 夜雨聆风
夜雨聆风





Day81 我用这个免费小插件,突破了 90% 网站的反爬机制
挑战日更100天,今天是日更第88天
Hi 大家好,我是贺伯,一个初学AI编程与工作流的工厂IE,每天分享使用Vibe coding跟n8n工作流的实战过程
———————————————————————–

💬QUOTE
工具不在多,能解决问题就行
凌晨1点,我盯着满屏的报错信息,差点想放弃
公众号文章复制出来全是乱码加水印,playwright 被指纹检测拦住,puppeteer 验证码糊脸,手动抓包翻了半天——接口参数加密得跟天书一样
直到我在 GitHub 翻到了这个只有 2MB 的小插件
为什么传统方法失效
先说说我踩过的坑,省得你再走一遍

1. Playwright / Puppeteer 的问题
这类工具确实强,能模拟浏览器操作
但问题是——网站也在进化
指纹检测:它们能识别出你用的是无头浏览器,直接封掉
验证码墙:稍微敏感点的页面,先让你滑块验证
登录态:需要登录的内容,你得先解决 Cookie 问题
我在工厂做 IE 的时候就知道,绕过检测永远是猫鼠游戏
你今天写的脚本,下周可能就失效了
2. 手动抓包的问题
打开 F12 看 Network,这招我用了好几年
但现在的问题是:
-
接口参数动态加密,你拿到了也解不出来 -
数据藏在 JS 渲染里,接口根本不返回完整内容 -
一个页面可能发 50+请求,找半天找不到主数据接口
(我怀疑做反爬的人,上辈子是做保险箱的)
解题思路:借用真实浏览器会话
想通这个逻辑之后,我突然觉得之前的方向全错了
📝GOLDEN
与其模拟浏览器,不如直接借用你已经登录好的真实浏览器
什么意思?
你平时用 Chrome 上网,已经登录了各种账号,Cookie 都在
如果有个工具能直接读取这个浏览器的状态,然后用程序去操作——
反爬机制根本分辨不出来,因为对网站来说,就是你本人在操作
这就是 dev-browser 的核心原理
这个插件到底是什么
dev-browser 是一个 Chrome 扩展,做的事情很简单:
-
它在你的真实浏览器里运行 -
通过 WebSocket 暴露一个接口给外部程序调用 -
外部程序(比如 Claude Code)可以发送指令,让浏览器去做操作
翻译成人话:
你在 Claude Code 里说”帮我抓这个页面”,它就用你的 Chrome 去开这个页面,然后把内容返回给你
因为是你自己的浏览器,带着你的登录态、Cookie、浏览记录——
网站根本查不出问题
安装只需要 3 分钟
别被”Chrome扩展”这个词吓到,操作很简单
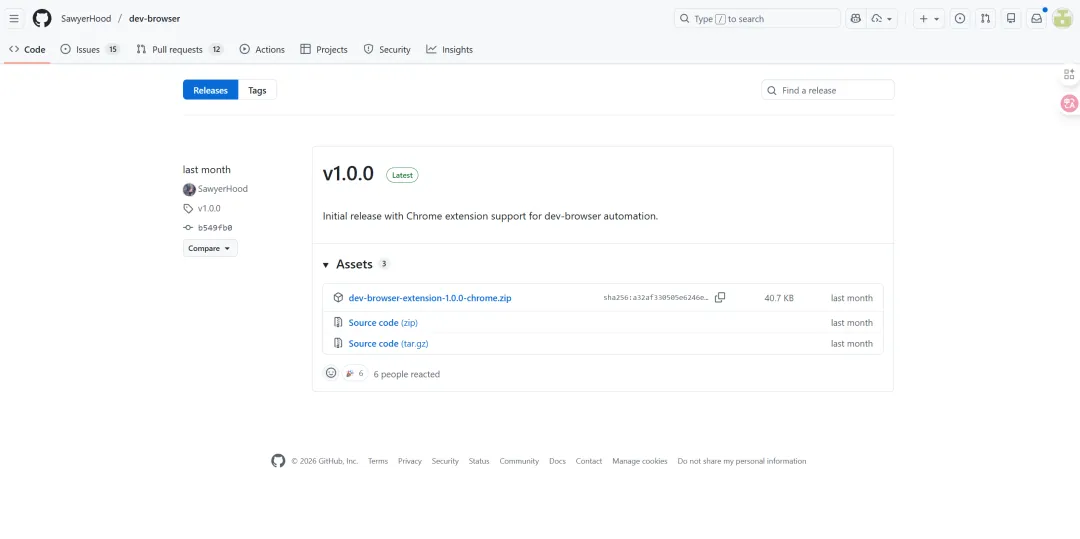
第一步:下载插件包
去 GitHub release 页面:github.com/SawyerHood/dev-browser/releases
下载最新的 .zip 文件(大概 2MB)
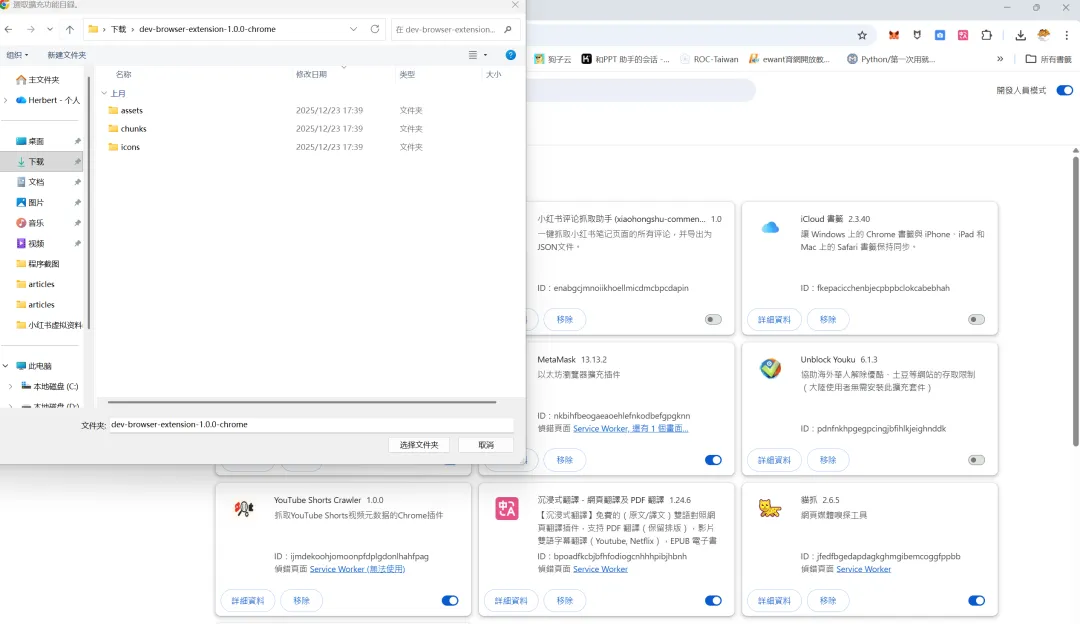
第二步:加载到 Chrome
打开 Chrome 浏览器,地址栏输入:chrome://extensions/
右上角把「开发者模式」打开
然后把下载的 zip 文件拖进去,或者点「加载已解压的扩展程序」
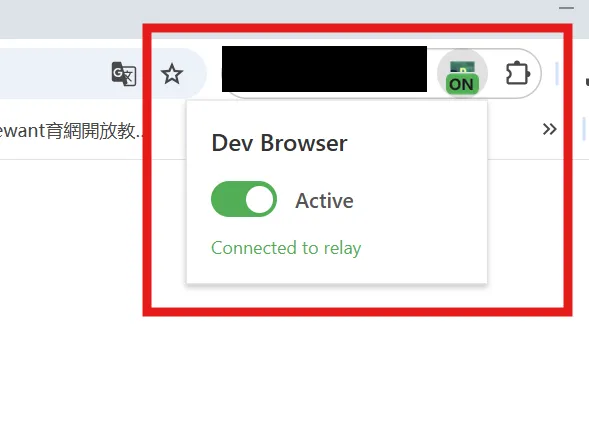
第三步:启用插件
安装完会看到扩展列表里多了个图标
重要:点击扩展图标,把它打开
很多人装完之后不开启,然后一直报错——我一开始也犯过这个错
完事。
配合 Claude Code 使用
装好之后,在 Claude Code 里就多了个能力
我来演示一下抓取 1688 供应商报价页的场景(之前做采购分析用的)
场景:批量获取供应商信息
原来的方式:
-
一个个打开页面 -
复制产品名、价格、最小起订量、运费 -
粘贴到 Excel -
重复 100 次
一下午就没了
现在的方式:
在 Claude Code 里直接说:
打开 1688 搜寻小马宝丽这个商品,帮我提取前五大产品列表,包括名称、价格、起订量
Claude 调用 dev-browser,用你已经登录的浏览器去开页面
几秒钟,数据回来了

结合其他 skill 还能延伸出更多玩法——自动填单、批量抓数据、定时监控…

(那种成就感,真的很难形容)
我实际用过的几个场景
装了这个插件一周,这些场景都跑通了:
|
|
|
|
|---|---|---|
|
|
|
完整获取
|
|
|
|
|
|
|
|
|
|
|
|
正常读取
|
效率提升保守估计 10 倍
而且完全免费,没有订阅,没有限制
几个使用小技巧
用了一周总结的经验(踩过的坑就不让你再踩了)
1. 插件必须保持开启状态
每次启动 Chrome 之后,记得检查插件是否开启
我有两次报错折腾了半天,结果发现是插件没开
📝常见错误
Connection refused 或 WebSocket failed — 99% 是插件没开
2. 登录态要提前准备好
你想抓哪个站的内容,先用 Chrome 正常登录一遍
这样 Cookie 就有了,dev-browser 才能带着登录态去操作
3. 不要太贪心
虽然能突破反爬,但也别一秒钟发 100 个请求
网站还是会检测异常频率的
我的做法是每次请求间隔 2-3 秒,稳得很
对比传统方案
|
|
|
|
|
|---|---|---|---|
|
|
|
|
极低 |
|
|
|
|
自动带上 |
|
|
|
|
基本无感 |
|
|
|
|
几乎为零 |
|
|
|
|
所有人 |
📝个人结论
如果你不是专业爬虫工程师,只是偶尔需要抓点数据,dev-browser 够用了
局限性也说一下
不是万能的,这几种场景还是有问题:
- 需要复杂交互的
(比如连续点击 10 个按钮才能看到内容)——还是得用 Playwright 写脚本 - 大批量抓取的
(几万个页面)——这种场景本来就该用专业爬虫 - 实时性要求高的
——每次都要开浏览器页面,速度比不上 API 直接调用
但对于大多数场景——
抓文章、导数据、监控价格——足够了
最后
这周把这个工具配置好之后,我做了个自动化流程:
每天早上自动抓取 5 个竞品的新品上架信息,整理成表格发我邮箱
以前要花 2 小时的事情,现在睡醒就躺在收件箱里了
📝GOLDEN
工具的价值不在于它有多复杂,而在于它能省下多少时间
———————————————————————–
在学习AI编程的路上,老徐AI编程做产品的知识星球给了很多的帮助
每个月都有训练营可以参加( 参加星球的伙伴们免费)
基本上0基础的小白都能轻易地入门(就是我啦)
想要一起加入AI编程的行列,但是又没有好的入门管道的朋友们,欢迎一起加入切磋
留言或后台私信”AI编程”,将提供过去这几个月以来,学习AI编程的一些资讯以及创建的个人知识库(每日更新)
【ima知识库】AI编程工具资料库 https://ima.qq.com/wiki/?shareId=2e1dc0ad31a15e3fc6e8b1954f4c0647ba3bd6ee86244230246d4933d160a02f
我用Google Antigravity开发工具的过程请参考
Day18 手把手教你安装Google Antigravity!搭配Gemini 3.0 Pro,编程效率翻倍
Day19 Google AI Studio+Anitgravity黄金组合!零基础也能搞定代码复刻
Day20: Google Antigravity界面到输出全中文改造,小白也能秒上手
Day21: 设置3步搞定!让你的Google Antigravity从此自动写代码、自测运行
Day22 : Google AI Studio 从Build到Anitgravity,程序员会被全链路“承包”吗?
Day23 超详细!Supabase配置GitHub/Google登录指南,附Claude对话秘籍
Day28 终极对决!Anitgravity双核驱动:Claude Opus 4.5硬刚Gemini 3.0 Pro
Day29 无需切换工具!Claude+Gemini交叉评估,高效产出PRD的终极工作流
我是贺伯,一个35+的工厂IE主管,正在用工业思维拆解AI编程,每天记录我从0基础到用AI赚到第一块钱的全过程。
