 夜雨聆风
夜雨聆风





RAG技术深度解析(二):文档分块与向量化技术详解
在上一篇文章中,我们了解了RAG的基本概念和系统架构。本篇将深入离线阶段的两大核心技术——文档分块和向量化,它们决定了RAG系统检索质量的上限。

一、文档分块(Chunking):构建可检索的知识单元
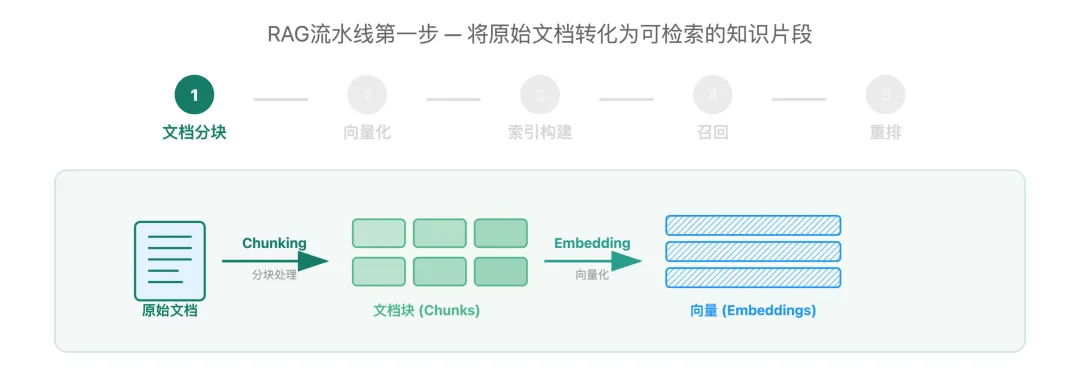
在第一篇中我们提到,RAG的离线阶段需要将原始文档转换为可检索的向量表示。而这一切的起点,就是文档分块。
为什么分块很重要?
文档分块的核心目标:生成既能独立表达语义、又适配向量化处理的知识单元,为后续精准检索奠定基础。
分块质量直接决定了检索效果。一个好的分块需要满足四个核心要求:
-
语义完整性– 每个块能独立表达完整概念
-
长度适配– 适配Embedding模型的输入限制(通常200-1000 tokens)
-
上下文连贯– 保持文本的逻辑关联性
-
检索友好– 优化向量检索的准确性
五大分块策略详解
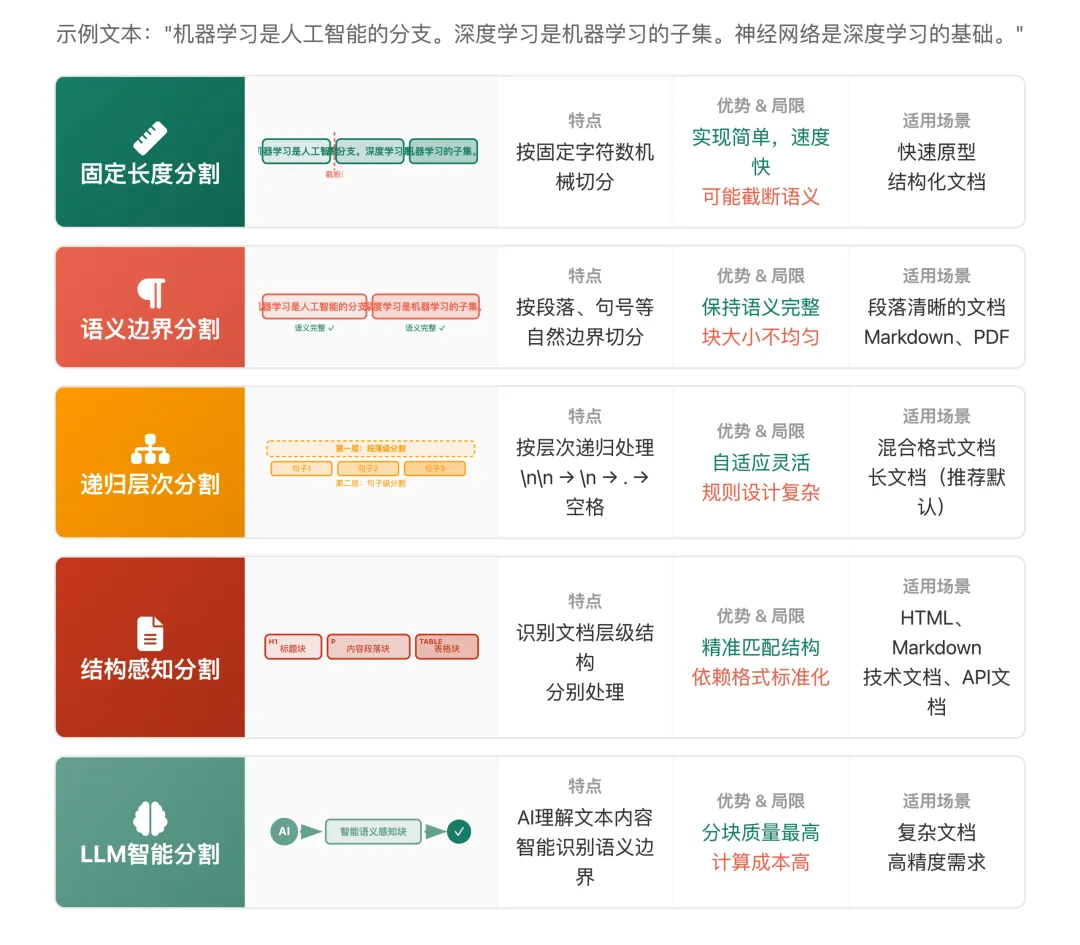
我们以一段示例文本来说明不同策略的效果:
原始文档: “机器学习是人工智能的分支。深度学习是机器学习的子集。神经网络是深度学习的基础。”
策略一:固定长度分割(Fixed-Size Chunking)
原理:
按固定字符数或token数机械切分,不考虑文本内容。这是最简单直接的分块方式——设定一个数字,到了就切。
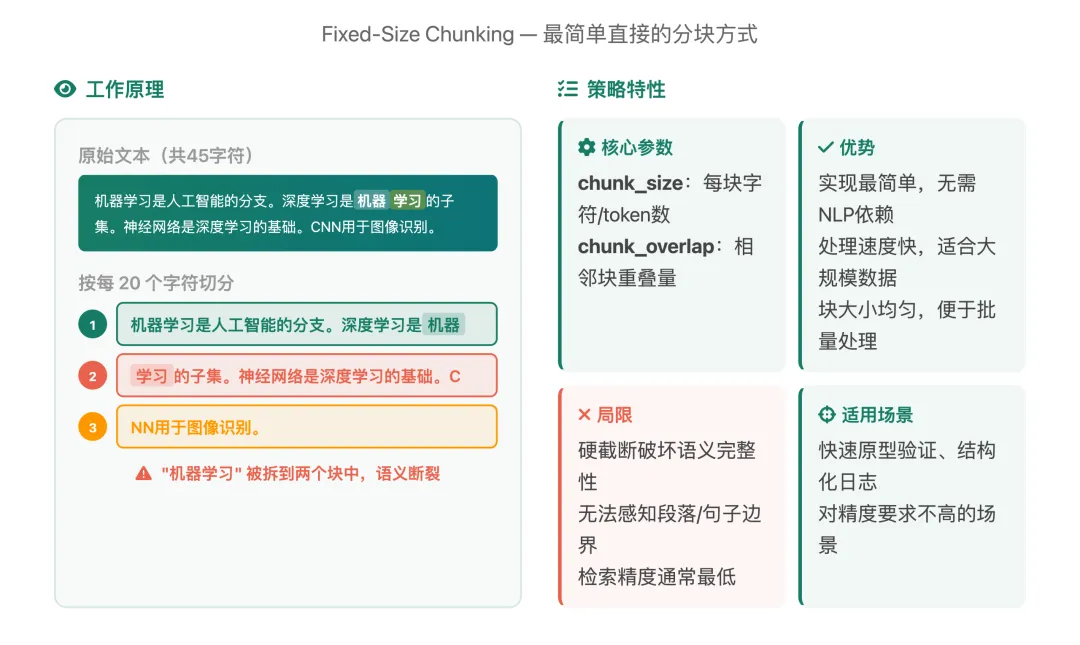
注意看:“机器学习”这个完整的词被硬生生拆到了两个块中——块1以”机器”结尾,块2以”学习”开头。这就是固定长度分割最大的问题:它完全不理解文本内容,到了字数就切。
一句话总结: 速度最快、精度最低,适合快速验证原型,不推荐生产环境直接使用。
策略二:语义边界分割(Sentence/Paragraph Splitting)
原理:按自然语言边界切分——识别句号、问号、换行等标记,在这些位置分割,确保每个块都是一个完整的语义单元。

和固定长度分割对比,差异一目了然:每个块都是一句完整的话,没有任何词汇被截断。
一句话总结: 最常用的基础策略,简单有效,适合绝大多数结构清晰的文档。
策略三:递归层次分割(Recursive Character Splitting)
原理:按层次递归处理——先尝试按段落分割,如果块还是太大,再按换行分,还太大就按句子分……逐层细化,直到满足块大小要求。这是LangChain 默认推荐的策略。

递归的核心思想是尽量保持更大粒度的语义单元。只有当上层分割结果太大时,才会降级到更细的粒度。
一句话总结: 最均衡的策略,不知道选什么就选它。
策略四:结构感知分割(Structure-Aware Splitting)
原理:
识别文档的层级结构(标题、正文、表格、代码块),按结构类型分别处理。它不是在”切文本”,而是在”解析文档结构”。

结果:标题+内容形成完整章节块,表格作为独立块保持结构完整,不会出现表格被从中间截断的情况。
一句话总结: 结构化文档的最佳选择,效果精准,但需要文档本身格式规范。
策略五:LLM智能分割(Semantic Chunking with LLM)
原理:利用大语言模型或 Embedding 模型理解文本内容,智能识别语义边界。它不依赖任何规则或标记,而是让 AI真正”读懂”文本,在主题转换的位置自动切分。

两种主要实现方式:
Embedding 相似度方法:计算相邻句子的语义向量相似度,当相似度骤降时说明话题发生了转换,在该位置切分
LLM 提示词方法:直接让大模型阅读文本并标注最佳分割点
一句话总结: 分块质量天花板,但成本也是天花板。适合小规模、高价值的精准场景。
分块策略对比总结
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
重叠策略(Overlap)的作用
仅仅把文档切分成块还不够。当我们在两个块的边界处切割时,边界附近的上下文信息就丢失了。
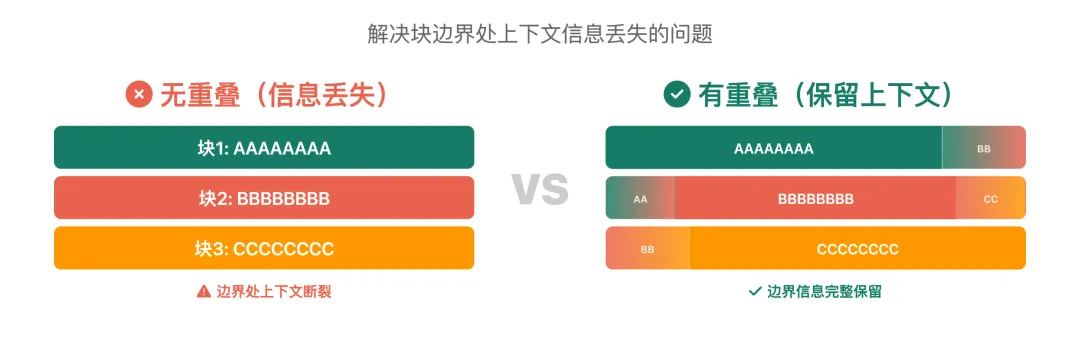
重叠的好处:
-
保留了块边界处的上下文信息 -
确保跨块的关键信息不会丢失 -
提升检索时对边界内容的召回率
重叠长度建议:通常为块长度的10%-20%。过多的重叠会增加冗余和存储成本,过少则达不到效果。
不同文档类型的最佳实践
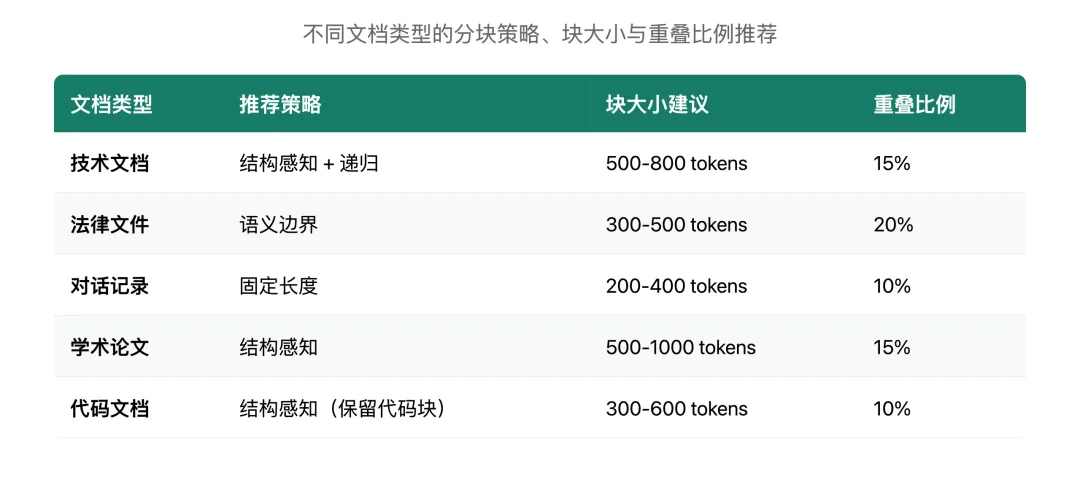
💡 实战建议: 先用递归层次分割作为基线,再根据文档特点调整。没有万能策略,A/B测试是验证效果的最佳方式。
二、Embedding向量化:语义的数学映射
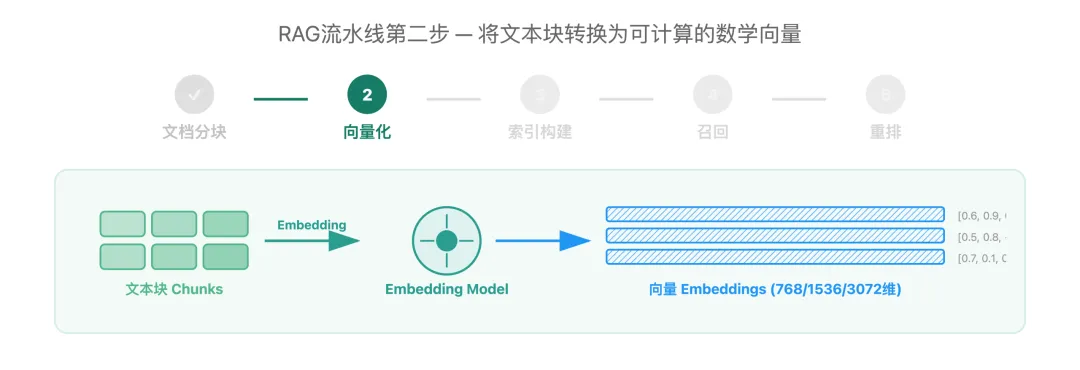
完成文档分块后,下一步就是将文本块转换为计算机能”理解”的数学表示——这就是Embedding向量化。
什么是Embedding?
Embedding是将文本转换为数学向量的技术。计算机原本只能处理数字,通过Embedding,我们把每个词、每句话都变成了一串数字(通常是768维或1536维的向量),计算机就能比较哪些文本意思相近、哪些不相关。
简单比喻:文字的”身份证号码”
就像每个人都有身份证号码一样,Embedding给每个词汇都分配了一个”数字身份证”。但这个身份证很特别:
意思相近的词,身份证号码也相近— 例如:”猫”和”小猫”的向量很相似
意思不同的词,身份证号码差得很远— 例如:”猫”和”房子”的向量差别很大
有关系的词,身份证之间有规律— 例如:”国王-男人+女人≈女王”
Embedding的工作原理
核心原理:物以类聚,人以群分。
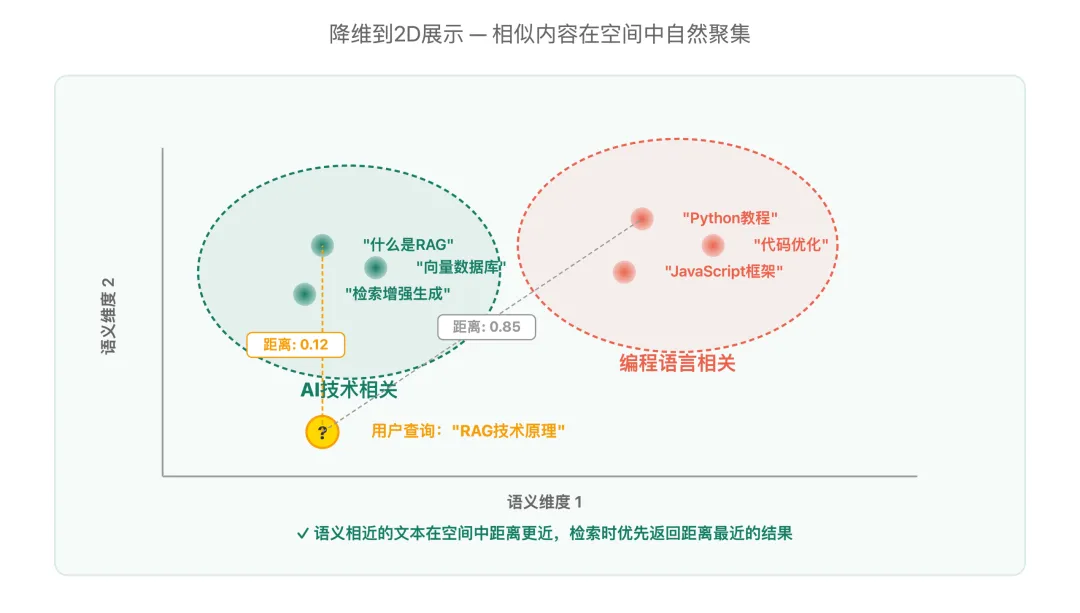
如果两个词经常在相似的上下文中出现,那它们的意思很可能相近。AI模型通过分析千万篇文章,发现了词汇出现的模式,然后给每个词分配一个合适的向量,让意思相近的词在”数字空间”里也靠得更近。
直观理解:词汇的向量表示
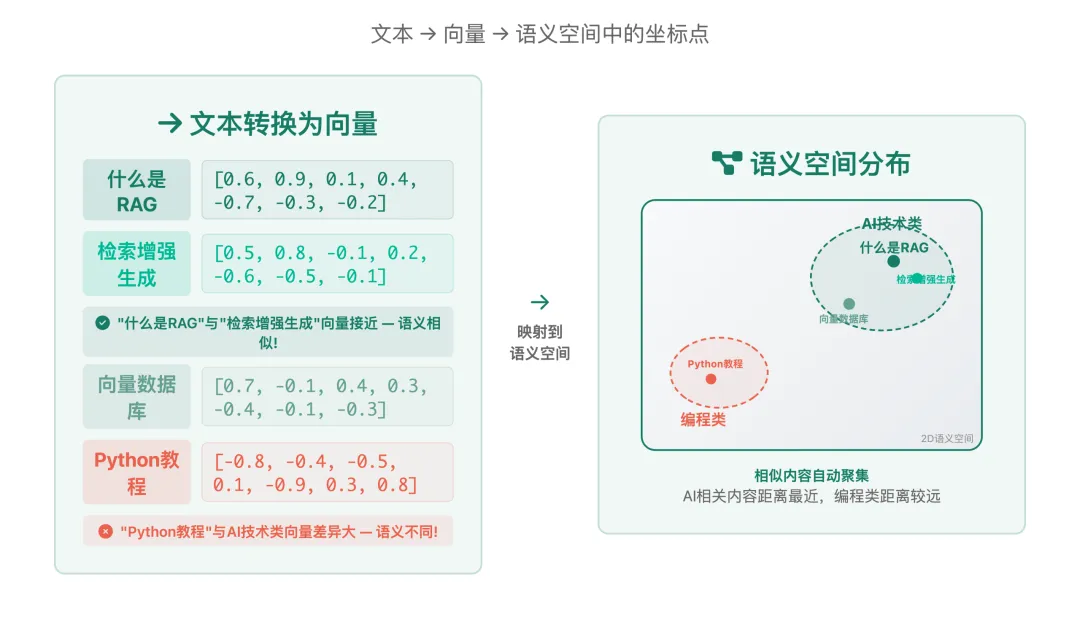
为什么RAG用Embedding?
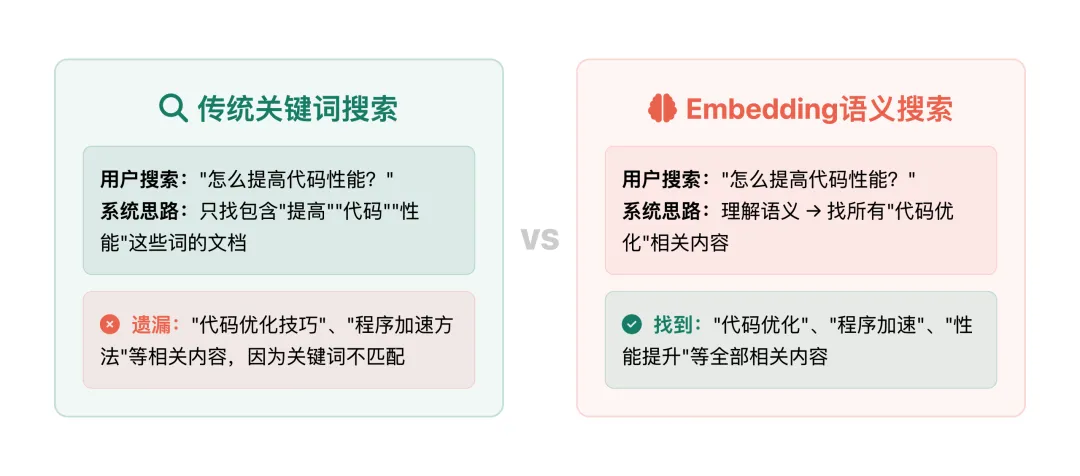
传统的关键词搜索只能做字面匹配。比如你搜”怎么提高代码性能”,系统只找包含”提高””代码””性能”这些词的文档,而”代码优化技巧””程序加速方法”这些语义相同但用词不同的内容就被遗漏了。
Embedding语义搜索则不同:它理解”提高代码性能”和”程序优化”表达的是同一个意思,即使用词完全不同,也能找到相关内容。
Embedding在RAG中的四大价值:

✅理解同义词– “天气不错”和”天空晴朗”意思相同,向量也相近
✅支持数学运算– 可以计算相似度、做聚类,实现精确的语义比较
✅检索速度快– 向量计算比文本匹配快很多,秒级搜索百万文档
✅跨语言理解– “Hello”和”你好”,不同语言,相同含义
主流Embedding模型全景对比

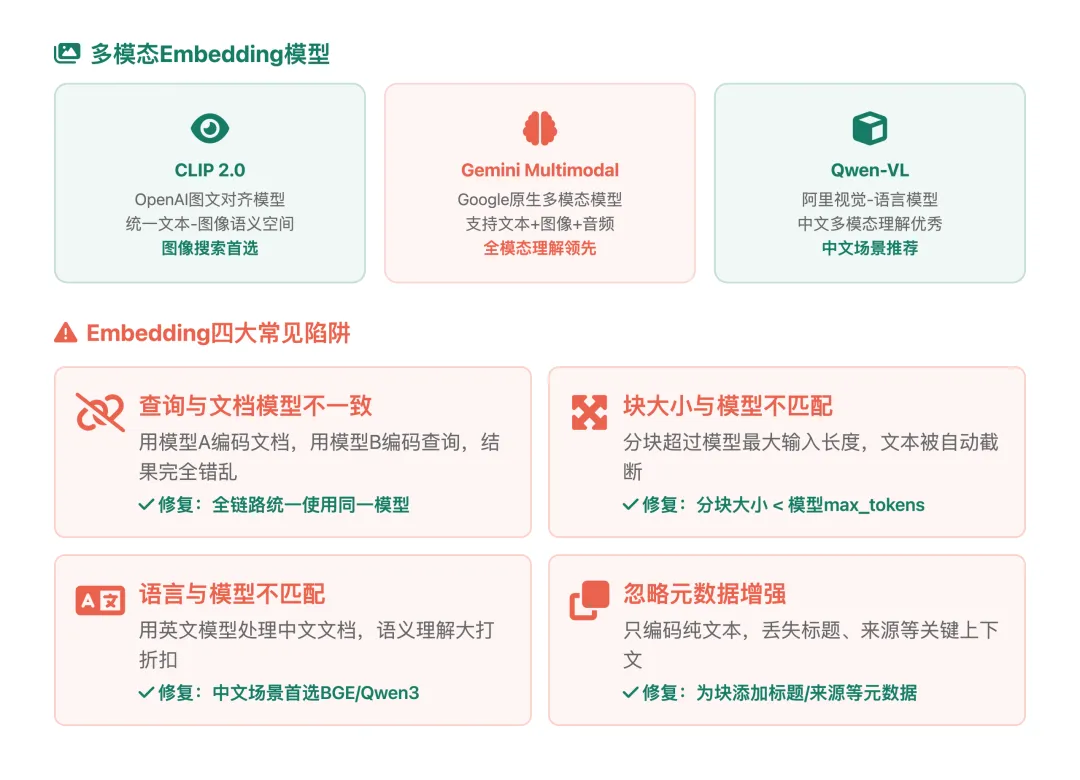
多模态Embedding模型
Embedding模型选型指南
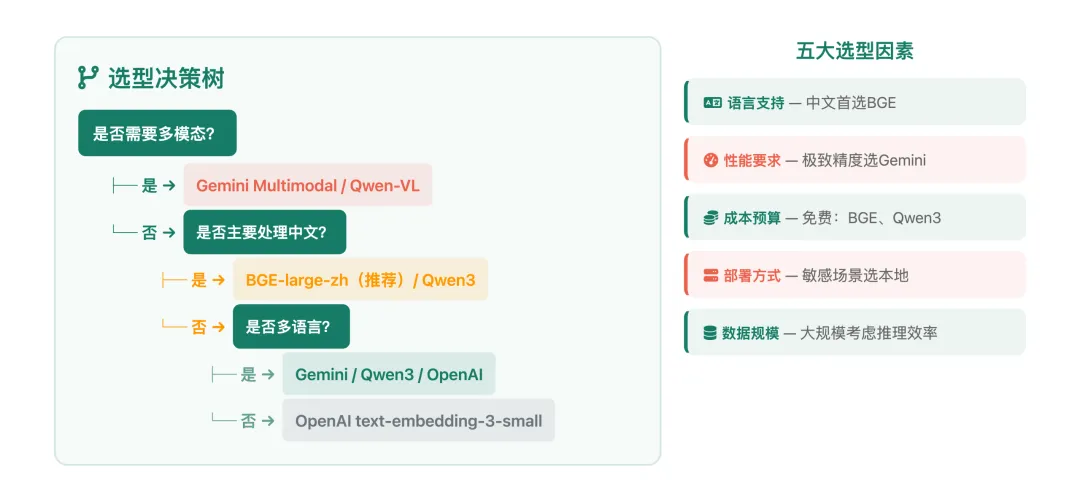
面对这么多模型,如何选择?按以下决策树思考:
向量化最佳实践
实践一:如何评估Embedding质量
选好了模型,怎么验证效果?三步评估法:
语义相似度测试– 准备一批已知语义关系的文本对,计算余弦相似度,验证”相似的分数高、不相似的分数低”
检索准确率评估– 用真实查询测试,检查Top-5召回结果中有多少是相关的
可视化分析– 用t-SNE/UMAP降维,观察向量空间中的聚类分布是否合理
实践二:领域微调技巧
通用Embedding模型在垂直领域(如医疗、法律、金融)效果可能不够理想。此时可以考虑微调。
何时需要微调?
-
领域术语频繁出现,通用模型理解不准确 -
检索准确率低于80% -
存在大量行业特有的同义词和缩写
微调方法(对比学习):
准备领域数据:正样本对(语义相似的文本对)+ 负样本对(不相似的文本对)
在通用模型基础上继续训练
优化目标:让正样本对的向量更近,负样本对更远
通常几千到几万条训练数据即可获得明显提升
实践三:常见陷阱与注意事项
❌陷阱1:查询和文档使用不同的Embedding模型
这是最常见的错误。查询和文档必须使用同一个Embedding模型编码,否则它们不在同一个语义空间中,检索结果毫无意义。
❌陷阱2:向量维度选择不当
维度越高不一定越好。3072维的模型在小数据集上可能过拟合,而768维在大多数场景下已经够用。选择支持维度截断(如Matryoshka)的模型可以灵活调整。
❌陷阱3:忽略归一化处理
部分Embedding模型的输出向量未归一化。在使用余弦相似度时,需要先对向量做L2归一化,否则会影响检索精度。
❌陷阱4:批量处理的内存溢出
对大量文本做Embedding时,一次性加载太多数据会导致OOM(内存溢出)。建议分批处理(batch_size=32-128),尤其在GPU资源有限的情况下。
✅解决方案清单:
-
统一使用同一个Embedding模型 -
根据数据规模选择合适的维度 -
检查模型文档确认是否需要归一化 -
使用批量处理 + 流式写入策略 -
定期评估Embedding质量,及时发现退化
三、分块与向量化的协同优化
分块和向量化不是独立的两个步骤,它们需要协同配合。

关键原则
1. 块大小与Embedding模型匹配
每个Embedding模型都有最大输入长度限制。如果块太长超过限制,会被截断导致信息丢失:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2. 短块与长块的取舍
短块(200-400 tokens):语义聚焦,检索精准度高,但可能丢失上下文
长块(600-1000 tokens):上下文丰富,但语义可能不够聚焦,检索噪声大
推荐:从500 tokens开始,根据评估结果调整
3. 元数据增强
在向量化时,可以将元数据(文档标题、章节名、来源等)附加到文本块中,帮助Embedding模型更好地理解上下文:
原始块: "工作满1年:5天年假"增强后: "[员工手册-第五章-年假政策] 工作满1年:5天年假"
这样即使块内容很短,Embedding也能理解这段文本的上下文。
总结与下期预告
通过本文,我们深入了解了RAG系统离线阶段的两大核心技术。
文档分块的关键要点:
◉选择合适的分块策略– 根据文档类型选择,递归层次分割是优秀的默认选择
◉善用重叠机制– 10%-20%的重叠比例保留边界上下文
◉块大小适配模型– 确保不超过Embedding模型的输入限制
向量化的关键要点:
◉模型选型要匹配场景– 中文选BGE,多语言选Gemini/Qwen3
◉查询与文档必须同模型– 最基本也最重要的原则
◉关注质量评估与微调– 通用模型不够时,少量数据微调即可显著提升
系列文章预告
► 第三篇:向量数据库与索引优化
-
HNSW、IVF、PQ等索引算法深度解析 -
Milvus、Pinecone、Qdrant等数据库选型指南 -
从500ms优化到50ms的性能调优实战
► 第四篇:召回与重排技术进阶
-
多路召回策略设计(向量+全文+图谱) -
Cross-Encoder重排模型原理与应用 -
混合检索的融合策略详解
► 第五篇:技术对比、应用场景与最佳实践
-
RAG vs Fine-tuning vs Prompt Engineering -
六大典型应用场景深度分析 -
生产级RAG系统的完整最佳实践
分块决定检索的粒度,向量化决定检索的精度。两者协同,才能构建高质量的RAG知识库。
关于本系列: 《RAG技术深度解析》系列致力于系统性、实战性地讲解RAG技术。无论你是AI从业者、技术管理者,还是对AI技术感兴趣的开发者,都能从中获益。
如果这篇文章对你有帮助,欢迎点赞、在看和转发,也欢迎在评论区分享你的实践经验和遇到的问题。我们下期见!
