 夜雨聆风
夜雨聆风





史上最强OCR模型GLM-OCR,文档解析新卷王!
最近 OCR 模型神仙打架,更新频次非常高。先是 DeepSeek 推出了 DeepSeek-OCR 2,紧接着百度飞桨推出 PaddleOCR-VL-1.5,现在智谱的 GLM-OCR 能力也跟上了。
这圈子真的卷,每个新模型出来都是刷新 SOTA。几天前还在王座,转眼就得退居二线。说实话,现在大模型竞争这么激烈,没有深厚算力储备和数据资源的公司,真的不适合再去卷这种底层模型了。
今天咱重点聊聊 GLM-OCR。相比市面上其他模型,它到底强在哪?
第一,文档解析能力确实是目前最牛的。在专业的文档解析数据集 OmniDocBench V1.5 上,以94.62分登顶,打败了 PaddleOCR-VL-1.5等竞品。这意味着,pdf文档解析效果更上一层楼。
第二,处理速度非常快。GLM-OCR 在处理 PDF 文档时的吞吐量达到 1.86页/秒,图像处理速度也能达到 0.67幅/秒 左右,这个效率比很多同类竞争对手都要强。
第三,模块化程度高。GLM-OCR 的各个模块是可以组合的。你可以基于它已有的模块(如版面分析)进行轻松定制,创建自己的流水线。
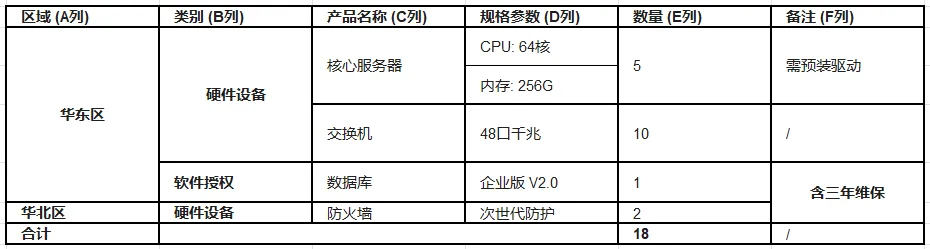
来,我给大家展示一下对于表格的识别效果。
识别前:
识别后:
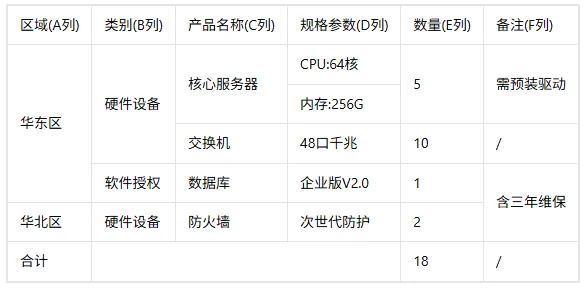
可以看到,即使是这种带有复杂合并单元格的表格,它的识别效果依然非常不错。
最后说说参数和部署。
这个模型非常轻量,参数量只有0.9B,而且是完全开源的。
-
上下文长度:支持 32K,长文档毫无压力。
-
输入格式:支持 PDF 和图片(JPG/PNG),PDF 单次最大支持 100 页,并且支持多语言识别。
-
部署方式:非常灵活,支持 API 调用,也支持私有化部署。
-
价格:这点最良心,API 调用的费用非常便宜。不管是输入还是输出,价格都打到了 0.2 元 / 百万 Token,白菜价。
END
我是文如刀,从天坑专业土木成功上岸AI产品经理,现任 AI产品线负责人 | 面试官。专注分享AI产品实战干货。
– 推 荐 阅 读 –
