 夜雨聆风
夜雨聆风





谷歌官方文档澄清:HTML 网页抓取上限为 2MB
谷歌近日在官方文档中更新了一项关键数据:Googlebot 针对网页搜索索引进行抓取时,对 HTML 及通用文本文件的处理上限为前 2MB,而 PDF 文件则支持前 64MB。

这意味着在针对Google Search(网页搜索索引)进行抓取时,Googlebot 只读取支持的文件类型(如 HTML、文本文件、CSS、JS 等)的前 2MB 内容,超过的部分将被忽略,不会被用于索引。
1
Google抓取限制规则解读
-
适用范围:只针对 Google Search 的网页抓取(索引用),不是所有 Google 爬虫。比如视频或图片爬虫可能有不同规则。
-
限制规则:
支持文件类型(HTML、文本、CSS、JS 等)→ 只读前 2MB(未压缩大小)。
PDF → 可读前 64MB。
Google 明确说明这个限制基于 uncompressed data(未压缩数据)。
也就是说,服务器发送的是 gzip 压缩后的文件,但 Google 在解压后只处理前 2MB。
-
可以使用G-Bot Limit Checker或者Screaming Frog(500个URL免费额度)检测你的网站,如下图,外贸老船长自己的网站:
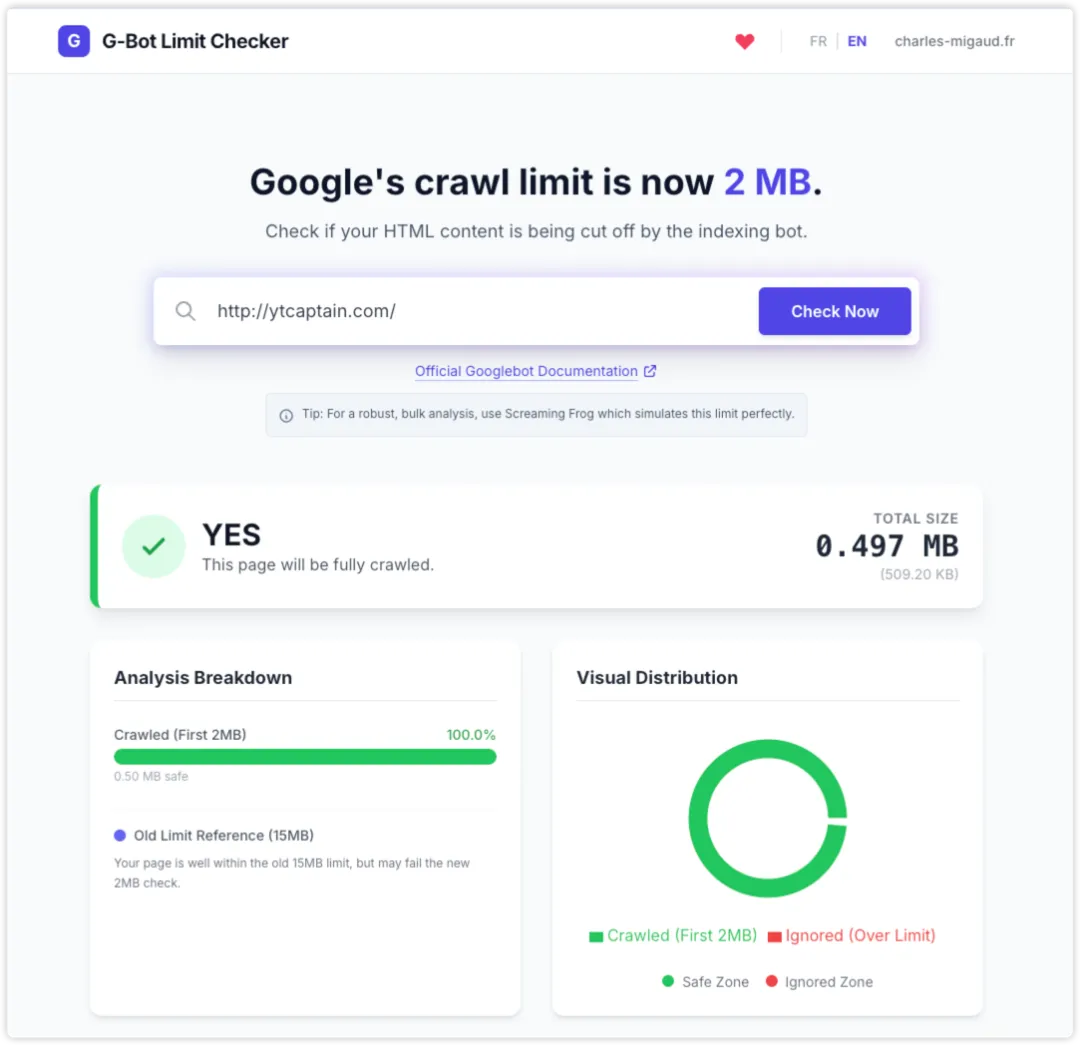
这个页面的 HTML 总大小为 0.497MB,处于 2MB 安全范围内,因此 Googlebot 可以完整抓取这一页的内容。
2
为什么这条规则重要
因为一旦你的 HTML 文件超过 2MB,超出的部分不会进入索引或参与排名。这意味着:
-
页面底部的文字、结构化数据(Schema.org 标记)、或内链可能被忽略。 -
对极少数超大单页,这可能导致 Google “看不见”重要内容。
举个例子:
假设一个产品目录页把所有商品信息都放在一页中,整个 HTML 达到 3MB。那后半部分商品、价格信息,Googlebot 可能根本不读取,自然也不会出现在搜索结果中。
3
2MB到底有多大
2MB 的限制其实已经足够使用了,大部分网站不会超过2MB
- 一般网站所需
目前全球网页 HTML 的中位数约为 20–30KB。 - 字符容量
2MB 的纯文本可容纳 200–300 万字符。 - 超标原因
严重的代码臃肿,页面一次性输出超大HTML,某些自动生成的页面或者技术失误。
4
从 SEO 角度的实用建议
根据这个Google抓取限制,老船长有以下三个建议:
- 检查页面大小
用浏览器或爬虫工具看 HTML 文件是否接近或超过 1MB。 - 优化结构
-
去掉内联的大段 CSS/JS; -
避免在 HTML 中嵌入图片;(图片非常必要的话可以放在PDF文件中) -
把最核心的信息放在文档靠前的位置。 - 特殊情况
如确实需要发布超长文档,可考虑 转换为 PDF,因为 PDF 有 64MB 的宽限。
5
总结
Googlebot 针对网页搜索早就有这种抓取上限,只是 2026 年初谷歌在文档中写得更明确了。
以前的说明较模糊(一般写 15MB),现在细分成了“针对 Search 是 2MB 限制”。
对于网页搜索来说,Googlebot 只索引前 2MB 的网页内容。 绝大多数网站不会受到影响,但如果 HTML 文件超过这个限制,Google 抓取不到页面中后部的重要信息。

往期相关阅读推荐


-
站内优化篇:
-
独立站优化陪跑篇:
老船长自己网站选取了【外贸独立站】词,关键词从没有排名优化到首页计划。


