 夜雨聆风
夜雨聆风





Soul APP 开源首个 14B 实时数字人!0.87秒延迟+32fps,冲进 I2V 趋势榜 TOP5!
在很长一段时间里,AI圈对“数字人”这三个字是爱恨交加的。
爱它的人,看到了元宇宙、24小时直播带货、无限可能的虚拟陪伴;恨它的人,理由则更直接——太假、太慢、太僵硬。
特别是那种 “时延感”和“割裂感”,会瞬间打破了所有关于交流的幻想。
这就陷入了一个死循环:想聪明,就得上大模型(参数量大);上了大模型,推理速度就慢,延迟就高。鱼和熊掌,似乎不可兼得。
但最近,国内社交巨头 Soul App 旗下的 AI 团队(Soul AI Lab)突然扔出了一枚重磅炸弹——开源了实时数字人生成模型 SoulX-FlashTalk。


这款模型的参数量高达 14B,这在实时数字人领域简直是“巨无霸”级别的存在。但离谱的是,它竟然跑出了 0.87秒的亚秒级延迟和 32fps 的电影级帧率。
SoulX-FlashTalk是首个在 14B 参数规模下,实现亚秒级延迟(0.87s)、32FPS、高保真、超长稳定生成的实时数字人模型。
核心亮点
-
• 0.87s亚秒级延时:14B 级大模型,第一次具备“即时反应能力”。无论是视频通话还是直播弹幕互动,均表现自然、流畅。 -
• 32fps高帧率:在 14B DiT 架构下,仍然能维持 32 FPS 持续推理吞吐。超越行业标准,远超直播所需的 25 FPS 实时标准,确保每一帧画面都丝滑顺畅。 -
• 超长视频稳定清晰生成:凭借独家的自纠正双向蒸馏技术,保持身份一致、画面稳定、画质无损。 -
• 全身动作交互:不仅限于对口型,还支持全身肢体动态合成、高精细手部表现,实现了动作灵活性与画面稳定性的完美平衡。
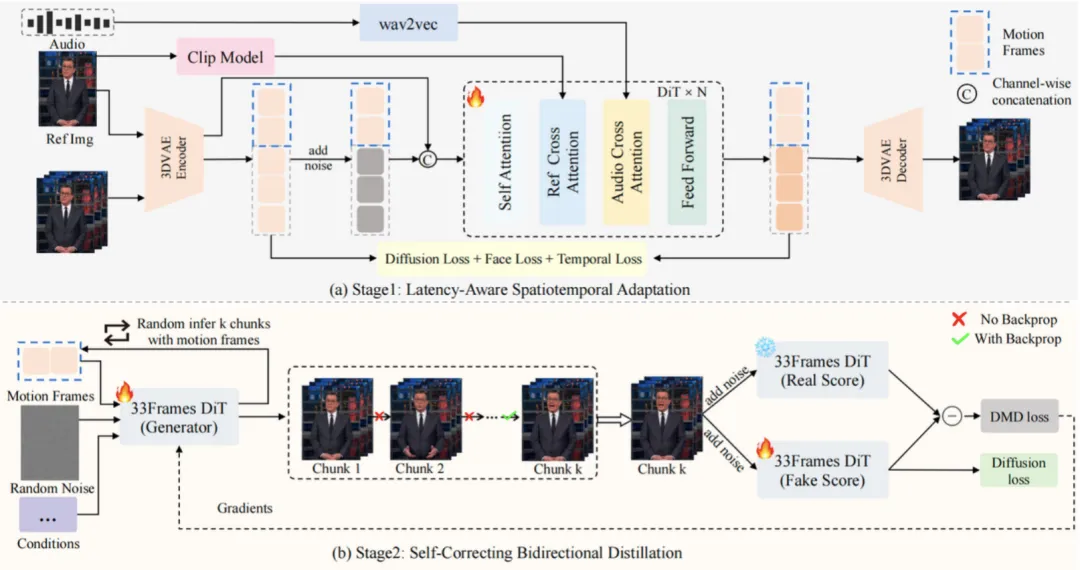
核心架构
SoulX-FlashTalk 并不是“某个技巧”,而是一整套系统级工程方案。
主要包含四大组件:
-
1. 3D VAE(WAN2.1) -
• 高分辨率视频潜空间压缩 -
• 为实时生成降低计算负担 -
2. 14B DiT 生成器 -
• Diffusion Transformer 架构 -
• 全 3D 注意力 -
• 多模态交叉注意力(图像/文本/音频) -
3. 条件编码器 -
• 中文优化 Wav2Vec(语音) -
• CLIP(图像特征) -
• umT5(中英双语字幕) -
4. 潜变量输入构建 -
• 历史运动上下文 -
• 带噪潜变量 -
• 参考图像指引 -
• 帧间 + 通道级拼接
核心目标只有一个:在快的同时,防止误差滚雪球。
两阶段训练
第一阶段:延迟感知时空适配
针对低分辨率、短帧序列、动态长宽比分桶,让模型先适应“快”。
第二阶段:自纠正双向蒸馏 + DMD 加速
这一阶段,核心目标是为“长时间稳定”而训练,让模型学会“抢答”和“纠错”。
客观指标
在 TalkBench 的短视频 & 长视频评测中:
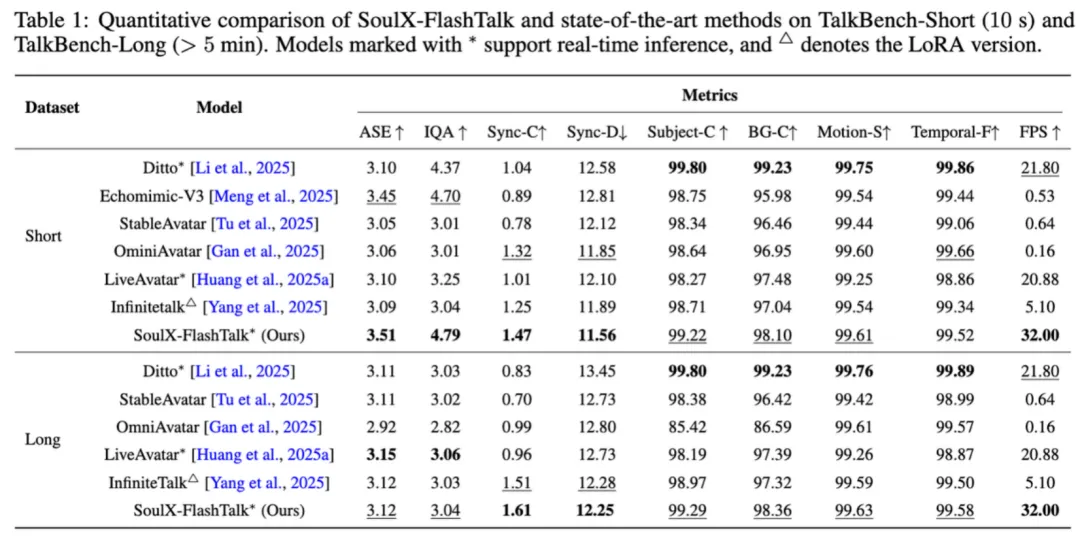
-
• 视觉保真度(IQA):4.79(新纪录) -
• 口型同步(Sync-C):短视频 1.47/长视频 1.61 -
• 吞吐:始终维持 32 FPS
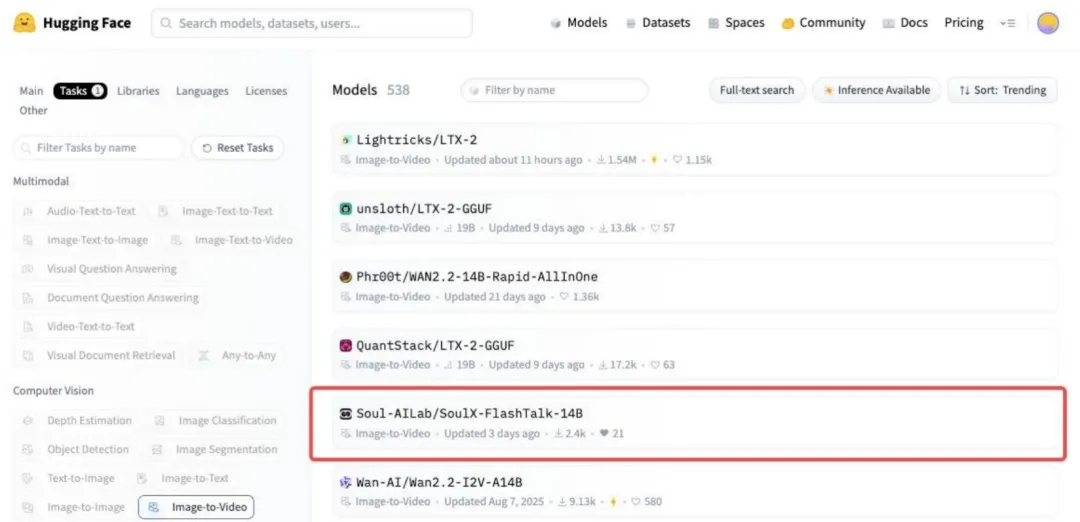
并且已经冲进 HuggingFace I2V 趋势榜 TOP5。
应用场景
-
• 7×24 小时 AI 直播间:电商数字人主播、超长直播不崩、实时回复弹幕 -
• AI 虚拟导师/智慧客服:银行柜员、在线教育、类视频通话体验 -
• 高质量短视频/短剧批量生产:一段音频直接生成完整视频,无动捕、无后期,长视频质量一致 -
• 游戏中的实时 NPC:语音驱动、情绪与动作联动、非脚本式对话
写在最后
SoulX-FlashTalk 是目前开源界参数量最大(14B)且延迟最低(<1s)的数字人解决方案。
可完全进行大规模商用,Soul 这一次,确实走在了行业的前列。他们不仅解决了一个技术难题,更重要的是,他们把这个解决方案开源了。
对于开发者和企业来说,这意味着我们可以站在巨人的肩膀上,去构建属于自己的、有温度的、实时的数字人应用。
参考链接:
项目主页:https://soul-ailab.github.io/soulx-flashtalk/GitHub:https://github.com/Soul-AILab/SoulX-FlashTalk模型:https://huggingface.co/Soul-AILab/SoulX-FlashTalk-14B

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️

