夜雨聆风
夜雨聆风





PDF不好处理?用Deepseek OCR解析PDF文件,免费又高效(附教程)
真迅速!Deepseek OCR刚捂热,配套的应用开发平台就开源了(附部署教程)
医疗自由了!微调Qwen2.5 VL医疗专家模型接入小程序,医学生表示坐不住了!
效果秒出!用Index-TTS模型做了一个语言克隆平台,这回是真正AI落地了(附教程)
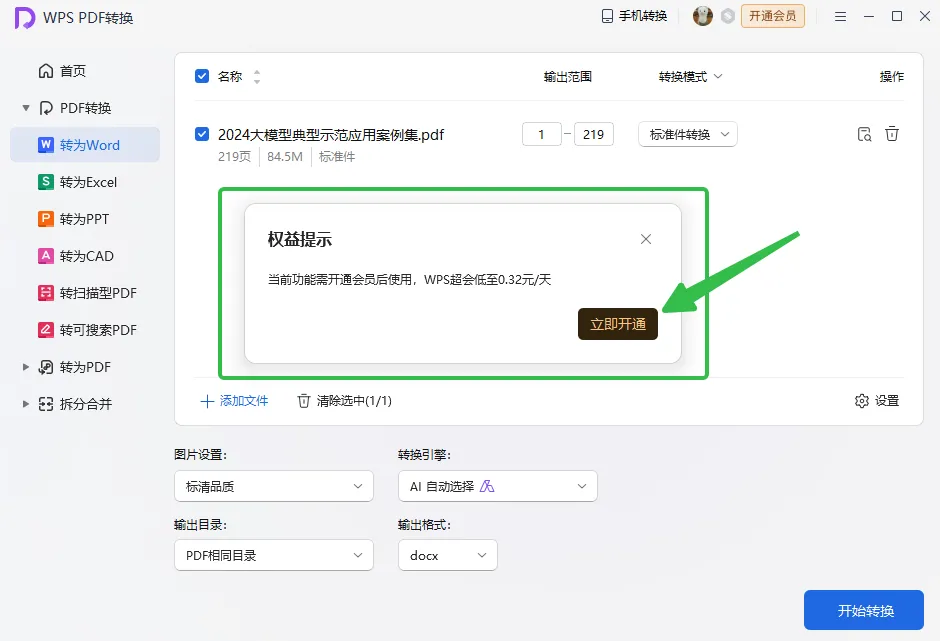
在平时处理PDF文件中,你是否又遇到想把其中的内容原封不动的解析出来,同时保持其样式和布局都不受影响,问了一圈发现:身边很多小伙伴基本用的最多的就是WPS中的付费功能了~
不是吧?什么年代了?还有人不知道如何免费且高效地将PDF解析成Word/Markdown文档~
PDF处理神器:MinerU

我真的非常推荐你,使用这个叫MinerU的PDF处理工具
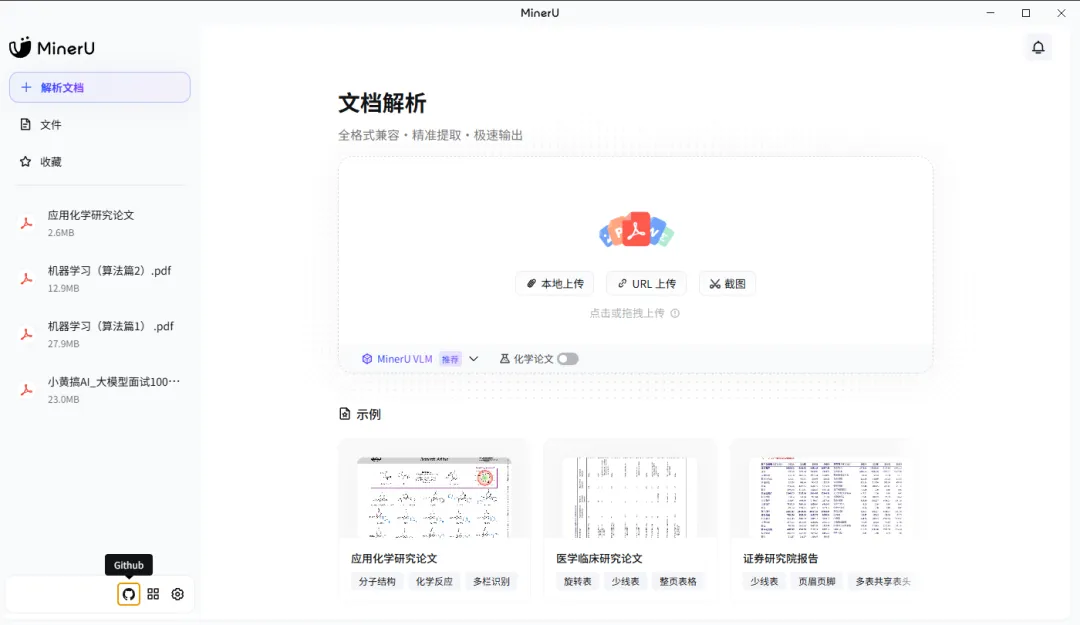
MinerU是上海人工智能实验室OpenDataLab团队正式推出了智能数据提取工具。它可以将混合图片、公式、表格等复杂多模态 内容的PDF 文档转化为Markdown文档,该工具在Github上是完全开源且免费的,而且同时还推出了桌面端,直接下载即可在本地进行使用~
OpenDataLab团队针对PDF的场景,专门训练了这个多模态处理模型MinerU VLM,经过实验发现其在复杂的数据公式和图片数据的处理方面确实是已经达到了直接生产可用的效果,整个过程都是完全免费的哦~
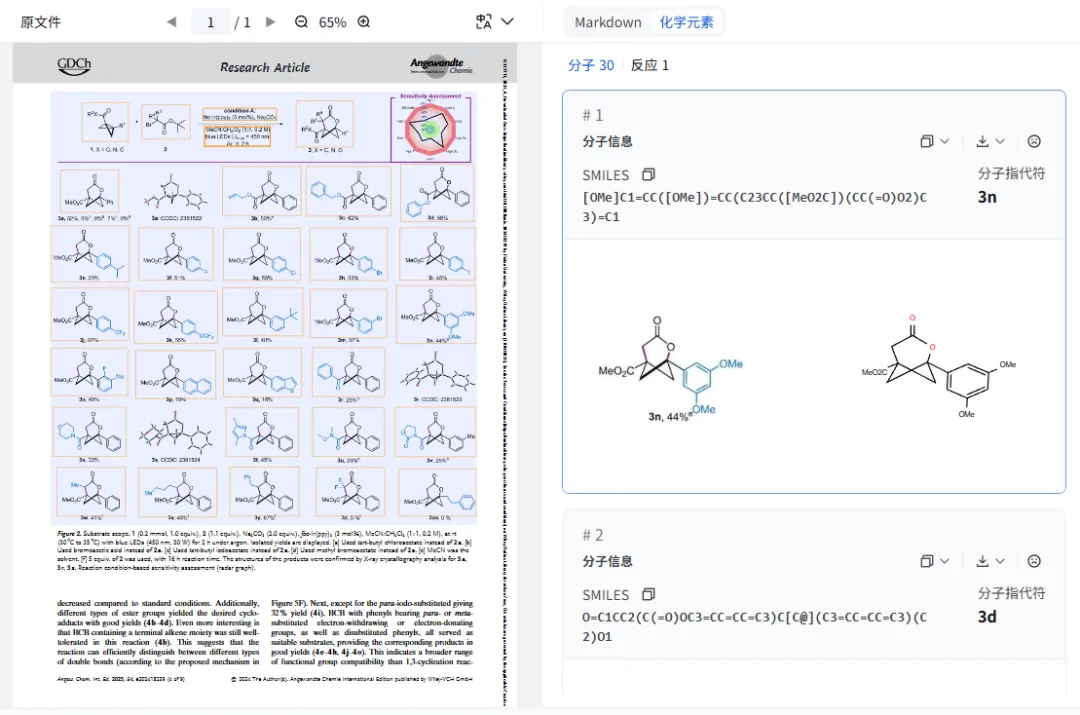
下载网址: https://opendatalab.github.io/MinerU
打造DeepseekOCR处理PDF工具
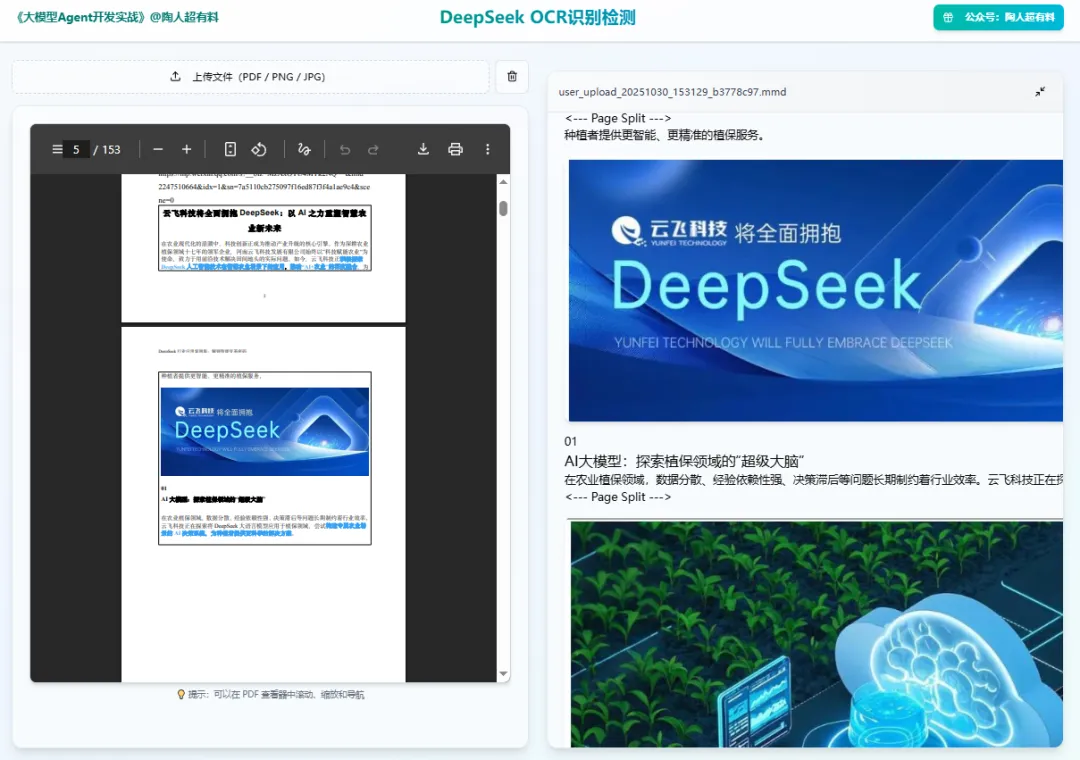
除了MinerU VLM模型之外,刚出来的Deepseek OCR模型在PDF文件识别领域也是非常给力,根据测试,deepseekocr模型可以使用更少的Token开销达到跟MinerU模型一样的效果~本着油多不坏菜的原则,既然都是免费的,那何不把DeepseekOCR这个模型也用起来,将其打造成一个PDF识别的利器!
1、效果展示
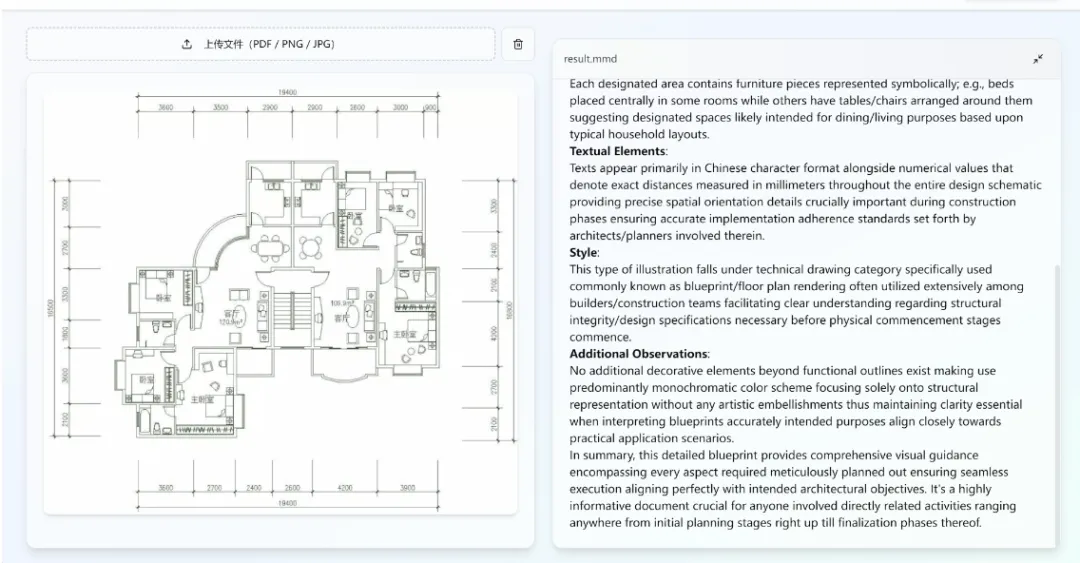
(1) 图表识别
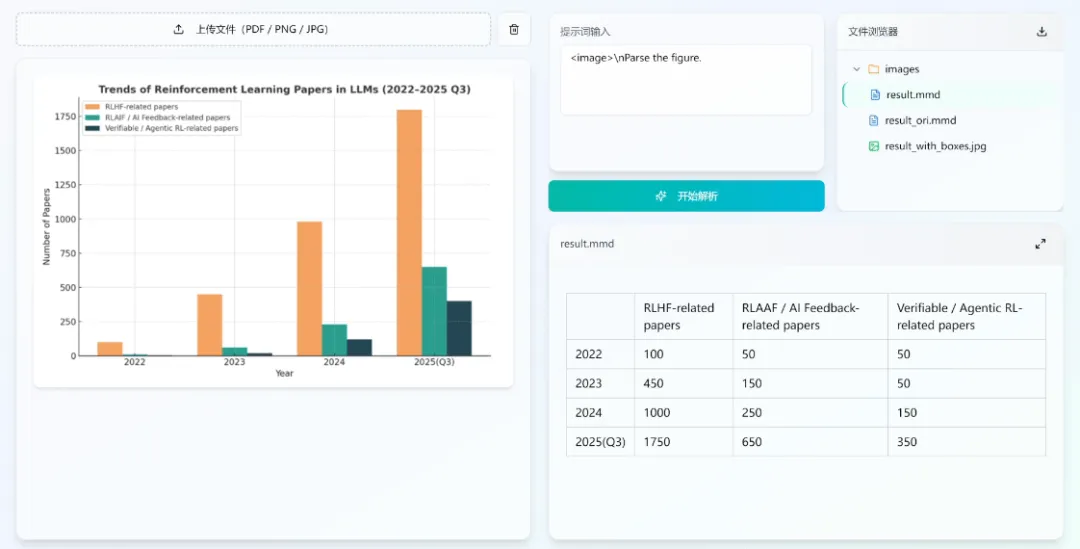
(2)支持多语种
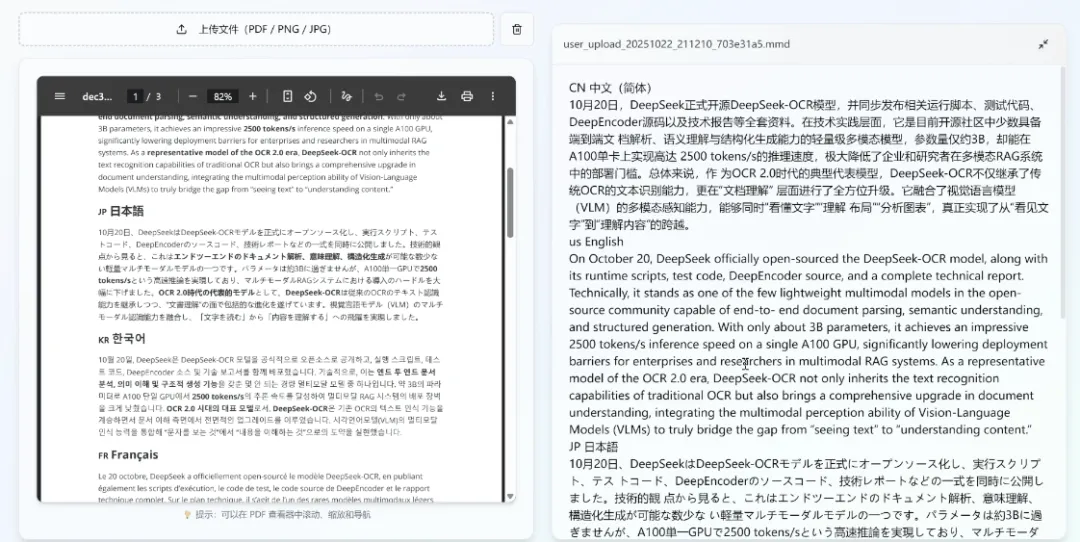
(3)设计图解读
2、部署教程
-
0. 准备开发环境
有看过前几期我们部署模型的教程的小伙伴应该很熟悉了,为了避免配置开发环境的版本兼容问题,直接将时间用在最重要的地方,我们往往都是选择AutoDL算力平台中的容器进行部署~
老规矩,我们这次同样是租用了一台带有4090D显卡的机器:
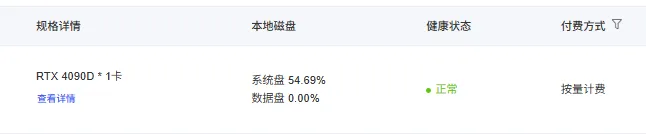
特别注意的是,我们在算力市场选择4090D显卡的时候,需要对相应的cuda版本进行筛选,因为不同机器的cuda版本可能不相同,万一不兼容,哭爹喊娘都是搞不定的,具体的软件版本的选择可以参考如下:

具体如何租用算力资源,可以参考往期的项目教程,里面有详细的操作步骤~
在开好机器之后,我们下一步就是将模型下载好,这个DeepseekOCR模型整体来说不算大,总共也就6G多,这里我们使用阿里的这个魔搭平台中的SDK下载(模型地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-OCR)
在autodl-tmp文件夹下,执行以下命令就可以完成模型的下载:
pip install modelscopemkdir ./deepseek-ocrmodelscope download --model deepseek-ai/DeepSeek-OCR --local_dir ./deepseek-ocr-
1. 准备PDF文件处理脚本
构建一套功能完备的PDF文件处理系统第一步,就是先打造好一套接口完整数据接入API系统~
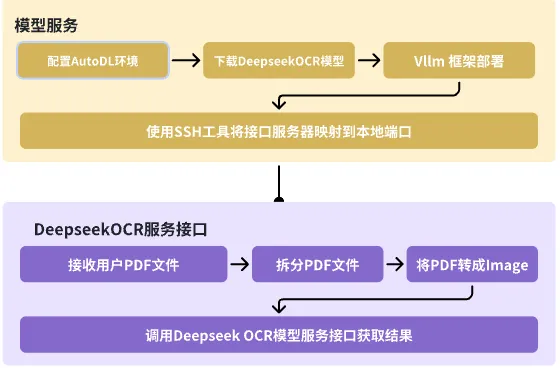
支持Deepseek OCR模型的APi项目: https://github.com/fufankeji/DeepSeek-OCR-Web
这个项目在Deepseek-OCR官方项目的基础上,进一步开发出了提供外部API接口的后端服务,同时也配备了功能齐全的前端操作交互界面~
Deepseek-OCR官方项目:https://github.com/deepseek-ai/DeepSeek-OCR(官方项目已经将如何使用模型对PDF文件+Image文件类型,进行功能推理的脚本已经写好了)
这里我们先将这个项目中的后端系统, 也就是backend文件夹中的脚本代码启动起来~在启动之前,我们需要修改一下项目文件中的.env配置,将我们上一步所下载的模型地址配置到项目中,在.env中修改如下:
MODEL_PATH=/root/autodl-tmp/deepseek-ocr由于我们的所选择的容器镜像中已经有Python的环境了,这个时候我们就可以直接执行以下指令完成项目的启动:
先安装项目依赖
pip install -r requirements.txt然后可以顺利启动项目
uvicorn main:app --host 0.0.0.0 --port 8002 --reload-
2. 将服务映射到本地
在我们上一步已经将后端服务启动起来之后,要如何在本地或者在远程服务器上可以调用到呢?
AutoDL平台提供了一个SSH隧道工具,可以将其容器中的服务端口暴露在你的目标机器中,让你实现像调用本地服务一样的方式来调用远程服务~
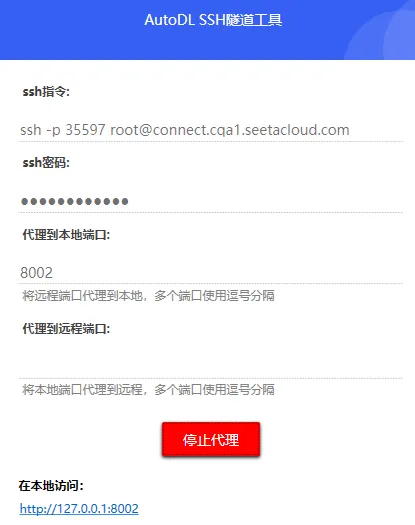
我们将后端服务启动在了8002端口,所以我们在工具中直接填写8002,然后我们在本地电脑上就可以直接使用127.0.0.1:8002这个地址来进行访问了~
3.启动前端服务
最后,也是最关键的一步!所有后台的服务做的再好都离不开一个交互流畅功能完备的前端界面~
在这个项目中我们直接进入到frontend文件夹中,然后执行如下命令:
-
• 需要先安装好node环境,然后使用 npm包管理来完成依赖的安装
npm install-
• 然后就可以进行项目启动了~
npm run dev-
• 系统支持图片和pdf文件的上传,同时也支持特定prompt要求的定制化~