 夜雨聆风
夜雨聆风





百万token长文档问答新突破:InfMem让小模型准确率飙升10个点,推理速度快4倍
当文档长度突破百万token,传统大模型往往”迷失在中间”——关键证据被淹没在海量文本中,多跳推理所需的”桥接事实”在反复压缩中悄然丢失。这个困扰长文档问答领域的核心难题,终于迎来了一个系统性的解决方案。
论文提出了InfMem,一种面向超长文档问答的控制型agent框架。与被动式的流式处理不同,InfMem通过显式的”System-2风格”认知控制循环,主动监控证据充分性、执行定向检索、并在固定内存预算下进行证据感知的联合压缩。在百万token基准测试中,InfMem在Qwen系列模型上平均准确率提升超过10个百分点,同时通过自适应早停机制将推理时间缩短3.9倍(最高达5.1倍)。
长文档推理的核心困境
超长文档问答面临一个根本性的”保真度困境”:激进的分段压缩会抹去后续推理所需的微妙关联,而简单扩展原始上下文又会稀释注意力、让关键事实淹没在噪声中。
现有方法各有局限。长度外推技术(如YaRN)和高效序列建模(如Mamba)主要关注容量而非证据组织;RAG(Retrieval-Augmented Generation,检索增强生成)能检索相关片段,但结果往往碎片化、未能整合成紧凑的工作基底;有界内存agent(如MemAgent)虽然提供了常数级内存和线性计算复杂度,但依赖被动的反应式更新策略,无法在需要时回溯早期上下文以恢复缺失证据。
有效的有界内存长上下文处理需要从被动的分段压缩转向”System-2风格”的认知控制——一种显式的、任务条件化的、状态依赖的内存操作控制机制。
InfMem的核心设计
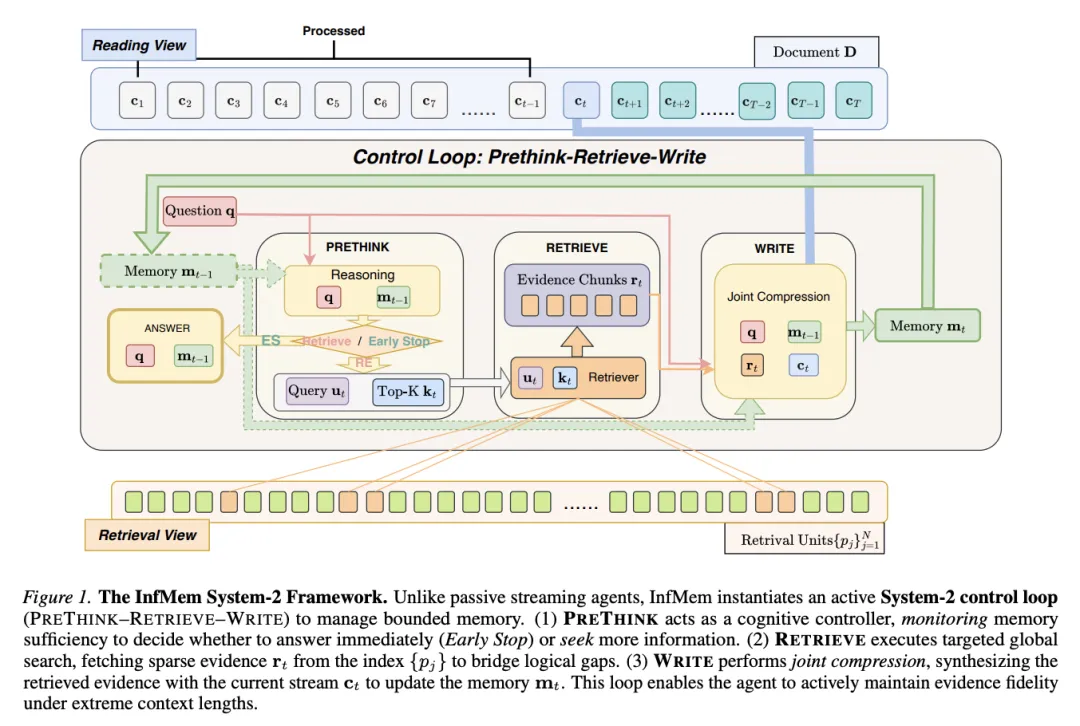
[Figure 1: InfMem System-2框架] 与被动流式agent不同,InfMem实例化了一个主动的System-2控制循环(PRETHINK-RETRIEVE-WRITE)来管理有界内存。PRETHINK作为认知控制器监控内存充分性;RETRIEVE执行定向全局搜索获取稀疏证据;WRITE执行联合压缩,将检索到的证据与当前流合成以更新内存。
InfMem将超长文档视为固定上下文预算下的受控证据流,而非单一的整体块。框架维护一个紧凑的内存状态作为LLM(Large Language Model,大语言模型)上下文窗口内的普通token,基础LLM架构和生成过程保持不变。
流式设置与表示:InfMem将文档分割为T个粗粒度的流式块进行顺序处理,同时维护一个有界内存状态(token序列),预算上限为M。为实现全局访问,InfMem预先构建了更细粒度的检索单元集合(如段落),这些单元紧凑且全局索引,允许agent跳转到文档任意位置检索相关内容。
控制循环协议:在每个步骤t,InfMem将有界内存视为中间状态,执行”监控-搜索-更新-停止”循环:
(1) PRETHINK(预思考):作为状态依赖控制器,仅基于问题和当前内存判断是否已有足够证据回答问题。若充分则输出”STOP”提前终止;否则输出”RETRIEVE”,同时合成检索查询并预测检索数量。
(2) RETRIEVE(检索):当触发检索时,从同一文档(非外部语料库)中检索top-k个相关检索单元,拼接成紧凑上下文。这种非单调访问允许agent在需要时回溯早期部分或检查后续章节以填补缺失支持。
(3) WRITE(写入):执行证据感知的组合与联合压缩——将检索到的支持与新观察到的内容连接,识别并编码组合关键事实和桥接链接到有界更新内存中。
(4) 早停与最终回答:一旦充分证据已整合到内存中,agent终止检索-写入循环,减少冗余迭代和不必要的覆写。
训练方案:从SFT到RL
InfMem采用两阶段训练方案,确保控制决策与端到端任务正确性对齐。
SFT(Supervised Fine-Tuning,监督微调)预热阶段:使用强教师模型(Qwen3-32B)蒸馏到较小的学生模型,提示模板严格镜像推理时的PRETHINK-RETRIEVE-WRITE循环。仅保留最终答案正确的轨迹,应用字符串/正则过滤器移除任何真实标签泄露。学生模型使用掩码下一token预测进行训练,仅在agent响应token上计算损失。
RL(Reinforcement Learning,强化学习)对齐阶段:从SFT检查点开始,应用GRPO(Group Relative Policy Optimization)进行多轮对话强化学习。InfMem设计了多组件奖励函数:
(1) 协议健全性验证器:函数调用验证器确保所有函数调用格式正确可解析;内存验证器确保每个内存更新步骤输出完整的UPDATEDMEMORY字段且不超出预算。
(2) 最终任务奖励:基于规则的真实标签奖励,根据官方基准评估协议计算。
(3) 早停塑形:奖励在内存首次变得充分后尽快停止,防止冗余覆写。设定衰减因子γ,当agent在首个充分内存步骤后立即停止时获得最大奖励。
实验设置与数据
InfMem在四个数据集上进行评估:SQuAD用于单跳抽取,HotpotQA、2WikiMultiHopQA和MuSiQue用于复杂多跳聚合。基础模型包括Qwen3-1.7B、Qwen3-4B和Qwen2.5-7B-Instruct。
SFT阶段使用学习率4.0×10⁻⁵,全局批量大小256。对于已优化推理能力的Qwen3-1.7B和4B,训练1个epoch;对于通用模型Qwen2.5-7B-Instruct,扩展到4个epoch。RL阶段每个提示采样4个rollout,采样温度1.0,KL散度系数0.001,学习率1×10⁻⁶。
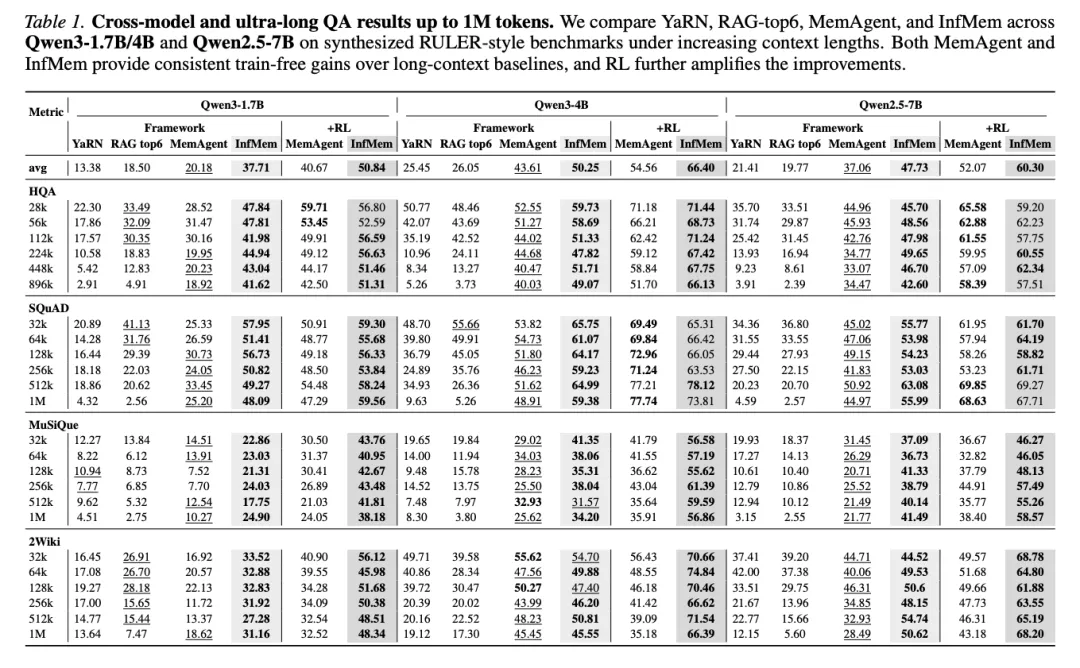
[Table 1: 跨模型和超长QA结果(最高1M token)] 在合成的RULER风格基准上比较YaRN、RAG-top6、MemAgent和InfMem。MemAgent和InfMem均提供一致的无训练增益,RL进一步放大改进。
核心实验结果
跨骨干网络结果:在合成长上下文QA基准上,标准长上下文基线在超长场景下急剧退化。YaRN在128k token之后出现明显性能悬崖,在1M标记处准确率常常崩溃到个位数(如Qwen2.5-7B上降至约4%)。RAG性能随信息密度降低而衰减,难以在百万token上下文中定位分散的决定性证据。
InfMem一致取得最强性能。虽然MemAgent在证据检索模式较简单的任务(如SQuAD)上保持竞争力,但在复杂多跳基准(如MuSiQue和2WikiMultiHopQA)上明显落后。RL-InfMem建立了决定性领先,在Qwen3-1.7B、Qwen3-4B和Qwen2.5-7B上分别比RL-MemAgent平均高出+10.17、+11.84和+8.23个百分点。
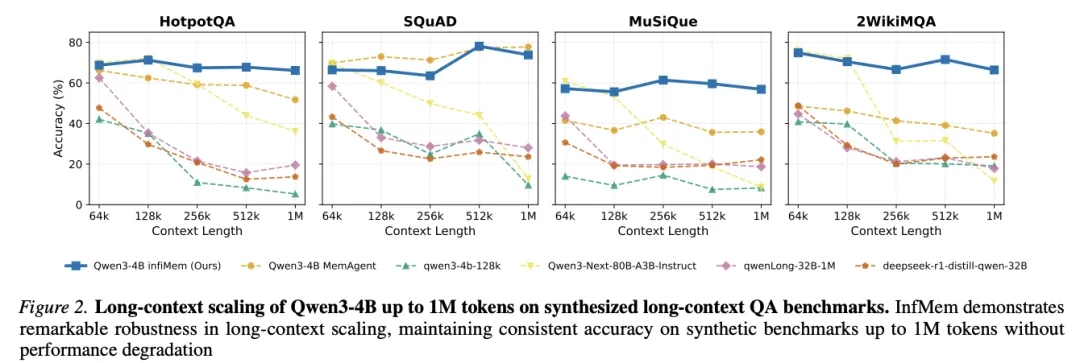
[Figure 2: Qwen3-4B在合成长上下文QA基准上的长上下文扩展(最高1M token)] InfMem在长上下文扩展中展现出卓越的鲁棒性,在合成基准上保持一致准确率直至1M token而无性能退化。
长度扩展行为:尽管扩展了上下文窗口,准确率在超长场景下往往恶化。InfMem在128K token之后保持显著更稳定,其优势随长度增长而扩大——尤其在多跳数据集上。InfMem将此归因于对检索和内存写入的充分性感知控制,这减轻了重复压缩带来的长期漂移,并能在更新内存前定向恢复缺失的桥接事实。
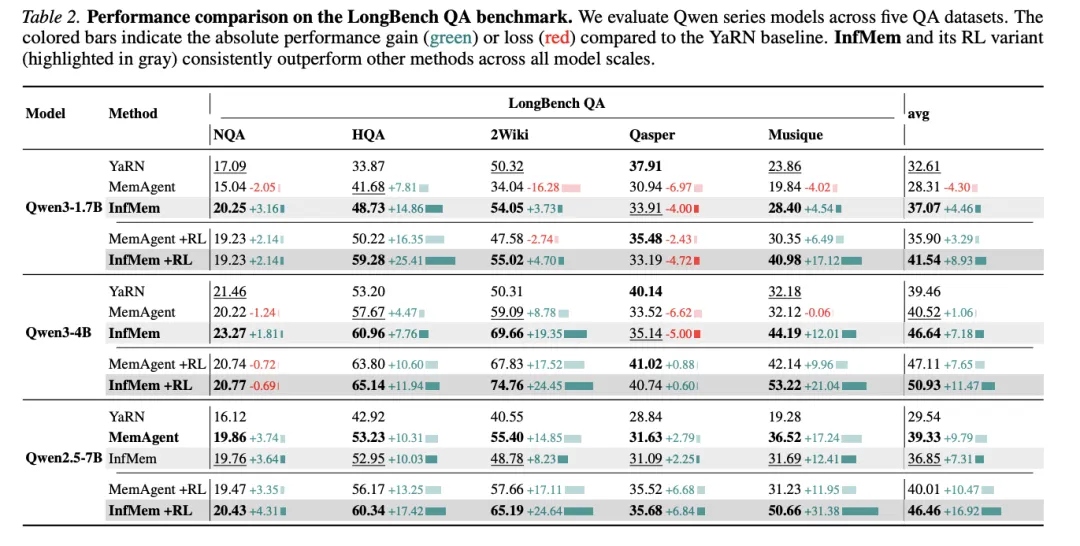
[Table 2: LongBench QA基准性能比较] 在五个QA数据集上评估Qwen系列模型。InfMem及其RL变体在所有模型规模上一致优于其他方法。
迁移到LongBench QA:性能提升不仅限于合成超长设置。在LongBench QA上,InfMem在无训练和RL增强设置下均一致优于MemAgent。结果表明InfMem不仅提高了极端长度(最高1M token)下的鲁棒性,还提升了标准长上下文QA基准上面向推理的证据管理质量。
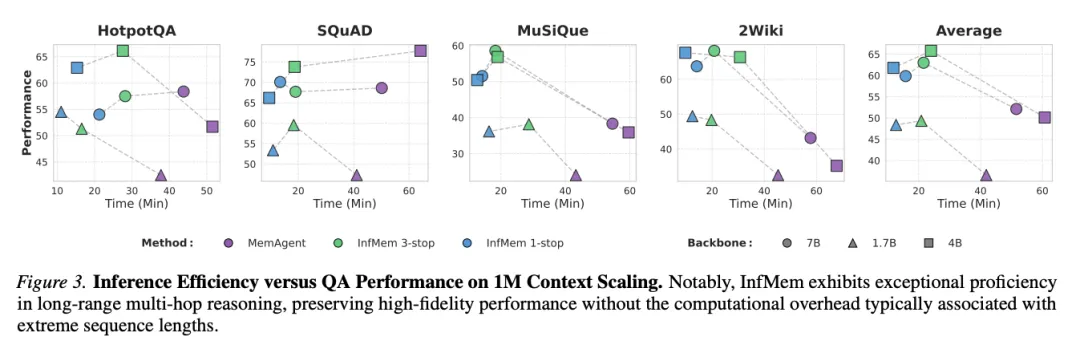
[Figure 3: 1M上下文扩展的推理效率与QA性能对比] InfMem在长程多跳推理中展现出卓越能力,保持高保真性能而无通常与极端序列长度相关的计算开销。
早停效率:早停是使循环检索可扩展的关键。在1M token任务上,InfMem在Qwen3-1.7B/4B和Qwen2.5-7B上分别提升准确率+11.80、+11.67和+7.73个百分点,同时将延迟降低5.1×、3.3×和3.3×。保守的3-stop策略进一步获得+2.76点提升,运行时间仍不到MemAgent的一半。
X写在最后
InfMem的发现揭示了一个重要趋势:随着上下文窗口扩展,主要瓶颈从原始内存容量转向认知控制——有效辨别和”知道已知什么”的能力。InfMem通过将结构化证据管理与稳健的SFT→RL训练流程相结合,在超长上下文推理中实现了System-2范式的突破。这为未来长文档理解系统的设计提供了新的方向:不仅要扩展容量,更要学会智能地管理和利用有限的认知资源。

InfMem标题:InfMem: Learning System-2 Memory Control for Long-Context Agent
InfMem链接:https://arxiv.org/abs/2602.02704
#无影寺
