 夜雨聆风
夜雨聆风





告别杂乱PDF!这个神器能自动转成干净Markdown,表格公式全搞定
你是否也曾面对一堆杂乱的PDF文档感到头疼?扫描件文字无法复制、表格格式错乱、数学公式变成乱码……手动整理这些文档简直是场噩梦。
今天要介绍的开源项目Marker,就是专治各种“文档不服”的神器!它能够快速准确地将PDF、图片、Word、Excel、PPT等多种格式的文档转换成整洁的Markdown、JSON或HTML,连表格、公式、代码块都能完美保留格式。
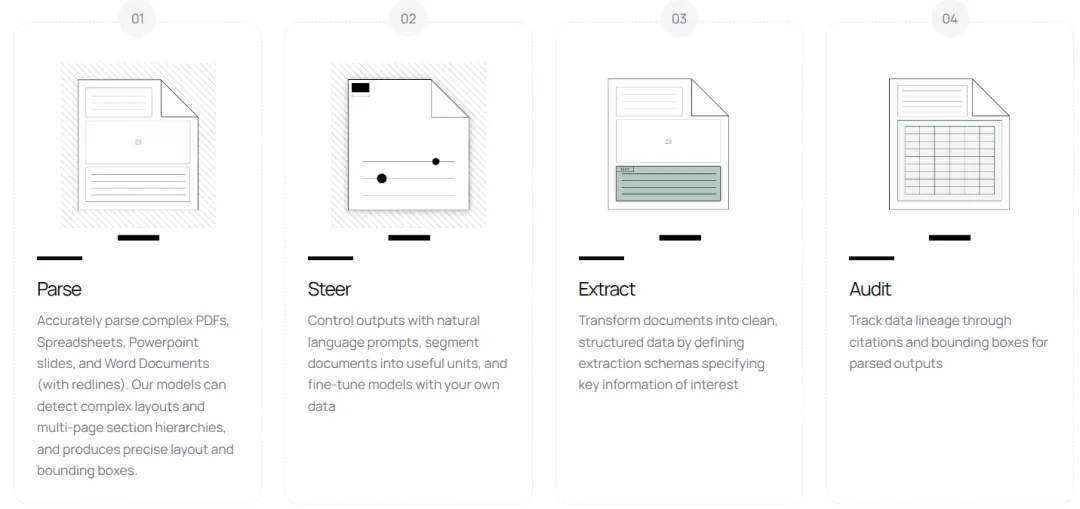
项目亮点
📄 多格式通吃– 支持PDF、图片、PPTX、DOCX、XLSX、HTML、EPUB等主流文档格式🔍智能识别– 自动提取表格、表单、方程、内联数学、链接、参考文献和代码块🖼️图片保存– 提取并保存文档中的图片资源🧹智能清理– 移除页眉/页脚等无关内容⚡高速处理– 支持GPU加速,H100上可达25页/秒的吞吐量🤖LLM增强 – 可调用Gemini或Ollama等LLM提升准确率
解决什么痛点?
想象一下这个场景:你收到一份20页的市场分析报告PDF,里面有复杂的表格、数学公式和各种图表。你需要把这份报告整理成可编辑的Markdown格式分享给团队。
传统方法可能是:用OCR软件识别文字 → 手动调整表格格式 → 重新输入数学公式 → 整理图片引用……整个过程可能要花费几个小时。
Marker的出现彻底改变了这一切。
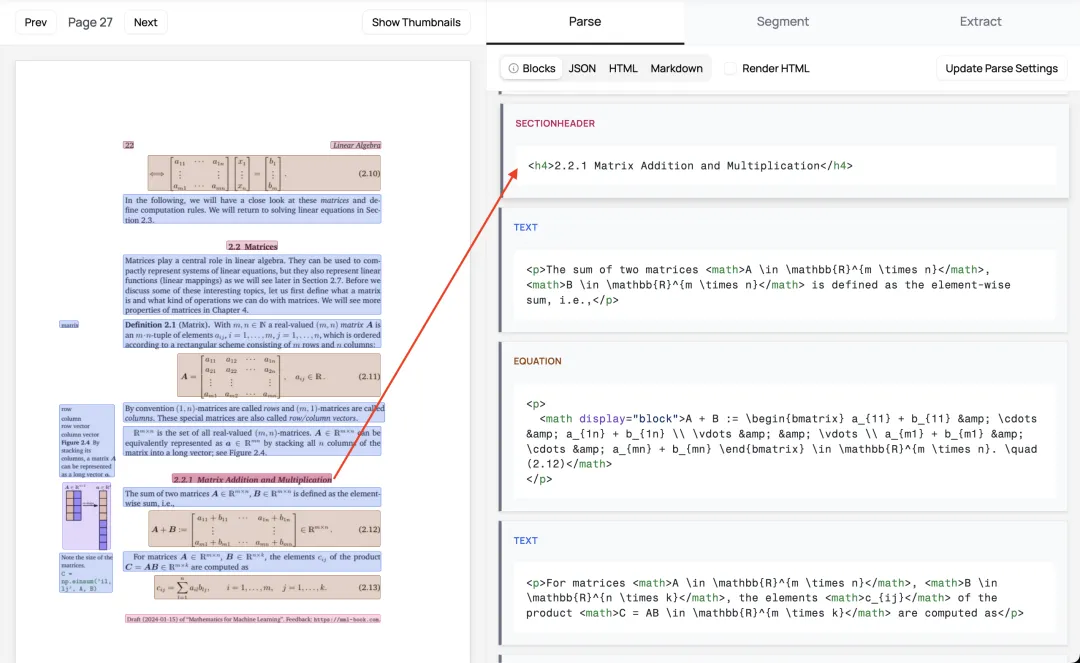
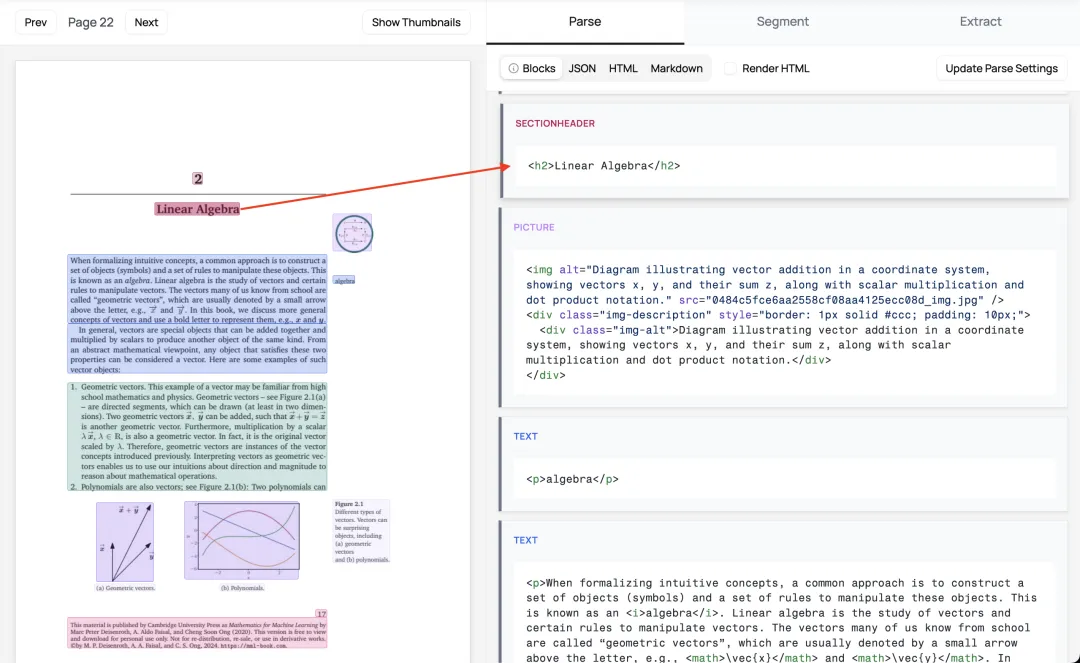
它就像你的智能文档助手,能够理解文档的结构和内容,自动完成格式转换。比如一份学术论文中的复杂表格,Marker不仅能识别出表格结构,还能正确转成GitHub风格的Markdown表格;数学公式会被转换成LaTeX格式;代码块会保持原有的语法高亮样式。
更厉害的是,Marker在准确性上表现突出。根据官方基准测试,它在大多数场景下都优于其他开源工具,甚至在某些方面超越了Mathpix、Llamaparse等云服务。
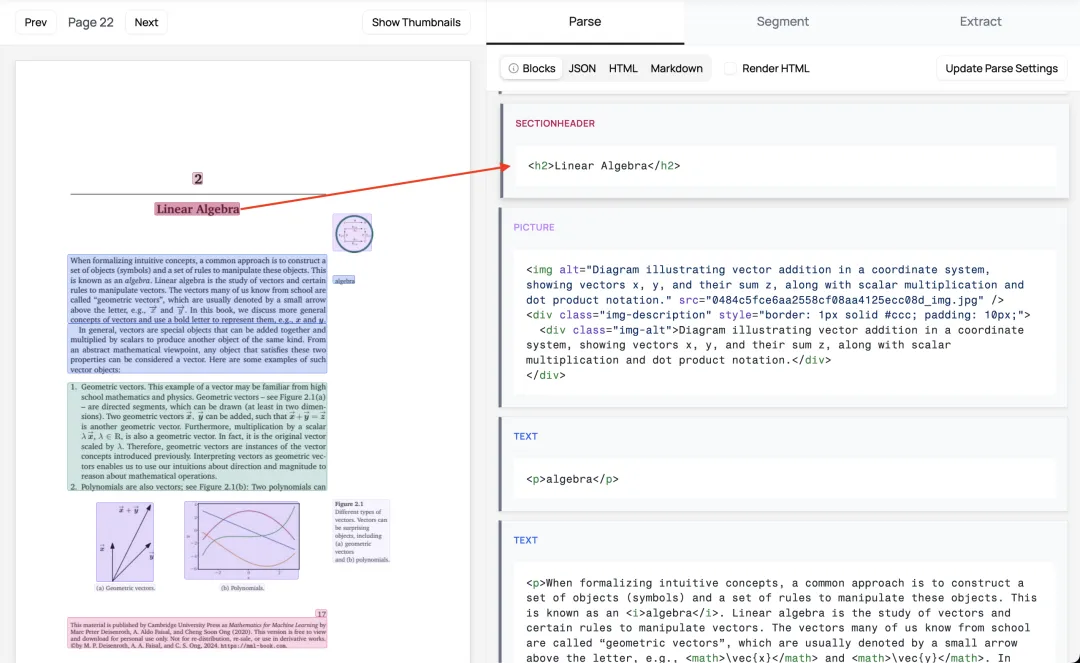
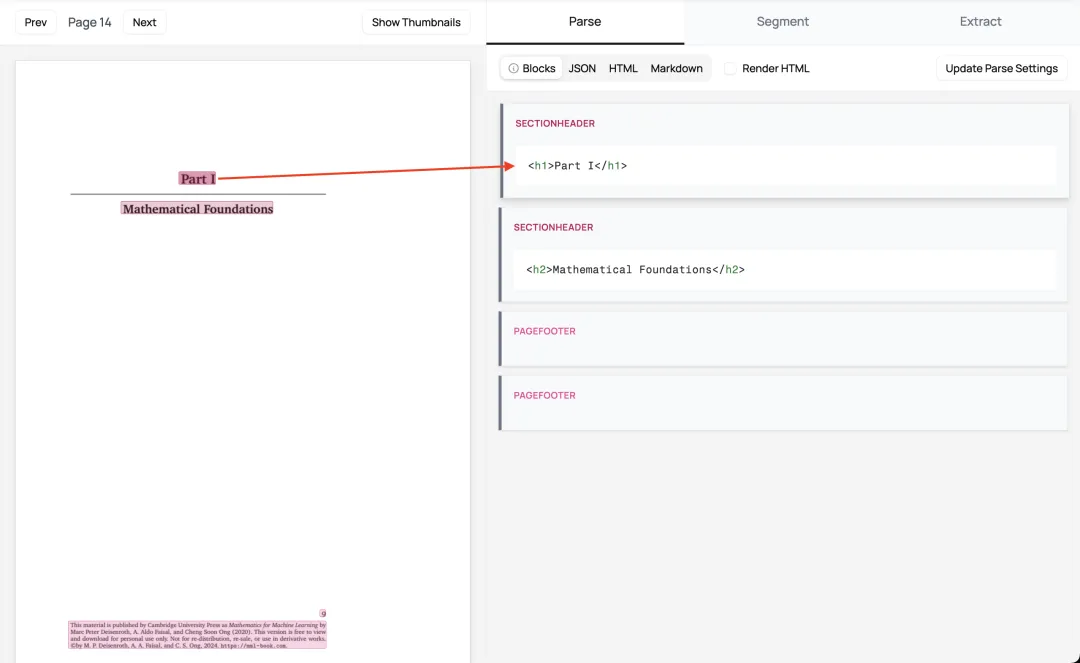
手把手教程
环境安装
首先确保你的Python环境在3.8以上,然后安装Marker:
pip install marker-python如果需要GPU支持,还需要安装PyTorch的CUDA版本。如果你只是想快速体验,CPU版本也完全够用。
基础使用:转换单个文档
最简单的使用方式就是命令行转换。假设你有一个名为report.pdf的文档:
marker_single report.pdf --output_dir ./output转换完成后,你会在./output目录下找到:
report.md
– Markdown格式的文档内容 report_meta.json
– 文档的元数据信息 -
相关的图片文件(如果文档中有图片)
批量处理文档
如果你有一整个文件夹的文档需要处理,可以使用批量转换功能:
marker_convert /path/to/documents --output_dir ./batch_output这个命令会递归处理指定目录下的所有支持格式的文档,非常方便!
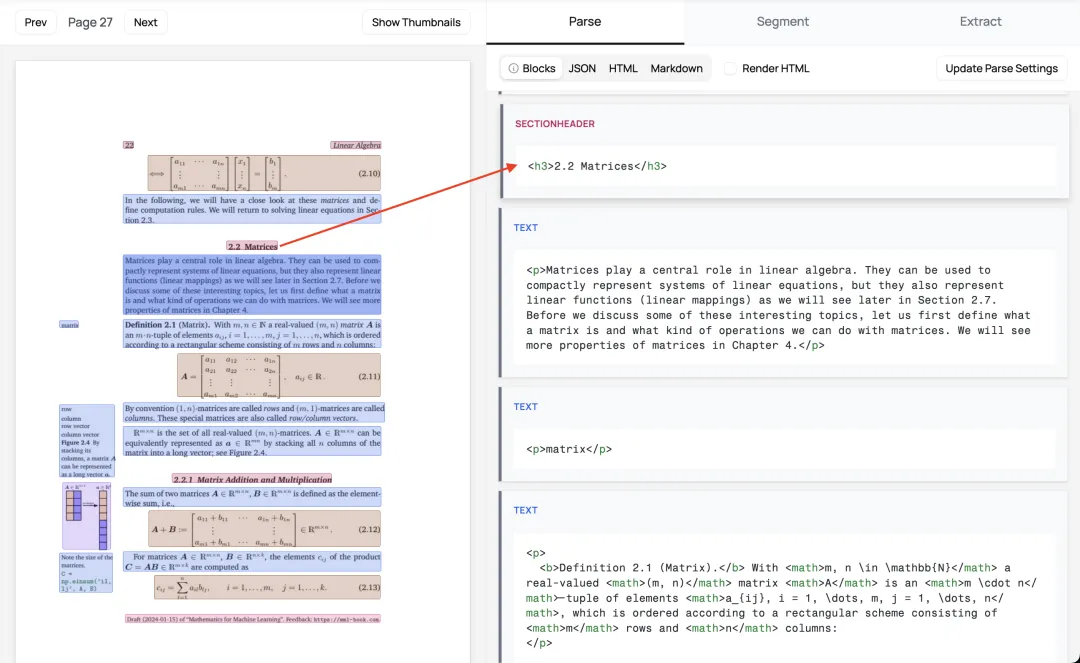
高级功能:启用LLM增强
对于特别复杂的文档,你可以启用LLM来提升转换质量。Marker支持Gemini和Ollama等模型:
marker_single report.pdf --use_llm --llm_service gemini --output_dir ./output启用LLM后,Marker会:
-
更好地合并跨页的表格 -
更准确地处理内联数学公式 -
优化表格格式 -
从表单中提取值
虽然这会稍微增加处理时间,但对于追求完美的场景来说非常值得。
代码集成使用
除了命令行,你还可以在Python代码中直接使用Marker:
from marker.converters.pdf import PdfConverterfrom marker.models import create_model_dict# 初始化模型model_dict = create_model_dict()# 创建转换器converter = PdfConverter(artifact_dict=model_dict)# 转换文档result = converter("your_document.pdf")print(result.markdown) # 获取Markdown内容配置选项详解
Marker提供了丰富的配置选项,满足不同需求:
config = {"page_range": "0-10", # 只处理前11页"output_format": "json", # 输出JSON格式"use_llm": True, # 启用LLM增强"llm_service": "gemini", # 使用Gemini服务"disable_tqdm": True, # 禁用进度条"force_ocr": False, # 是否强制OCR}Web界面体验
如果你更喜欢图形化操作,Marker还提供了Streamlit界面:
marker_streamlit然后在浏览器中打开http://localhost:8501,就可以通过网页上传和转换文档了,特别适合非技术用户使用。
同类项目对比
为了让你更清楚Marker的优势,这里有一个简单的对比表格:
|
|
|
|
|
|
|---|---|---|---|---|
| 开源免费 |
|
|
|
|
| 本地部署 |
|
|
|
|
| 多格式支持 |
|
|
|
|
| 表格识别 |
|
|
|
|
| 公式处理 |
|
|
|
|
| LLM集成 |
|
|
|
|
| 处理速度 |
|
|
|
|
| 准确率 |
|
|
|
|
从对比中可以看出,Marker在开源免费、本地部署、处理速度和功能全面性方面都有明显优势。虽然Mathpix在某些单项上略胜一筹,但它是收费服务,且需要网络连接。
实际应用场景
学术研究
研究人员经常需要阅读大量PDF论文。使用Marker可以将这些论文转换成Markdown,方便做笔记、提取引用和整理参考文献。特别是数学公式的准确转换,大大节省了手动输入的时间。
企业文档管理
公司内部有大量的报告、合同、说明书等文档。Marker可以帮助建立统一的文档知识库,所有文档都转换成结构化的Markdown或JSON格式,便于搜索和内容提取。
内容创作
自媒体作者需要从各种资料中收集信息。Marker可以快速从PDF报告、研究文档中提取有用内容,保留原有的表格和格式,直接用于文章创作。
教育培训
老师可以将教材、习题集转换成可编辑格式,方便制作课件和在线学习材料。学生也可以用它来整理学习笔记。
性能优化技巧
硬件选择
- GPU加速
:如果有NVIDIA GPU,处理速度可以提升5-10倍 - 内存充足
:处理大型文档时,建议至少有8GB可用内存 - 存储空间
:转换后的图片会占用额外空间,确保有足够存储
参数调优
- 批量大小调整
:根据硬件调整 batch_size参数 - 选择性处理
:使用 page_range只处理需要的页面 - 输出格式选择
:如果只需要文本,选择Markdown格式最快
错误处理
如果遇到转换失败的情况,可以:
-
检查文档是否加密或损坏 -
尝试启用 force_ocr选项 -
查看日志文件定位问题
社区与生态
Marker基于Surya OCR引擎构建,这是一个专门为文档处理设计的现代OCR系统。项目代码完全开源,采用Apache 2.0许可证,可以自由商用。
结语
在这个信息爆炸的时代,高效处理文档已经成为必备技能。Marker就像给你的电脑装上了“文档理解大脑”,让机器真正理解文档内容,而不只是简单的文字识别。
无论你是学生、研究员、内容创作者还是企业员工,Marker都能显著提升你处理文档的效率。最棒的是,它完全免费开源,你可以在本地部署,完全掌控自己的数据隐私。
现在就去尝试一下Marker吧,感受智能文档转换带来的便利!你会发现,那些曾经令人头疼的文档整理工作,现在只需要几分钟就能搞定。
转换的不只是格式,更是工作效率的飞跃。让我们一起告别手动整理文档的时代,迎接智能文档处理的新篇章!
