 夜雨聆风
夜雨聆风





国产算力筑基新质生产力,大模型解锁全球文档新潜能
企业数字化转型进入2.0阶段,海量PDF文件作为核心信息载体,却因扫描干扰、图文混杂等解析痛点难以复用,成为大模型项目交付的阻碍。登临科技携纳适系列PDF解析解决方案,为数字化转型破局赋能。
行业背景
从纸质文件转换为电子文件,在企业数字化 1.0 的转型浪潮中,PDF已成为全球政商业最广泛使用的文件格式,更是行业公认的默认标准。据 Mobiqode 2025 年发布的数据显示,全球现存 PDF 文件超 2.5 万亿份,年新增超 2900 亿份。当 PDF 成为信息海洋的主体,PDF信息的结构化解析便成为了大模型应用的核心战场。
大模型赋能推动企业数字化迈入 2.0 新阶段,正当企业与 IT 从业者满心期待地复用1.0时代积淀的海量 PDF文件时,却遭遇了重重阻碍: PDF 电子文件生成过程中,难免受扫描伪影、倾斜、扭曲、屏幕翻拍、光照等外部因素干扰,同时,纸质文书资产本身存在图文表混杂、表格跨页、多语言混排等情况。在这些制约下,将 PDF 文件转化为 Word、Markdown 等结构化文档格式变得异常困难。
大模型业内方案
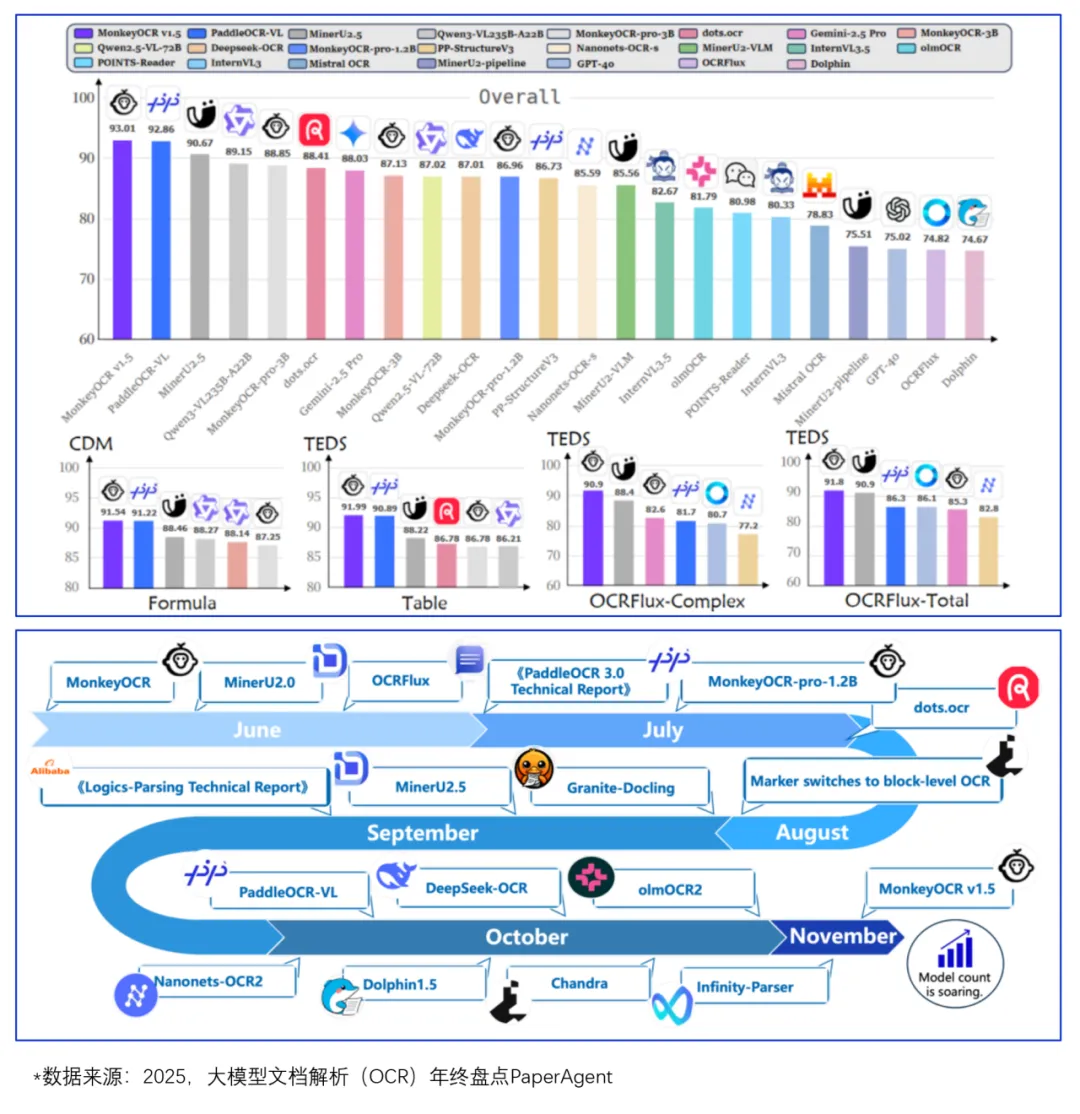
2025-2026 年,登临科技携手合作伙伴完成众多大模型项目落地,覆盖合同、卷宗、论文等多类文档解析场景。合作过程中各方形成核心共识:以 PDF 为主要载体的原始文档,其结构化解析的精准度是大模型项目顺利交付的关键要素。若原始文档解析环节存在偏差,后续即便对大模型进行精细化微调或优化工作流,也无法实现符合预期的交付效果。
这一行业痛点已引发大模型领域广泛关注,2025 年第四季度,行业头部企业集中发布多款基于多模态大模型的 OCR 解决方案,持续刷新OCR行业SOTA,为解决PDF文档结构化困难提供全新路径。
登临最佳实践方案发布
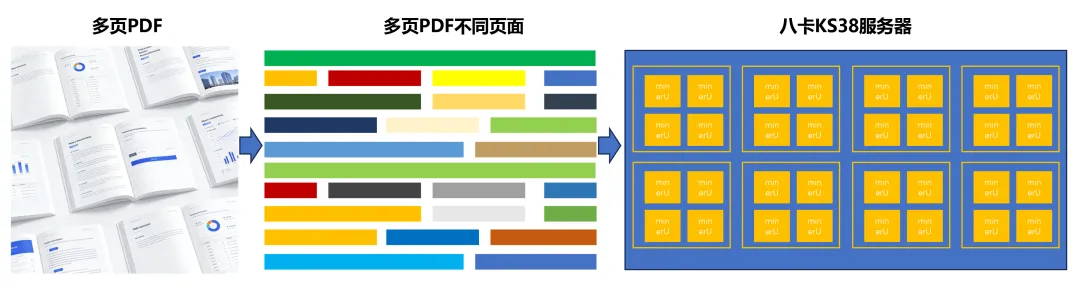
为了让合作伙伴们的企业数字化项目快速得到国产算力的支撑,登临基于纳适系列国产化GPU,推出文档PDF解析行业解决方案:
-
最佳模型:目前登临已支持到VLLM0.13.0版本,支持PaddleOCR-VL-1.5、MinerU2.5、deepseek-OCR、dots.OCR等排名靠前的多模态大模型的OCR方案,并对排名前二的PaddleOCR-VL-1.5和MinerU2.5完成深度性能优化。
-
专注落地:着眼于真实业务中会遇到的多页PDF(上百页的论文报告、几百页的卷宗、几千页的行业标准文档等),利用纳适系列KS38和KS58的特性,形成最佳实践方案,解决客户真实应用难题。
-
性能强悍:利用KS38/KS58的多计算核心配合负载均衡的调度策略,有效的解决多页文档差异化内容阻塞问题,在部分场景中性能达到甚至超过4090的性能。
登临科技以国产算力为支点,紧扣新质生产力发展要求,聚合顶尖多模态OCR模型,深耕真实业务落地场景。依托纳适系列的强悍性能,破解行业核心痛点,以更精准的解析能力和更高效的落地方案,释放海量PDF文档的潜在价值,以 AI 算力赋能实体经济提质增效,为新质生产力塑造新动能。
登临纳适™(Knuth™)系列
KS系列是基于登临科技GPU+计算架构的通用人工智能处理器,是基于自研软件栈和国产供应链生产的第一代产品。
登临科技自主创新的GPU+体系结构(软件定义的异构人工智能计算平台),完美地解决了通用性和高效率的双重难题,在提供具备CUDA/OpenCL硬件加速能力的前提下,不仅全面支持各类流行的人工智能网络框架及底层算子,且相对于国际主流推理卡在能效比上有3倍以上的提升。
目前,KS 系列已完成与国内一线服务器厂商的全面适配,提供2U4U服务器,aipc及工控机为客户在不同硬件方案,提供从方案到硬件部署的全套方案。
-
KS58面向智算中心,提供超高算力密度服务器方案。
-
KS38面向大模型一体机部署,提供本地化项目快速部署。
-
KS20面向AIPC和AIBOX部署,提供个人用户和边缘智能设备赋能。
