 夜雨聆风
夜雨聆风





ST-Link 高速烧录的秘密.上(源码解读)
我每天最快乐的时候就写文章,今天的文章也是我很久的困惑,在完全搞通的一瞬间,世界清明,当然是先昏迷了一个小时。
那今天写什么呢?今天写计算机组成原理的一部分;两天前我在看这个ST-Link 的开源代码(需要注意的是,其实是开源了USB控制协议这部分的内容,烧录器固件本身源码是不开放了),PC 端软件 (本项目) 负责发号施令;通过 USB 发送命令给 ST-Link。
ST-Link 固件 (闭源) 运行在 ST-Link 那个小盒子里的 STM32 芯片上。负责接收 USB 命令,并转换成 SWD/JTAG 信号去控制目标板;ST 官方并没有开源这部分固件,通常是通过 ST 官方的工具(如 ST-Link Utility 或 STM32CubeProgrammer)来升级这个固件。

从烧录高速的秘密出发
我们都知道烧录程序STLink还挺快的,其实秘密就是— RAM 注入 ;实现的时候是在主机端用 Flash Loader来实现。
Flash Loader 的做法 (PC通过USB直接写数据到MCU)
在PC 端每次只拿 4个字节的数据;PC 喊一句“写入这4个字节”,数据爬过 USB 线;在MCU 端收到4个字节 -> 解锁 Flash -> 写寄存器 -> 等待写入完成 -> 发回“好了”,这齐总大量的时间浪费在 USB 通讯的一来一回上,实际写 Flash 的时间占比很小。
另外直接通过 SWD 协议往 Flash 里写数据是非常慢的。因为每写一个字(Word),都要经过一堆复杂的 Flash 控制器寄存器操作(解锁、设置编程位、等待忙状态等)。
为了加速,stlink 采用了一个聪明的办法:先把一小段“搬运工程序”(即 Flash Loader)上传到 MCU 的 RAM 里,然后把要烧录的数据块也上传到 RAM 里;之后让 MCU 的 CPU 跑这段 RAM 里的“搬运工程序”;因为 CPU 访问 Flash 控制器是片内总线速度,比 USB 转 SWD 快得多,所以“搬运工”能飞快地把 RAM 里的数据搬到 Flash 里。
STM32 的 Flash 写入速度其实是有限的,但 USB 通讯延迟(Latency)是更大的瓶颈;通过把数据先缓存到 RAM,再让 MCU 自己去写,就完美避开了 USB 通讯的频繁交互延迟。
这些神秘都写在代码的字里行间,又想起来大学时候天天读源码的日子了,当然了,也看不大懂。
神秘的十六进制数组 (Loader Code)
在 flash_loader.c 开头(第 38-179 行),会看到很多 static const uint8_t loader_code_xxx[] 数组。
static const uint8_t loader_code_stm32vl[] = { 0x00, 0xbf, 0x00, 0xbf, ...};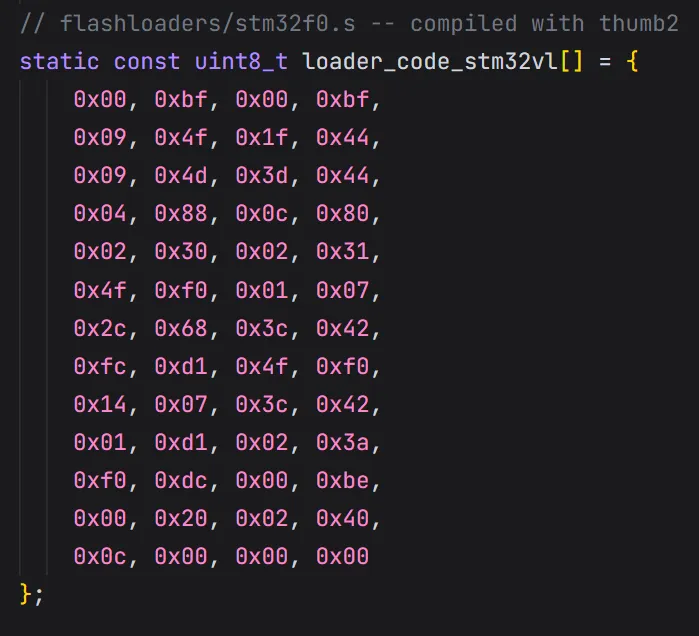
这些其实是汇编代码编译后的机器码 ! 它们对应的源文件在 flashloaders/ 目录下(如 stm32f0.s );这些机器码就是那个“搬运工程序”;不同的芯片(STM32F0, F4, L4, WB 等)Flash 控制器的操作方式不同,所以需要不同的搬运工。
stlink_flash_loader_init (初始化)
这个函数(第 182 行)负责准备工作:先暂停 CPU,通过发送 STM32_REG_DHCSR_C_HALT 让 MCU 停下来;接着屏蔽中断,为了防止烧录过程中被中断打断,导致 Flash 损坏;开始写入 Loader,通过调用 stlink_flash_loader_write_to_sram 把上面那些机器码数组写到 MCU 的 SRAM 起始位置(通常是 0x20000000 )。
(3) stlink_flash_loader_run (执行)
这是核心执行函数(在头文件声明,实现在 .c 文件的后半部分):先设置 PC 指针,把 MCU 的程序计数器 (PC) 指向 RAM 里的 Loader 代码地址;通过寄存器(R0, R1, R2, R3)把“源地址”、“目标地址”、“数据长度”传给 Loader;发送 RUN 命令让 CPU 跑起来;程序进入等待结束,也就是轮询检查 CPU 是否停下(Loader 跑完会自动断点停机)。
这两个文件实现了“特洛伊木马”式的烧录策略:

flash_loader.h : 定义了“木马”的接口。
flash_loader.c : 包含了各种型号的“木马”实体(机器码数组),以及把它们塞进 MCU 并激活的逻辑;如果发现某个新出的 STM32 芯片烧录特别慢(只有几 KB/s),很可能是因为 stlink 还没适配它的 Flash Loader,只能用慢速的 SWD 直接写。要解决这个问题,就需要去 flashloaders/ 目录下写一个新的汇编程序,编译成机器码放进这里。
进入MCU的世界
MCU 代码可以在 RAM 里面运行吗?
答案是肯定的,不仅可以,而且非常快;对于 ARM Cortex-M 架构的 MCU(如 STM32)来说,CPU 核心访问 RAM 和 Flash 都是通过统一的内存总线。对于 CPU 而言,地址 0x08000000 (Flash) 和 0x20000000 (RAM) 没什么区别,只要那个地址里有指令,它就能取出来执行。
事实上,在 RAM 里运行代码通常比在 Flash 里更快,因为 Flash 的读取速度较慢(通常需要插入等待周期),而 RAM 通常是零等待周期的。
分析 RAM 里面的程序是什么样的?
在flashloaders/stm32f4.s 就是一个绝佳的例子;这个程序非常“极简”,而且它是一个位置无关 (Position Independent) 的汇编代码片段。 这段代码总共只有几十个字节,它的逻辑非常简单粗暴:
.global copycopy: ldr r12, flash_base ; 加载 Flash 寄存器基地址 (0x40023c00) ldr r10, flash_off_sr ; 加载状态寄存器偏移量 (0x0e) add r10, r10, r12 ; 计算出 FLASH_SR 的绝对地址loop:# 1. 搬运数据 (Copy 4 bytes) ldr r4, [r0] ; 从源地址 (R0, RAM) 读 4 字节 str r4, [r1] ; 写到目标地址 (R1, Flash) ; 注意:这一步写入动作会触发 Flash 控制器的编程 操作# 2. 指针自增 add r0, r0, #4 ; 源地址 + 4 add r1, r1, #4 ; 目标地址 + 4wait:# 3. 等待忙 (Wait Busy) ldrh r4, [r10] ; 读取 FLASH_SR 寄存器 tst r4, #0x1 ; 检查 BSY 位 (Bit 0) bne wait ; 如果 BSY=1,就跳回 wait 继续等# 4. 循环控制 subs r2, r2, #4 ; 剩余字节数 - 4 bgt loop ; 如果还有数据,跳回 loop 继续搬exit: bkpt ; 断点指令!程序执行到这里会自动停机首先这个程序没有 main 函数,没有堆栈初始化,没有中断向量表;它就是一段裸奔的指令序列。
依赖寄存器传参 :它假设在运行前,外部(PC 端)已经把参数填到了 CPU 寄存器里:
R0 : 源数据在 RAM 的地址。
R1 : 目标 Flash 地址。
R2 : 数据长度。
以 bkpt 结尾,表示它不执行 return ,而是执行 bkpt (Breakpoint);这会让 MCU 进入调试暂停状态,这样 PC 端通过 SWD 轮询状态时,发现 MCU 停了,就知道“活干完了”。
为什么 MCU 可以运行这样的程序?它完整吗? 它完整吗?

从传统 C 语言程序的角度看,它完全不完整 。它没有启动文件(Startup Code),没有 C 运行时环境(CRT),没有中断向量表,甚至没有栈(Stack)。但是,从机器指令执行的角度看,它是完整且自洽的;CPU 只要被告知 PC 指针在哪里,它就会傻傻地去那里取指令执行。只要这段指令不依赖那些缺失的东西(比如它没有调用 printf ,没有申请 malloc ,没有使用中断),它就能完美运行。
为什么能运行?
stlink 在运行这段代码前,会先让 MCU 停机(Halt),并屏蔽所有中断,这时候整个 MCU 的现场被冻结了。(就是 MCU 是在干活的状态),接着stlink 通过调试接口,直接修改 CPU 的寄存器(R0~R3, PC, SP);这里把 PC 指针强行指向 RAM 里这段代码的起始位置,把 SP (堆栈指针) 指向 RAM 的末尾(防止溢出,虽然这段代码其实没怎么用栈)。
这段代码不依赖任何操作系统或库函数,它自带了所有需要的逻辑(循环、读写寄存器),在执行完 bkpt 后,这个外置的控制程序部分撤走(MCU 停机),stlink 恢复现场(或者复位芯片);RAM 里的这段程序,是一个“寄生”在裸机环境下的微型函数,它不需要完整的操作系统支持,因为它本身就是去执行一个最底层的硬件操作;这就是嵌入式调试器的高明之处: 利用 CPU 本身作为协处理器,来加速调试器想要完成的工作。
