 夜雨聆风
夜雨聆风





你是说,我扔给AI一个文档,它就自动能学一项新Skill?
“我花了 3 天清洗数据,结果只写了 2 小时 RAG 逻辑。” —— 如果这句话戳中了你,今天这篇文章值得你读完。
一、那个被所有 AI 开发者忽略的”脏活累活”
2026 年了,人人都在聊 Agent、RAG、MCP。
但有一个残酷的事实没人愿意提:搭建一个 RAG 系统,70% 的时间不是在写检索逻辑,而是在做数据预处理。
抓文档、清洗 HTML、提取代码块、切分 chunk、补充元数据、处理 PDF 表格、解析 GitHub Issues……
这些活儿没有任何技术含量,但每次都要从头来一遍。
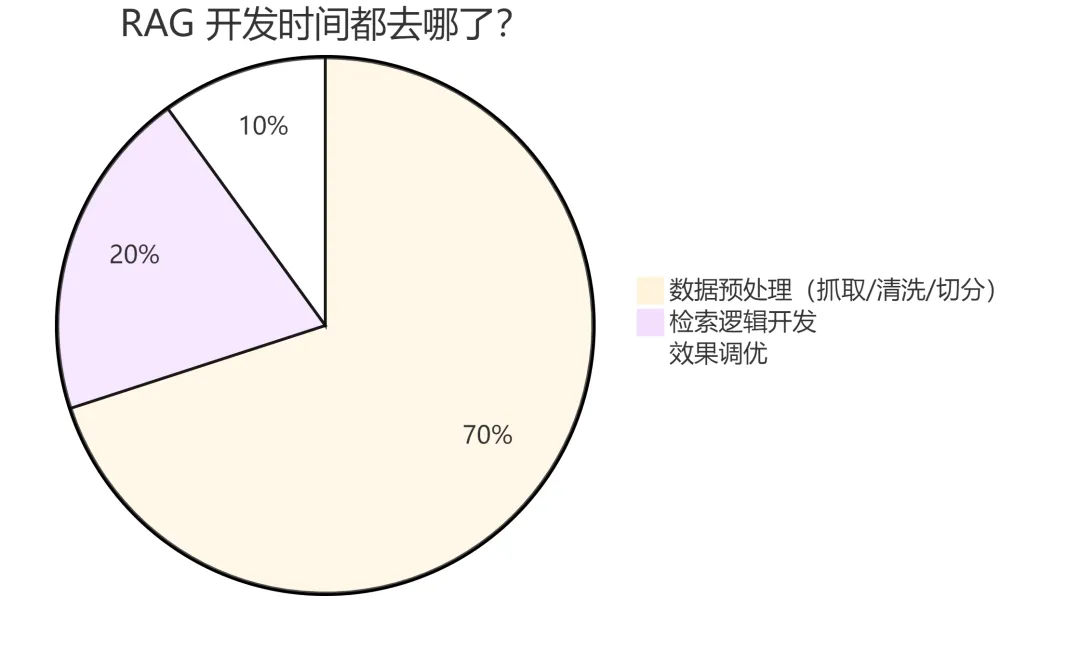
有没有一种可能——把这 70% 的时间压缩到 15 分钟?
今天介绍的这个项目,就是干这件事的。
二、Skill Seekers:AI 系统的「万能数据预处理层」

Skill Seekers —— GitHub 9.4k Star,一个将任意知识源(文档网站 / GitHub 仓库 / PDF)自动转换为 16 种 AI 平台可用格式的开源工具。
一句话概括:你给它一个文档 URL,它还你一个随时可用的 AI 技能包。




|
|
|
|---|---|
|
|
9,400+ |
|
|
946 |
|
|
33 人 |
|
|
1,200+ |
|
|
25 个 |
|
|
16 种平台 |
|
|
24 个框架 |
三、它到底解决了什么痛点?
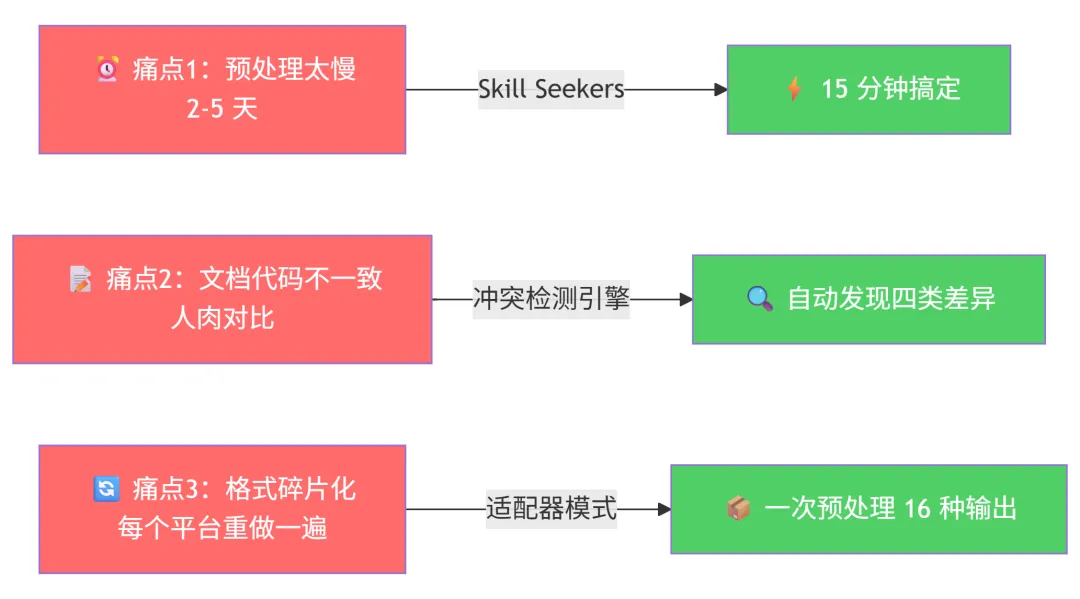
痛点 1:做一个 RAG 系统,光数据预处理就要好几天
传统流程:

⏰ 时间成本:2-5 天,还可能循环返工
用 Skill Seekers:
pip install skill-seekers
skill-seekers scrape --config configs/react.json # 15分钟,自动抓取
skill-seekers package output/react --target langchain # 秒级打包
⚡ 时间成本:15 分钟,线性流程不返工
⚡ 99% 的时间节省,不是夸张,是实测。
痛点 2:文档和代码”两张皮” —— 你以为的 API 和实际的 API 不一样
这可能是 RAG 系统最隐蔽的 bug 来源:文档写的参数签名和代码里的实现不一致。
Skill Seekers 独创的 「冲突检测」 功能直击这个问题。它同时抓取文档和 GitHub 源码,自动对比差异:
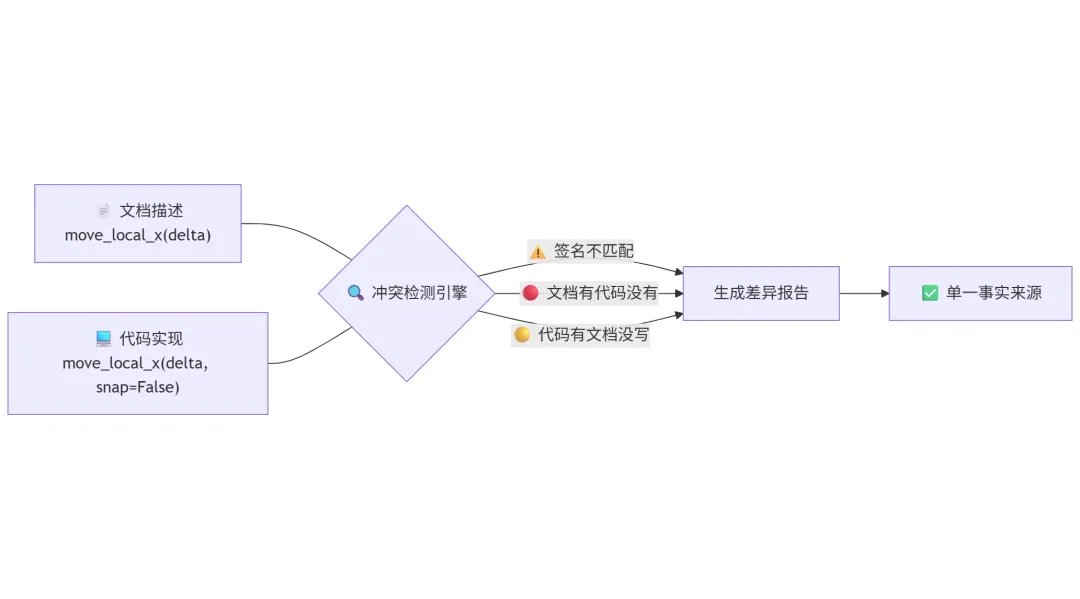
#### `move_local_x(delta: float)`
⚠️ **冲突**: 文档签名与实现不一致
📄 文档说:
def move_local_x(delta: float)
💻 代码实际上是:
def move_local_x(delta: float, snap: bool = False) -> None
四种差异自动检测:
-
🔴 文档有但代码没有(可能已删除) -
🟡 代码有但文档没写(可能是新功能) -
⚠️ 签名不匹配(参数/类型不同) -
ℹ️ 描述不一致(解释有出入)
你的 RAG 系统吃进去的数据就是「单一事实来源」,而不是”薛定谔的文档”。
痛点 3:每换一个 AI 平台,数据格式就要重做一遍
今天用 LangChain,明天要切 LlamaIndex,后天老板说试试 Pinecone……
每个平台的数据格式都不一样。一份数据,反复适配,心态崩了。
Skill Seekers 用 适配器模式(Strategy Pattern) 解决这个问题 —— 一次抓取,导出到任意平台:
# 同一份数据,一键切换 16 种格式
skill-seekers package output/react --target langchain # LangChain Documents
skill-seekers package output/react --target llama-index # LlamaIndex TextNodes
skill-seekers package output/react --target pinecone # Pinecone Vectors
skill-seekers package output/react --target cursor # Cursor .cursorrules
skill-seekers package output/react --target claude # Claude AI Skills
skill-seekers package output/react --target openai # OpenAI ChatGPT
四、5 分钟搞懂架构:一条配置驱动的数据流水线
整个框架的核心思想可以用一张图说清楚:
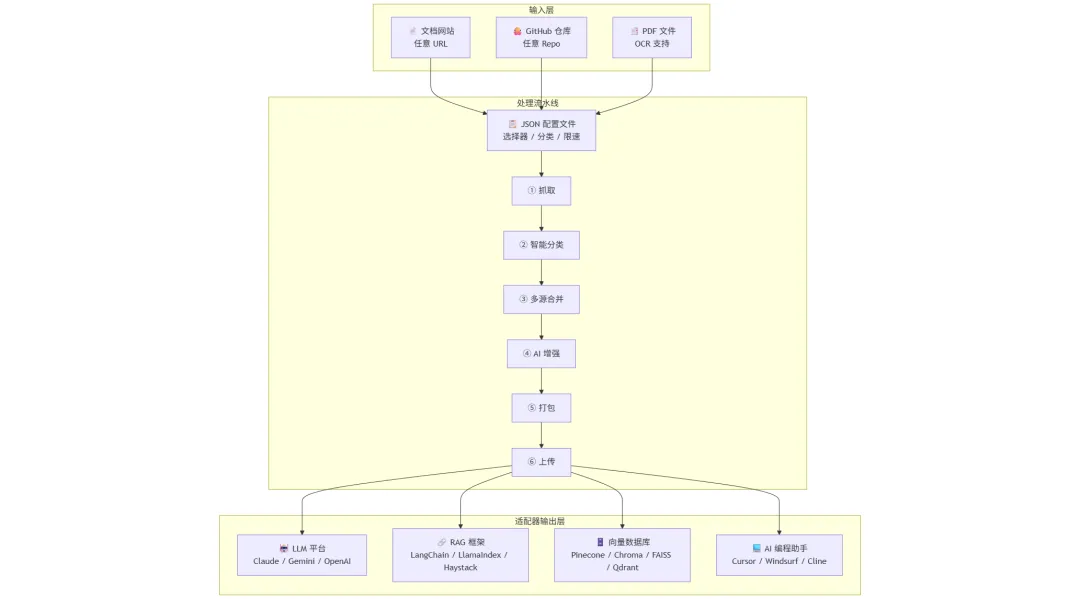
它是怎么”聪明”的?
1. 配置驱动,声明式抓取
你不需要写爬虫代码,只需要定义一个 JSON 配置:
{
"name": "react",
"base_url": "https://react.dev/",
"selectors": {
"main_content": "article",
"title": "h1",
"code_blocks": "pre code"
},
"categories": {
"hooks": ["useState", "useEffect", "useRef"],
"components": ["component", "jsx", "props"]
},
"max_pages": 500,
"rate_limit": 0.5
}
工具会根据配置自动完成:CSS 选择器提取内容、URL 关键词分类、速率限制控制。零代码抓取。
2. 多源合并 + 冲突检测
统一配置可以同时声明多个数据源,工具自动抓取、检测冲突、智能合并:
{
"name": "godot",
"merge_mode": "claude-enhanced",
"sources": [
{ "type": "documentation", "base_url": "https://docs.godotengine.org/" },
{ "type": "github", "repo": "godotengine/godot", "fetch_issues": true}
]
}
3. AI 增强(免费)
抓取完成后,工具自动用 AI 分析原始文档,生成高质量的 SKILL.md:
-
提取 5-10 个最佳代码示例 -
生成按技能层级的导航指南 -
补充关键概念和快速参考 -
质量从 3/10 提升到 9/10
而且如果你有 Claude Code Max 订阅,这一步完全免费(LOCAL 模式)。
五、MCP 集成:让 AI Agent 直接”自助取餐”
Skill Seekers 最”未来感”的特性是 MCP (Model Context Protocol) 深度集成。
它暴露了 25 个 MCP 工具,意味着你的 AI 助手可以用自然语言完成一切操作:
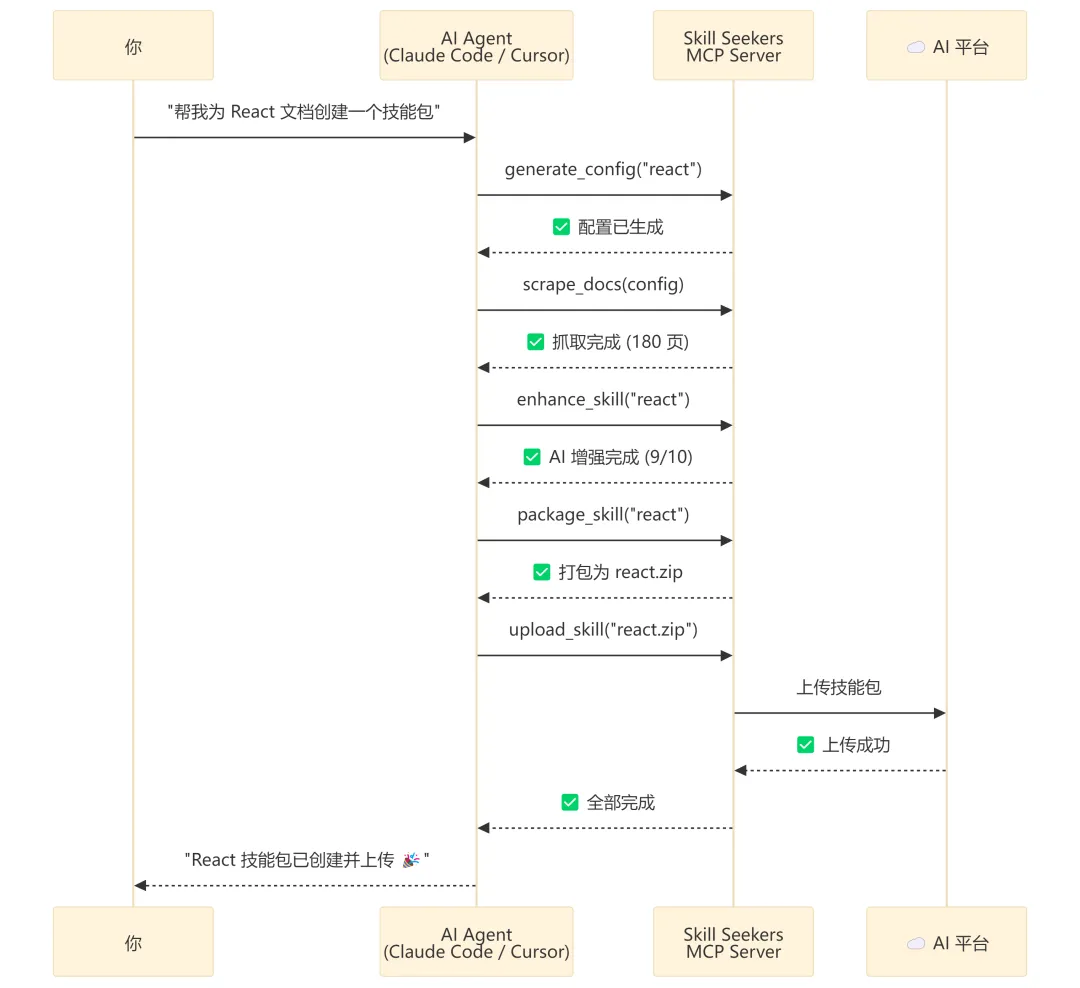
你只说了一句话,AI Agent 帮你跑完了 5 个步骤。这就是 MCP 的威力。
支持 5 大 AI Agent,一键配置
|
|
|
|
|---|---|---|
| Claude Code |
|
|
| VS Code + Cline |
|
|
| Cursor |
|
|
| Windsurf |
|
|
| IntelliJ IDEA |
|
|
安装配置只需要一条命令:
git clone https://github.com/yusufkaraaslan/Skill_Seekers.git
cd Skill_Seekers
./setup_mcp.sh # 自动检测并配置所有已安装的 AI Agent
六、对比:没有 Skill Seekers vs 有 Skill Seekers
|
|
|
|
|---|---|---|
| 抓取 React 文档建 RAG |
|
skill-seekers install --config react
|
| 切换 LangChain → LlamaIndex |
|
--target 参数,5 秒 |
| PDF 技术手册入库 |
|
skill-seekers pdf --pdf manual.pdf
|
| 检查文档与代码是否一致 |
|
|
| 给 Cursor 生成 .cursorrules |
|
|
| 团队共享自定义配置 |
|
|
七、支持的全平台一览
这张表展示了 Skill Seekers 的输出能力有多全面:
🤖 LLM 平台
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
🔗 RAG 框架
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
🗄️ 向量数据库
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
💻 AI 编程助手
|
|
|
|---|---|
|
|
.cursorrules |
|
|
.windsurfrules |
|
|
.clinerules
|
|
|
|
八、上手实战:3 种典型场景
场景 1:为你的项目搭建 RAG 知识库
# 1. 安装
pip install skill-seekers
# 2. 抓取 Django 文档(约 15 分钟)
skill-seekers scrape --config configs/django.json
# 3. 导出为 LangChain 格式
skill-seekers package output/django --target langchain
# 输出:output/django-langchain.json → 直接 load 进 LangChain
# 4. 在你的 RAG 代码里直接使用
场景 2:一键全自动(从配置到上传)
# 一条命令搞定:获取配置 → 抓取 → AI增强 → 打包 → 上传
skill-seekers install --config react
# 20 分钟后,React 技能包自动出现在你的 Claude AI 中
场景 3:给 Cursor/Windsurf 生成专家级上下文
# 抓取框架文档
skill-seekers scrape --config configs/fastapi.json
# 导出 Markdown
skill-seekers package output/fastapi --target markdown
# 复制到项目(Cursor 自动识别)
cp output/fastapi-markdown/SKILL.md my-project/.cursorrules
# 现在 Cursor 的 AI 对 FastAPI 了如指掌 ✌️
九、25 个 MCP 工具全景图
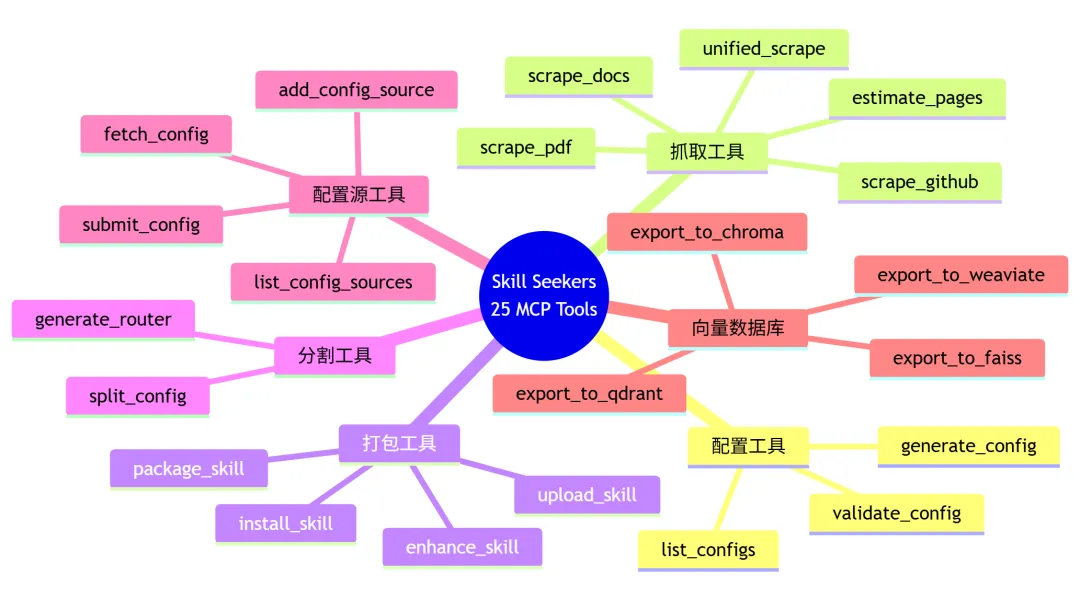
十、技术亮点速览
|
|
|
|---|---|
| 异步爬取 | --async
|
| llms.txt 检测 |
|
| 大文档支持 |
|
| 断点续传 |
--resume 继续,不丢进度 |
| 设计模式检测 |
|
| PDF 全面支持 |
|
| 多 GitHub 账号 |
|
| 企业级配置管理 |
|
十一、适配器架构:为什么能一次抓取输出 16 种格式?
秘密在于经典的 策略模式(Strategy Pattern):所有平台共享同一个 SkillAdaptor 抽象基类,每个平台实现自己的格式化、打包、上传逻辑。
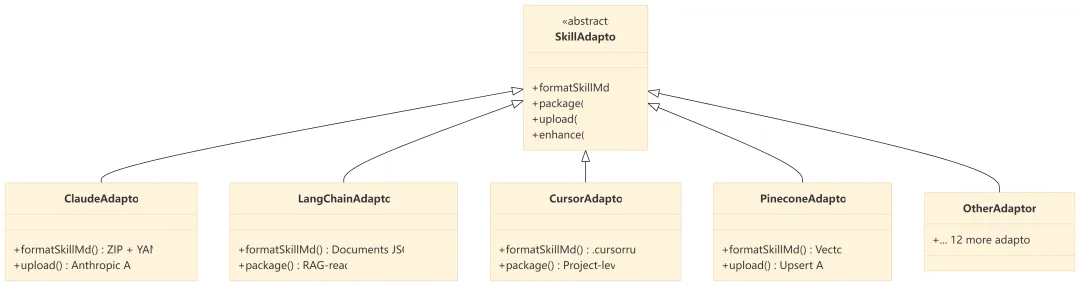
新增一个平台?只需实现一个适配器类,零改动现有代码。这就是好架构的威力。
十二、总结
Skill Seekers 不是又一个爬虫工具。它是一个 AI 系统的通用数据预处理层。
如果你正在做 RAG、给 AI 助手喂知识、或者想让 Cursor/Claude 更懂你的技术栈 —— 试试这个工具,可能会改变你的工作流。
📎 相关链接:
-
GitHub:https://github.com/yusufkaraaslan/Skill_Seekers -
官网:https://skillseekersweb.com -
PyPI: pip install skill-seekers -
中文文档:https://github.com/yusufkaraaslan/Skill_Seekers/blob/main/README.zh-CN.md
你在搭建 RAG 系统时,最头疼的数据处理问题是什么?欢迎留言讨论 👇
