLink 缓冲区里,并且按(来源 GPU = nvl_rank)的维度分开存储,方便后续按 GPU 维度再做处理。
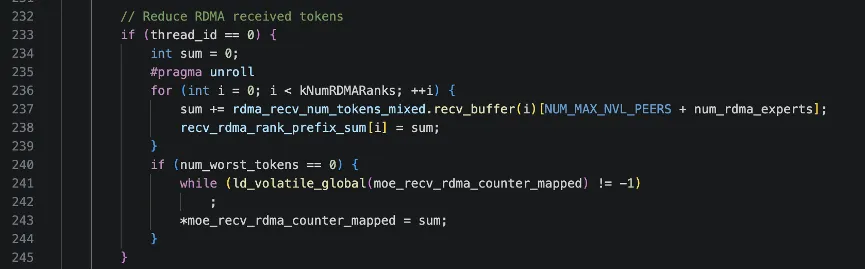
接下来这段代码有thread 0执行,把 nvl_recv_num_tokens_per_rank 里按 (NVL rank, RDMA rank) 存的 token 数,按照 global rank 顺序扫一遍,形成一个 recv_gbl_rank_prefix_sum 前缀和数组;例如:
recv_gbl_rank_prefix_sum[0] = rank0 的 token 数recv_gbl_rank_prefix_sum[1] = rank0 + rank1 的token 数recv_gbl_rank_prefix_sum[2] = rank0 + rank1 + rank2 的 token 数...recv_gbl_rank_prefix_sum[i] = rank0..rank_i 的token 总和
最终sum=recv_gbl_rank_prefix_sum[num_ranks-1] = 所有 rank 的 token 总和。为什么需要这样一个前缀数组呢,因为这样在后续的数据接收/布局阶段,每个 global rank 会有一段自己的 token 区间,如rank i 的token 对应的区间: [ recv_gbl_rank_prefix_sum[i-1],recv_gbl_rank_prefix_sum[i] ),这样就可以把所有要接收的 token 放到一个大连续 buffer 里,但仍然可以按 rank 做切片、定位每个 rank 的起始位置,实现单 pass 接收 + 简单 index 计算。
然后moe_recv_counter_mapped是一个映射到 host / 其他 stream 的全局变量指针。前面的 while(… != -1) 是在 spin:等别人把这个位置重置成 -1 之后,当前 kernel 才写入,避免覆盖旧值,然后把刚才求得的 sum(即所有 rank 的token 总数)写进去。它的用途是:通过这个 counter 知道 “这一次 dispatch / combine,最终总共要接收多少 token”,以便提前分配/检查buffer,或者做某种同步判断(比如所有 token 都已经到齐)。
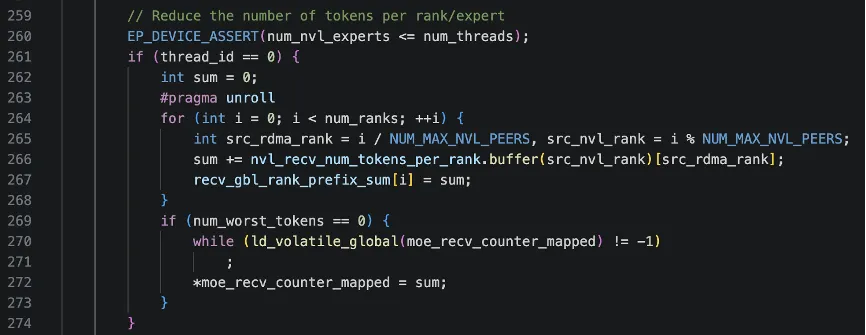
接下来,按“专家”规约 NVL 内所有 GPU 的 token数,thread_id 在这里扮演“本节点上第 thread_id 个专家”。NUM_MAX_NVL_PEERS为节点内GPU个数(NVL rank 数),nvl_recv_num_tokens_per_expert.buffer(i)[thread_id]含义是“来自 NVL rank = i 的数据中,第 thread_id 个专家要处理的 token 数”。sum = 整个节点内,所有 GPU上,第 thread_id 个专家的 token 总数(也就是“节点级 per-expert 规约”),一个线程负责一个 expert,把该 expert 在所有 GPU 上的 token 数加在一起。然后写入 host-mapped 的 per-expert 计数器。
最后,只让 block 中的一个线程(这里选了 thread_id == 32)去调用 NVSHMEM 的跨节点同步;避免同一个 GPU 上的许多线程同时调用 collective,同步语义更清晰,也减少冗余调用。
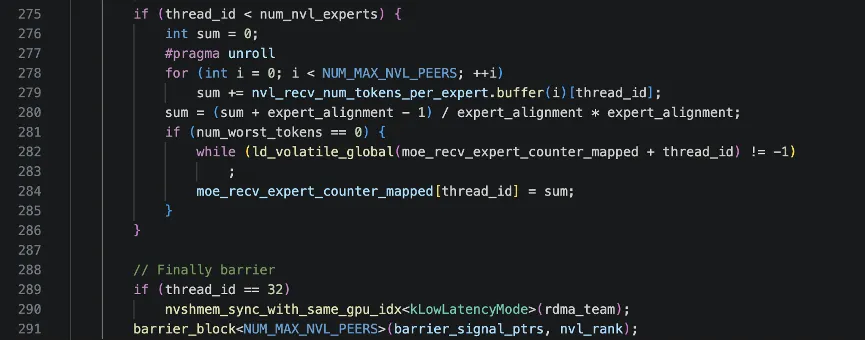
非SM 0逻辑
SM 0用于rdma通信和ipc通信来统计要接受和发送的信息,其他SM则统计channel(通道)粒度的内容。首先,用当前 SM 的编号 sm_id 推出一个目标RDMA rank,减 1 通常是因为 sm_id == 0 被保留给通讯同步使用,这里从 1 开始映射到 rdma rank 0。
接着,for循环每个 warp 负责若干个 channel,channel_id 从本 warp 的 warp_id 开始,以num_warps 为步长做“warp-stride”遍历所channel。get_channel_task_range(…)把num_tokens均分给 num_channels 个“通信通道”,返回当前channel_id 负责的 token 区间[token_start_idx, token_end_idx)。
然后,利用压缩的 bool 信息 is_token_in_rank,统计当前 channel 内,对这个 dst_rdma_rank 有效的 token 总数 total_count;以及当前 channel 内,对这个 dst_rdma_rank 下每个 NVL rank 的 token 数per_nvl_rank_count[j];
最后,warp 内规约后,由一个代表线程把结果写入gbl_channel_prefix_matrix[global_rank, channel_id],精确到每个 global rank;同时写入rdma_channel_prefix_matrix[dst_rdma_rank, channel_id]聚合到 RDMA rank 维度。
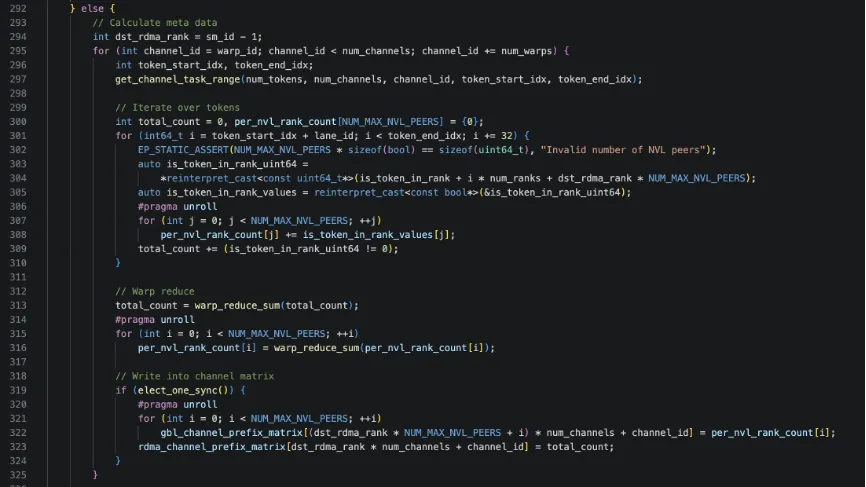
最后这段代码专门负责把通道级统计结果转成前缀和形式。
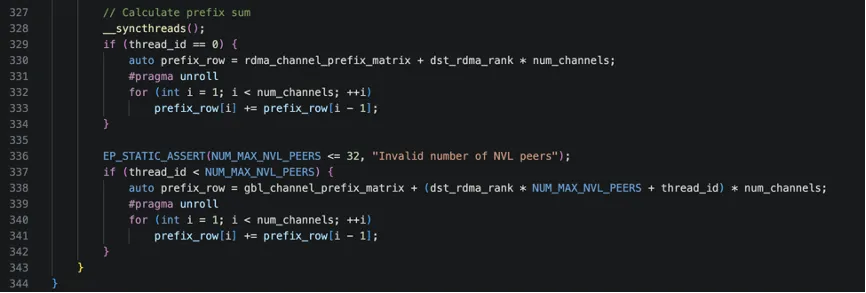
到此, notify_dispatch的工作完成, 在host cpu侧代码会基于 mapping内存moe_recv_counter得到节点接受的token数量,然后基于这个token数量分配recv_x的内存, 而后开始internode_dispatch工作。 从上面代码逻辑来看, notify就是在登记各种token的发送/接受信息, 是一个比较轻量级的任务。
kLowLatencyMode的影响
下面我们看下整个notify_dispatch中关于低延时模式(kLowLatencyMode)的影响有什么。在整个 notify_dispatch 函数里,kLowLatencyMode 主要通过两个内联 helper 被“间接”用到,有两大类作用:
1. 影响 RDMA 目标 PE 映射(地址路由),如
在等待/清空 QP 时:
nvshmemi_ibgda_quiet(translate_dst_rdma_rank<kLowLatencyMode>(dst_rdma_rank, nvl_rank), ...)在发 RDMA PUT 时:
nvshmemi_ibgda_put_nbi_warp(..., translate_dst_rdma_rank<kLowLatencyMode>(i, nvl_rank), ...)这些地方都调用了translate_dst_rdma_rank:

也就是说:
kLowLatencyMode = true,把目标 PE 映射为 (rdma_rank, nvl_rank) 展开的“每 GPU 一个 PE” 模式,RDMA 直接打到“目标节点的目标GPU”(精确到 NVL rank),避免“打到节点代表再经过一次 NVLink hop 转发”的额外延迟,更适合小批量、小消息场景,减少一次 NVLink 转发的固定开销,延迟更低;
kLowLatencyMode = false,直接用 dst_rdma_rank,即传统“每节点一个 PE”模式。RDMA 只打到“节点代表”这一点,节点内再通过 NVLink(或者共享内存)在 GPU 之间转发/规约。这样管理的QP 数、连接数更少,更利于大规模高吞吐传输,节点内可以做比较重的汇聚操作(比如更复杂的规约、重排)。
2. 影响 NVSHMEM 同步接口选择(全局 vs team)
函数里多处同步用的是:
nvshmem_sync_with_same_gpu_idx<kLowLatencyMode>(rdma_team);
当 kLowLatencyMode = true,用 nvshmem_sync(rdma_team),只在给定的 rdma_team 内同步(通常是“同 GPU index 的那一条纵向链条”)。比如“所有节点上的 NVL rank 0”构成一个 team,“所有节点上的 NVL rank 1”构成另一个 team,等等。这样参与同步的 PE 数更少,只同步真正参与这一步通信的那条通路,避免把与当前步骤无关的 PE 全部拉进来,减少 collectives 的 fan‑in/fan‑out 开销,对延迟敏感的阶段(notify + 元数据规约)里,减少一次全局 barrier 的成本。
当 kLowLatencyMode = false,用 nvshmem_sync_all(),对所有 NVSHMEM PE 做全局同步,对于高吞吐模式来说,PE 数 = 节点数,规模相对可控,全局barrier 成本可以接受。
备注:
源码对应commit 3fcf25ed1b50f8abab6bac71e792432f7158fc26
