 夜雨聆风
夜雨聆风





如何借助大模型高效阅读GraphRAG源码(一):突破语言障碍
用大模型作为代码理解助手,花了2-3天时间就掌握了GraphRAG的核心设计思路。相比传统阅读方式,效率提升确实明显。
写在前面
我正在研究本体(Ontology)的构建与应用。本体的核心内容来源于大量网络文件,这些文件本质上都是非结构化数据。从非结构化数据中提取结构化信息,是本体构建的关键步骤。
本体在这里扮演着重要角色:它可以作为schema约束,指导大模型从文本中准确提取实体和关系,避免提取结果的随意性和不一致性。
但这里有一个现实问题:我擅长Java,但不熟悉Python。GraphRAG是Python项目,代码风格、生态工具、设计模式都与Java世界差异较大。
这篇文章记录了我的经验——一个Java开发者如何突破语言障碍,快速理解GraphRAG的实体提取机制,为后续结合本体约束提取做准备。
为什么要读GraphRAG源码
现有方案的局限性
业界常用的RAG框架主要依赖向量匹配进行检索,这种方式存在问题:
GraphRAG的启发
微软的GraphRAG项目提供了一种新思路:通过LLM从文档中提取实体和关系,构建知识图谱,再结合向量检索进行混合查询。
在研究过程中,我参考了基于本体的GraphRAG:一种零噪声知识提取框架,这篇文章提出了本体驱动的GraphRAG框架。
但GraphRAG当前实现存在一个问题:它只使用提示词来提取特定领域的内容,没有结合本体作为约束。这意味着提取的实体类型和关系类型是开放式的,无法保证提取结果符合预定义的本体schema。
我的目标
我需要深入理解GraphRAG的源码,特别是其实体提取和关系抽取模块,分析如何将本体约束集成到提取流程中。
面临的挑战
直接阅读Python代码存在以下困难:
大模型辅助阅读的优势
面对这些挑战,大模型成为理想的辅助工具。
1. 语言转换桥梁
大模型可以实时解释Python代码的Java等价写法:
# Python代码(GraphRAG)@dataclassclass Entity: id: str name: str type: str confidence: float// Java等价写法(大模型解释)public class Entity { private String id; private String name; private String type; private double confidence; // 构造器、getter、setter...}2. 快速概念映射
将Python生态概念映射到Java生态:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3. 设计模式识别
大模型能识别代码中使用的设计模式,并用Java开发者熟悉的术语解释:
# GraphRAG中的工厂模式def create_extractor(config: ExtractorConfig) -> BaseExtractor: if config.type "llm": return LLMExtractor(config) elif config.type "rule": return RuleExtractor(config)// Java开发者熟悉的工厂模式public class ExtractorFactory { public static BaseExtractor create(ExtractorConfig config) { if (config.getType().equals("llm")) { return new LLMExtractor(config); } else if (config.getType().equals("rule")) { return new RuleExtractor(config); } throw new IllegalArgumentException("Unknown extractor type"); }}4. 上下文关联分析
大模型可以跨文件追踪调用链,理解模块间依赖关系,这对于理解GraphRAG的复杂架构至关重要。
实践步骤
步骤1:理解GraphRAG的标准工作流
在深入代码之前,先了解GraphRAG的官方文档。根据GraphRAG的构建模型数据流,默认的配置流程包括以下阶段:
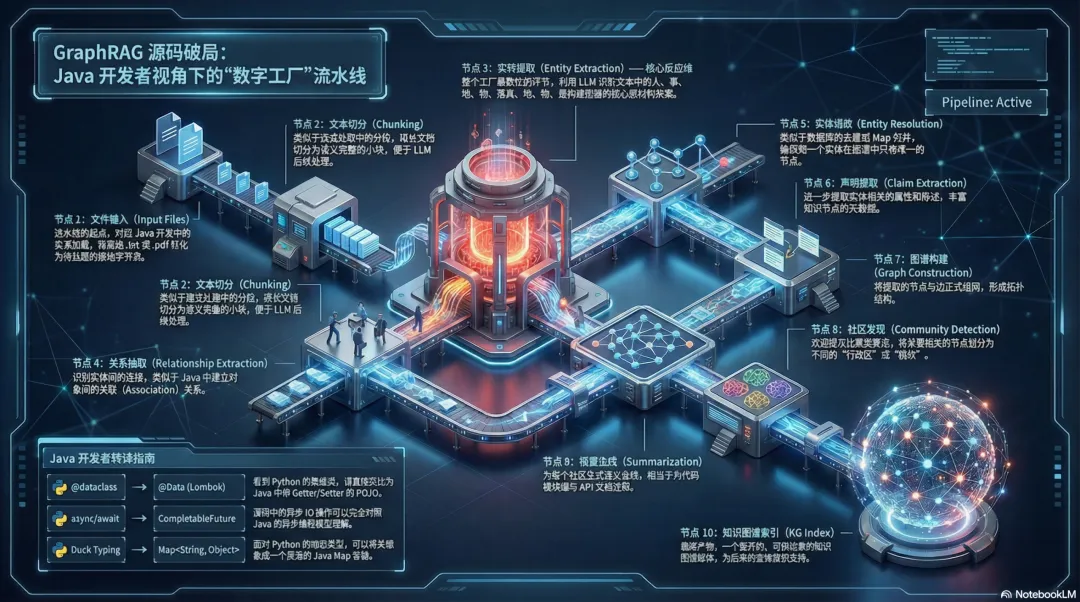
官方文档描述的数据流
第一阶段:编写文本单元
第二阶段:文件处理
第三阶段:图提取
用大模型找到代码入口
作为Java开发者,我需要找到这些工作流在代码中的具体实现。让我询问大模型:
prompt = """分析GraphRAG的代码结构,找到构建模型的工作流入口:1. 命令行入口在哪里?(类似Spring Boot的main方法)2. CLI处理层如何调用API层?(类似Controller调用Service)3. API层的核心入口是什么?(类似@Service的核心方法)4. Pipeline工厂如何创建工作流?(类似Bean工厂)5. 标准工作流的执行顺序是什么?请用Java开发者熟悉的术语解释,并给出完整的调用链路。"""大模型输出的完整调用链路如下:
工作流代码入口完整路径1. 命令行入口 (用户执行命令) 用户命令: graphrag index 代码路径: __main__.py -> 调用 CLI app main.py -> @app.command("index") 装饰器定义 _index_cli() 函数2. CLI 处理层 文件: cli/index.py index_cli() -> 加载配置 _run_index() -> 初始化日志、验证配置 调用 asyncio.run(api.build_index(...))3. API 层 (核心入口) 文件: api/index.py build_index() 函数 - 这是工作流的核心入口 初始化日志 创建回调链 通过 PipelineFactory.create_pipeline() 创建 pipeline 调用 run_pipeline() 执行4. Pipeline 工厂 文件: index/workflows/factory.py PipelineFactory.create_pipeline() - 根据配置创建工作流管道 注册的标准工作流顺序: _standard_workflows = [ "load_input_documents", # 0. 加载输入文档 "create_base_text_units", # 1. 创建文本单元 "create_final_documents", # 2. 创建最终文档 "extract_graph", # 3. 提取图 "finalize_graph", # 4. 完成图 "extract_covariates", # 5. 提取协变量 "create_communities", # 6. 创建社区 "create_final_text_units", # 7. 完成文本单元 "create_community_reports", # 8. 创建社区报告 "generate_text_embeddings", # 9. 生成文本嵌入 ]5. Pipeline 执行器 文件: index/run/run_pipeline.py run_pipeline() - 异步执行所有工作流 创建存储、缓存、表提供者 创建运行上下文 调用 _run_pipeline() 逐个执行工作流 每个工作流函数被依次调用6. 具体工作流实现 文件: index/workflows/create_base_text_units.py run_workflow() - 文本单元创建的具体实现用Java类比理解会更清晰:
用户命令: graphrag index | v__main__.py (入口,类似Spring Boot的Application类) | vcli/main.py -> _index_cli() (类似@RestController) | vcli/index.py -> index_cli() -> _run_index() (类似Service层) | vapi/index.py -> build_index() 核心API入口 (类似核心Service方法) | vworkflows/factory.py -> PipelineFactory.create_pipeline() (类似Bean工厂) | vindex/run/run_pipeline.py -> run_pipeline() -> _run_pipeline() (类似工作流引擎) | v循环执行每个工作流: |- load_input_documents (类似DocumentLoader) |- create_base_text_units 文本单元创建 (类似TextChunker) |- create_final_documents (类似DocumentBuilder) |- extract_graph (类似EntityExtractor) 关键! |- ... (其他工作流)关键入口点总结
|
|
|
|
|---|---|---|
|
|
cli/main.py
_index_cli() |
|
|
|
api/index.py
build_index() |
|
|
|
index/run/run_pipeline.py
run_pipeline() |
|
|
|
index/workflows/factory.py
PipelineFactory |
|
|
|
index/workflows/create_base_text_units.py
|
|
标准工作流顺序
_standard_workflows = [ "load_input_documents", # 0. 加载输入文档 "create_base_text_units", # 1. 创建文本单元 "create_final_documents", # 2. 创建最终文档 "extract_graph", # 3. 提取图 (最关键!) "finalize_graph", # 4. 完成图 "extract_covariates", # 5. 提取协变量 "create_communities", # 6. 创建社区 "create_final_text_units", # 7. 完成文本单元 "create_community_reports", # 8. 创建社区报告 "generate_text_embeddings", # 9. 生成文本嵌入]对于本体集成,extract_graph 工作流是最关键的,因为这是实体和关系提取的地方。
小结
通过大模型的辅助,我快速理解了GraphRAG的整体架构和工作流程。关键收获包括:
extract_graph工作流是本体集成的核心位置在下一篇文章中,我将深入分析实体提取模块的具体实现,并设计本体约束的集成方案。
参考资源
https://microsoft.github.io/graphrag/
https://github.com/microsoft/graphra
https://medium.com/@aiwithakashgoyal/beyond-simple-extraction-how-production-grade-ontologies-transform-graphrag-from-prototype-to-333742fa41a6
