文档越拆越散,评审咋办?给大模型"拆开喂、合起来审"的终极策略
“你说的拆文档、控字数,我照做了。需求拆成了四五个模块文档,设计拆成了契约、架构、详设……确实喂起来顺手多了。但问题来了—— 评审的时候怎么办? 我拆得越细,越怕模块之间藏着不一致的地方没人发现。”
做那个智能招聘助手的时候,我在”简历解析”模块的需求里写的是”输出结构化候选人档案”,结果到”智能匹配”模块的接口契约里,入参叫”candidate_profile”。听起来是一回事?不,简历解析输出的字段里有个”expected_salary”,而匹配模块的入参定义里压根没这个字段。 这个不一致是在编码阶段才暴露的。改起来牵一发动全身——需求要补、契约要改、设计要调、已经生成的代码要废掉重来。 那一刻我就意识到:拆文档只解决了”喂”的问题,还没解决”审”的问题。 拆开喂,是为了让大模型每次都吃透。合起来审,是为了让你自己心里有底。这是一体两面的事,缺了任何一面,项目迟早翻车。 为什么分散的文档天然不利于评审 上一篇文章的核心思路是”把大信息拆成小信息”。一份八千字的PRD拆成四个三千字的模块文档,每个文档自包含、边界清晰,大模型读起来不容易漏东西。 但评审干的事恰恰相反——评审要的是跨文档、跨模块的一致性检查 。 你要确认:简历解析模块说”我输出X”,智能匹配模块说”我需要X”,这两个X是不是真的一样?不光字段名一样,字段类型、是否必填、边界值定义、异常时的缺省行为,全都要对得上。 一份大文档虽然喂着费劲,但至少所有信息在同一个视野里,不一致的地方肉眼就能扫到。拆成五六份小文档之后,这种交叉比对变成了一件需要刻意去做的事。 这就是核心矛盾:喂料要拆散,评审要聚合。 两件事看似冲突,但其实可以共存——关键在于你得设计一套系统化的评审策略,而不是凭感觉随便看看。 评审的底层逻辑:三明治喂料法 不管评审哪个阶段的文档,每次交互都可以套用同一个结构。我管它叫”三明治喂料法”:
投喂包 = 锚定上下文 + 被评审文档 + 评审指令
锚定上下文 ,就是告诉大模型”你对照什么标准来审”。它不是把所有文档一股脑塞进去,而是只提供评审所需的参照物——而且通常用的是摘要版。被评审文档 ,是实际要审查的那份文件,必须完整,不能为了省字数砍内容。评审指令 ,是一段精心设计的Prompt,告诉大模型审什么、怎么打分、以什么角色的视角来看。三者加在一起,控制在六千字以内。这个总量大模型处理起来不费劲,精度也有保障。 举个具体的例子。假设你在做一个旅游行程规划Agent,现在要评审”景点推荐”模块的需求文档: 关键在那份锚定上下文:你不需要把”路线规划””酒店预订””行程分享”三个模块的需求也一起喂进去。你只需要一份精简的产品全貌摘要,让大模型知道”景点推荐”在整个系统中处于什么位置、和谁有交互就够了。 信息不是越多越好。无关信息对大模型来说是噪音,噪音会拉低评审精度。 评审什么时候做:阶段完成即评审 原因很简单:需求阶段发现的问题,修一修措辞就行。等到了编码阶段再发现需求有漏洞,你改的就不是一份文档了,而是从需求到设计到代码的一整条链路。
阶段完成 → 本阶段评审 → 打分 → 达标进入下一阶段 → 不达标修复后重审
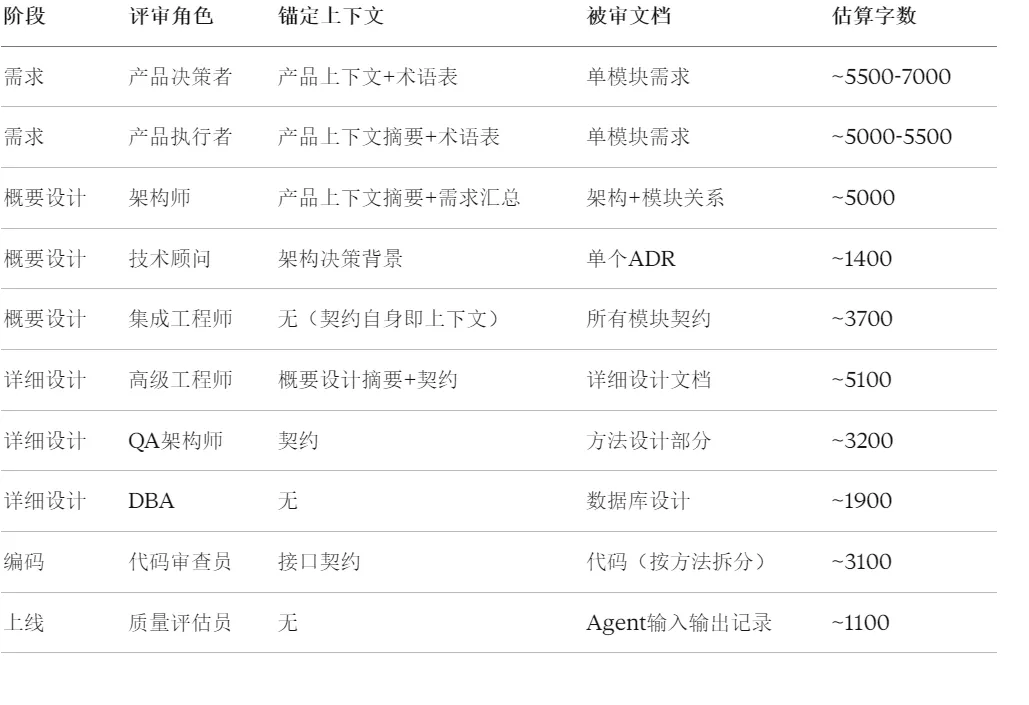
每个阶段结束后立即评审。评审发现的问题在当前阶段修复,成本最低。 而且重审的时候不需要重头来过——只审修复的部分就行。喂料包非常轻量:上次发现的问题清单(三百字)+ 修改后的内容(五百到一千字)+ 一句话指令”请确认这些修改是否解决了之前的问题”。总计不到两千字,审起来又快又准。 各阶段评审的具体操作 下面按阶段拆开讲。每个阶段我都会说清楚:评审目标是什么、用什么角色来审、锚定上下文带哪些文件、大概多少字数。 需求阶段:逐模块评审,术语表常驻 需求阶段的文件散在好几个目录里——产品上下文、各模块需求、业务规则、术语表。评审目标是确认需求文档完备、可执行、对大模型友好。 这一轮不看细节,看骨架。功能和产品目标对得上吗?模块拆分合理吗?有没有遗漏或重叠? 锚定上下文用产品上下文全文加术语表,被审文档是某一个模块的需求规格。总计七千字左右,如果超了,就把产品上下文压缩成一千字的摘要版。 这一轮逐条深挖。用户场景覆盖了正常流程和异常流程吗?业务规则能直接转成代码吗?输入输出说明够不够让下游模块(以及大模型)明确知道”我能拿到什么”? 一是术语表每次必带 。这份文件通常只有几百字到一千多字,占不了多少空间,但能让大模型在评审时顺手检查术语一致性。比如你的旅游Agent里,”景点”和”目的地”是一回事还是两回事?”行程”和”路线”有没有被混用?术语表就是那把尺子。 二是每个模块开一个新对话来评审 。生成文档和评审文档不要在同一个对话里——大模型会有”惯性”,它在同一个对话里生成的东西,自己审的时候很难客观。换个对话就像换了一个人,苛刻程度明显不一样。 概要设计阶段:分三步走 概要设计的文件更散——架构文档、技术决策记录(ADR)、各模块的API契约、事件契约。评审目标是确认模块划分合理、接口契约完备、技术决策有据。 锚定上下文用产品上下文摘要加需求阶段各模块的一句话定位汇总(这个需要提前自己整理,大概五百字),被审文档是架构文档加模块关系图。总计五千字左右。 以架构师的视角来审:架构选型有没有过度设计?模块间通信方式选得合理吗?未来加新模块能不能平滑接入? 比如你做旅游行程Agent,选了微服务架构——但整个系统其实就四个模块,日活预估一千人。这个体量用微服务,是不是杀鸡用了牛刀?这种问题在架构评审里就该被揪出来。 技术决策记录(ADR)通常很短,每条五百字左右。锚定上下文只需要从架构文档里摘出相关段落(五百字),加上评审指令,总计一千多字。审得快,但很有价值——因为ADR记录的是”为什么选这个方案而不是那个”,这些决策理由如果站不住脚,后面全得返工。 前面两步都是看单个文档,这一步是真正需要”合起来审”的环节——把多个模块的接口契约一起喂给大模型,让它像一个集成工程师一样去检查:A模块的输出和B模块的输入对得上吗?字段名一致吗?类型一致吗?错误码体系统一吗? 如果模块不多(三四个),所有契约加在一起大概三千到四千字,一次性喂进去没问题。 方案一:两两审查。 只审上下游直接对接的模块对。景点推荐的输出和路线规划的输入对得上吗?路线规划的输出和酒店预订的输入对得上吗?一对一对地审,最后再跑一轮全局数据流检查(只喂每个契约的入参出参摘要,不带详细字段定义)。方案二:分层审查。 第一轮只审字段名和类型一致性(每个契约只提取字段列表,两百字左右);第二轮只审交互方式(同步还是异步、推还是拉)一致性;第三轮只审错误码覆盖一致性。每轮都很轻量,但三轮下来该查的都查到了。详细设计阶段:逐模块、多角色 详细设计文档通常比较长,里面包含数据模型、核心逻辑、异常处理方案。评审目标是确认”拿着这份文档能直接写代码”,且异常路径无遗漏。 锚定上下文用该模块的概要设计摘要加接口契约(各八百字左右),被审文档是详细设计全文。总计五千字左右。 审的重点:算法描述够不够具体?边界条件怎么处理?依赖服务挂了怎么降级? 这个角色不看全文,只看详细设计中的方法设计部分(大概两千字),锚定上下文只需要接口契约作为”应该怎样”的参照。总计三千字左右。 审的重点:每个流程节点都想想”如果这步出错了呢?”。网络超时?数据格式不对?并发冲突?输入是空的?输入是恶意构造的? 这个角色的价值在于:它和写设计的那个”你”(或者那个大模型对话)不是同一个思路。写设计的时候你想的是”怎么做成”,这个角色想的是”怎么能搞砸”。两种思路碰撞,才能把漏洞补上。 如果模块有复杂的数据存储需求,单独审一轮数据库设计。通常字数不多,两千字以内就够。审的重点:表结构满足查询需求吗?有没有冗余字段或缺失字段?索引设计合理吗? 编码阶段:让更强的模型来审 编码评审有个特殊之处——让生成代码的那个大模型自己审自己,效果不好。就像你自己写的文章自己校对,错别字永远看不出来。 比如你用 Sonnet 生成代码(性价比高),就用 Opus 来做代码审查(推理能力更强)。锚定上下文是接口契约,被审文档是生成的代码(按方法拆分,每次审一个方法),总计三千字左右。 审什么?三件事:代码和契约对得上吗?异常处理覆盖了吗?有没有安全隐患? 尤其要注意大模型的一个”坏习惯”——它喜欢”擅自优化”。你的契约里字段叫 job_id,它生成的代码里可能悄悄改成了 jobId。你的契约要求返回错误码 E2001,它可能自作主张用了 HTTP 状态码。这些”小聪明”在单元测试里不一定能抓到,但在集成时会让你抓狂。 上线前阶段:让便宜的模型评判贵模型 Agent项目的上线评审和传统软件不一样。传统软件上线前跑通测试用例就行,Agent还需要验证”它的行为像不像话”。 第一层:规则校验。 这层不需要大模型,用脚本就行。匹配度分数是不是在0-100之间?推荐理由是不是不超过100字?输出的JSON格式对不对?这些硬性规则自动化检查。第二层:语义评估。 用一个便宜的模型来评判另一个模型的输出质量。比如你的招聘Agent用 Opus 生成了一条匹配推荐理由,你把”岗位要求+候选人简历摘要+Agent的输出”打成一个包(总共一千字左右),喂给 Haiku,让它评判这条推荐理由是否准确、有没有事实错误、有没有偏见。每条评估不到一分钱,可以批量跑。跑个一百条,统计通过率,就知道Agent的输出质量大致在什么水位。 第三层:基线对比。 准备二十条”标准答案”(比如由资深HR标注的匹配结果),每次有Prompt变更或策略调整之后,跑一轮回归,看Agent的输出和标准答案的一致率有没有下降。让评审结论跨阶段传递 到这里,每个阶段怎么审已经讲清楚了。但还有一个容易被忽略的问题:阶段和阶段之间的评审结论怎么衔接? 如果需求阶段的评审发现了一个问题并修复了,到了概要设计评审的时候,大模型并不知道这件事。它不知道”上游已经确认了什么”,自然也没法检查”下游有没有违背上游的结论”。 每次评审完成后,把结论压缩成一段摘要(两百到三百字),存到一个固定的目录里。下一阶段评审时,把上游的评审摘要作为锚定上下文的一部分带进去。
需求评审摘要 → 带入概要设计评审的锚定上下文 概要设计评审摘要 → 带入详细设计评审的锚定上下文
这段摘要不长,但信息密度很高。它告诉大模型:”上游评审已经确认了这些结论,请在审查下游文档时检查是否与之一致。” 这样一来,虽然每次评审的对话是独立的,但评审链把各阶段的质量检查串了起来。不会出现”需求评审改了边界条件,详细设计里还是老版本”这种断裂。 几个提高评审精度的实用技巧 准备”常驻文件”的两个版本 有几份文件在多个评审环节都会用到:产品上下文、术语表、各模块接口契约。我建议每份都准备两个版本——完整版和摘要版。根据当次评审的剩余字数空间,灵活选用。 比如产品上下文完整版两千五百字,摘要版一千字。如果这次被审文档比较短,锚定上下文可以用完整版,信息更充分;如果被审文档已经三千多字了,就切换到摘要版,给评审指令留足空间。 术语表通常不需要精简——本身就一千多字,而且每个评审环节都用得上。 评分卡强制量化 大模型做评审有一个通病:它太”善良”了。你让它审一份文档,它恨不得给你全五分,然后说几句”总体质量不错,可以考虑进一步优化以下几点……” 解决办法是在评审指令里加评分卡,而且要加一条硬约束:
请扮演一个严格的评审者,至少指出3个可改进的地方。如果你认为某项确实是5分,请说明为什么不是4分。
评分卡的设计因阶段而异,但结构是统一的:每个维度1-5分,带权重,设定达标线和阻断线。
评分维度及权重: - 场景完备性(×2):主路径+至少3条异常路径 = 5分 - 规则可执行性(×1):所有规则可直接写代码 = 5分 - 边界清晰度(×1):"做什么""不做什么"均明确 = 5分 - 术语一致性(×1):全文统一 = 5分 - 大模型友好度(×1):直接投喂可用 = 5分 满分30分,达标≥24分,<18分阻断。
有了这张卡,大模型给出的评审结论就是可度量、可对比的。这次评审24分,修了两个问题重审后变成27分——进步是看得见的。 评审结论和自己的判断冲突时怎么办 大模型评审是”第二双眼睛”,不是最终裁判。尤其是涉及业务语义的判断,你比大模型更懂你自己的业务。 但也别完全忽略它的意见。如果大模型反复在某个点上给出负面评价,哪怕你觉得没问题,也值得停下来想一想——也许不是它错了,而是你的文档在那个点上表述不够清晰,导致它(以及未来读这份文档的人或其他大模型)容易误解。 一份完整的评审速查表 锚定上下文是不是精简到了必要最小?多余的信息只会添乱。 被审文档是不是完整的?不要为了控制总字数去砍被审文档。 评分卡写进Prompt了吗?让大模型给出量化结论,而不是泛泛而谈。 是不是在新对话里评审?生成和评审分开,避免上下文污染。 哪些评审可以精简,哪些绝对不能省 现实情况是,不是每个项目都有充裕的时间把所有评审跑满。如果时间紧张,可以灵活调整评审深度——但有一条底线不能破。 简单模块可以只跑一个角色的评审。 比如一个纯CRUD的数据管理模块,需求简单、逻辑直白,一轮快速评审就够了。复杂模块必须跑满两个以上角色。 特别是涉及大模型推理、多模块交互、业务规则复杂的核心模块。招聘Agent里的”智能匹配”、旅游Agent里的”行程规划”,这些模块不多花点时间评审,后面一定后悔。契约交叉审查绝对不能跳过。 这是整个评审体系中性价比最高的一环。如果你全流程只能做一次评审,就做这个。因为契约是模块间协作的”法律文书”,它不一致,集成时必然翻车,而翻车成本远高于评审成本。写在最后 回头看,上一篇文章解决的是”怎么和大模型高效协作”的问题——拆文档、控字数、分轮喂料。这篇解决的是”怎么确保协作质量不失控”的问题——分角色评审、三明治喂料、评审链传递。 拆开喂,让大模型每次都吃透。合起来审,让你自己每次都放心。 这套策略不复杂,但需要从项目一开始就养成习惯。就像写代码要跑测试一样——你不会写完所有代码再一起测,而是写一段测一段。评审也是同理,写完一个阶段就审一个阶段,小步快走,问题早发现早修复。 如果你正在用上一篇文章的方法做Agent项目,这篇文章的评审策略可以直接叠加上去。两篇一起用,效果更好。 有什么问题或者你自己摸索出的评审技巧,欢迎留言交流。
 夜雨聆风
夜雨聆风