 夜雨聆风
夜雨聆风





文档重建解锁可扩展的长上下文 RLVR (Document Reconstruction Unlocks Scalable Long-Context RLVR)
Document Reconstruction Unlocks Scalable Long-Context RLVR
Authors: Yao Xiao, Lei Wang, Yue Deng, Guanzheng Chen, Ziqi Jin, Jung-jae Kim, Xiaoli Li, Roy Ka-wei Lee, Lidong Bing
Deep-Dive Summary:
摘要 (Abstract)
具有可验证奖励的强化学习(RLVR)已成为增强大语言模型(LLM)能力(如长上下文处理)的重要范式。然而,这种方法通常依赖于黄金标准答案或由强大的教师模型、人类专家提供的明确评估准则,这既昂贵又耗时。本研究探索了一种无监督方法来增强 LLM 的长上下文能力,消除了对重度人工标注或教师模型监督的需求。具体而言,我们首先将长文档中的部分段落替换为特殊的占位符。通过强化学习训练 LLM,使其从一组候选选项中正确识别并排序缺失的段落,从而重建文档。这种训练范式使模型能够捕获全局叙事的连贯性,显著提升了长上下文性能。我们在 RULER 和 LongBench v2 两个基准测试上验证了该方法的有效性。在无需人工标注的长上下文 QA 数据的情况下,模型在 RULER 上获得了显著收益,并在 LongBench v2 上实现了合理的改进。
1 引言 (Introduction)
具有可验证奖励的强化学习(RLVR)近期在大语言模型推理领域达到了最前沿水平,例如 DeepSeek-R1 利用地面真值(ground-truth)反馈引导生成,在数学和编程等领域表现卓越。然而,随着 LLM 向能够处理海量真实数据的智能体演进,挑战已从局部逻辑推理转向全局上下文处理。
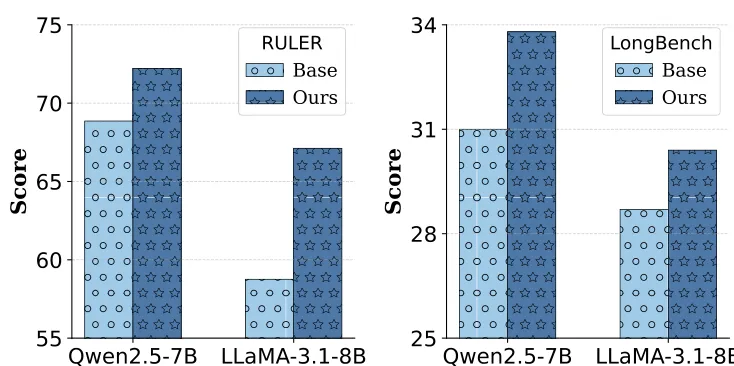
图 1:Qwen2.5-7B-Instruct-1M 和 LLaMA-3.1-8B-Instruct 在 RULER 平均分和 LongBench v2 总分上的表现报告。
目前的模型往往在处理数万个 token 时的检索与综合信息方面表现挣扎,出现“迷失在中间”或逻辑不一致的问题。虽然 RLVR 是处理长程依赖的强大框架,但其应用受限于外部监督的可用性。为了解决长上下文训练数据稀缺且昂贵的问题,本文提出了一种全无监督的 RLVR 框架,利用文档固有的结构(叙事流和逻辑顺序)作为天然的可验证奖励信号。通过“文档重建”任务——即将长文档中掩盖的段落进行正确排序——引导模型理解全局结构。
2 背景 (Background)
**组相对策略优化 (GRPO)**:GRPO 是一种策略梯度方法,通过估计组内采样响应的相对优势来取消对显式价值函数的依赖。给定查询 ,GRPO 采样一组轨迹 ,并通过对奖励进行归一化来计算优势值:
GRPO 使用 PPO 风格的裁剪代理目标函数进行优化:
其中 。
3 方法 (Method)
3.1 任务公式化:文档重建
给定包含 个段落的文档 ,随机掩盖其中一些段落并用占位符 <CHUNK_i>MISSING</CHUNK_i> 替换。模型需要分析逻辑结构,并从乱序的候选池中按顺序生成正确的选项列表(例如 )。
3.2 奖励设计
我们定义了一个兼顾全局准确性和细粒度反馈的可验证奖励函数:
其中 是掩盖段落的总数, 是预测, 是真值。ValidPermutation 确保模型使用了完整的候选池。如果预测完全正确,奖励为 1;如果顺序不完全正确但属于有效排列,则按正确位置的比例给予部分奖励;格式错误或无效排列则为 0。
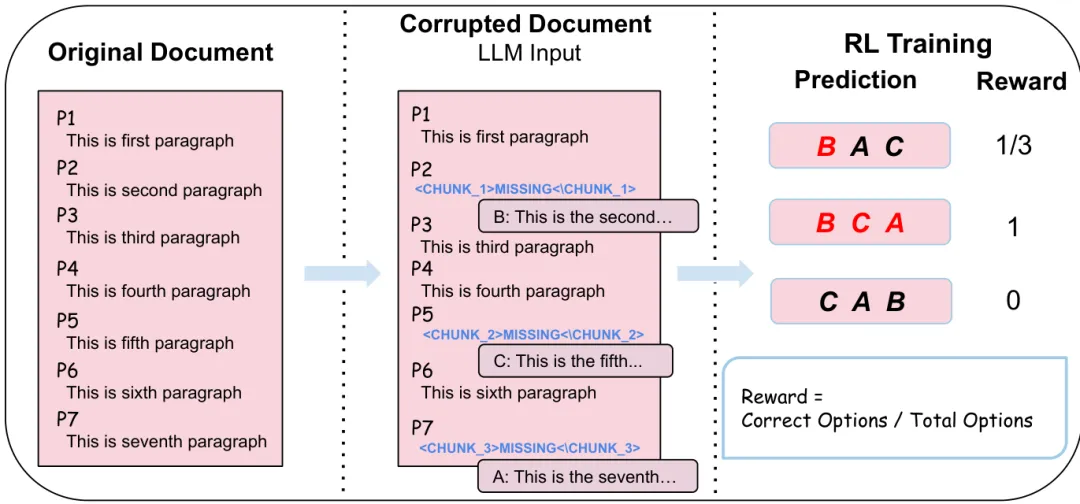
图 2:文档重建框架概览。给定长文档,通过选择部分段落并打乱作为选项来破坏文档。通过 RLVR 训练 LLM 按顺序生成选项序列以重建文档。
3.3 复杂度缩放的课程学习
通过调整 的大小来控制难度。随着 增加,排列组合空间 指数级增长。课程学习允许模型先掌握少选项的局部连贯性,再挑战极长上下文下的复杂全局依赖。
4 实验设置 (Experimental Setup)
-
数据采集:从书籍、arXiv 论文和代码中提取 14,000 篇最长文档。设置 ,比例为 。平均 token 数约为 49,000。 -
训练:采用 GRPO 算法,学习率为 1e-6,最大上下文长度 64K。 -
评估基准:RULER(合成推理任务)和 LongBench v2(真实多选 QA)。 -
基线模型:LLaMA-3.1-8B-Instruct 和 Qwen2.5-7B-Instruct-1M。
5 结果与分析 (Results and Analysis)
5.1 主要结果
如图 3 所示,我们的方法在 RULER 上取得了实质性提升,且增益随上下文长度(32K 到 128K)增加而增大。在 LongBench v2 上也有稳步改进,这证明了重建训练在处理真实 QA 任务中的有效性。
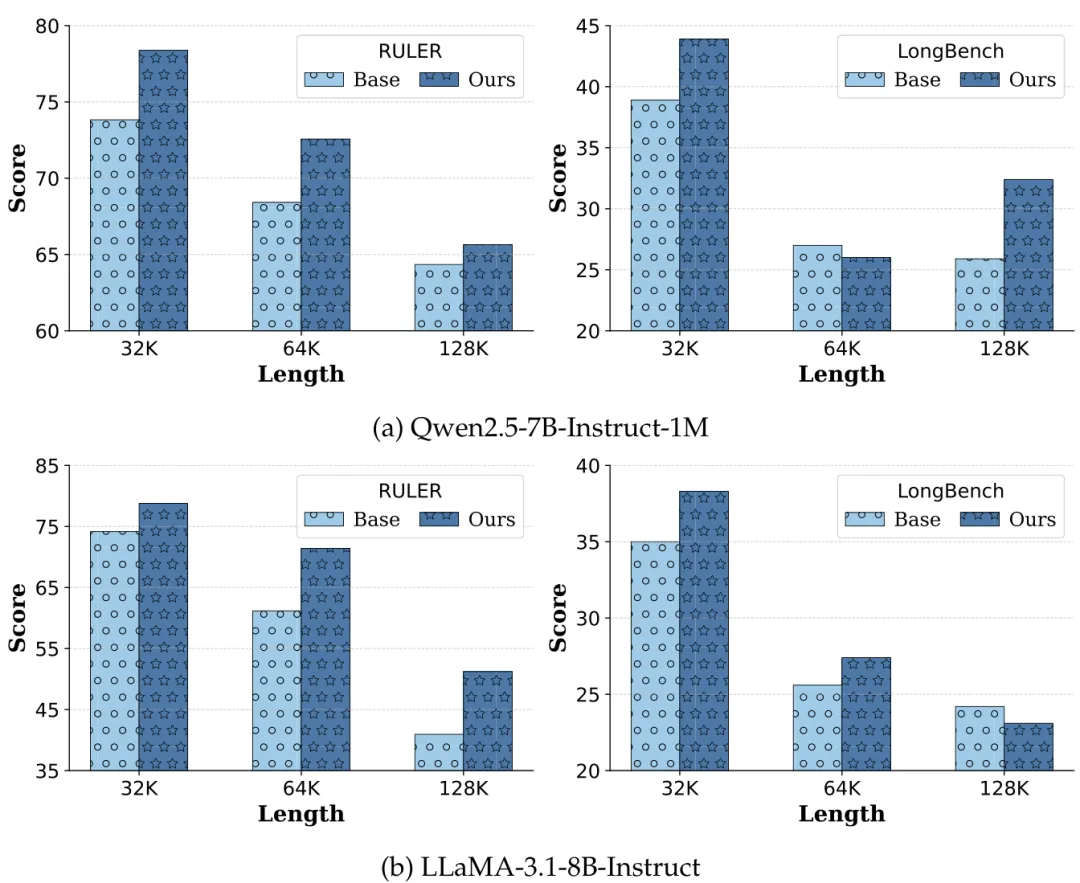
图 3:不同上下文长度和模型下的性能对比。
5.2 密集奖励 vs. 稀疏奖励
比较式 (1) 的密集奖励与仅在全对时给 1 分的稀疏奖励。实验发现(图 4),稀疏奖励会导致训练不稳定,特别是在 Qwen2.5 模型上表现显著下降。
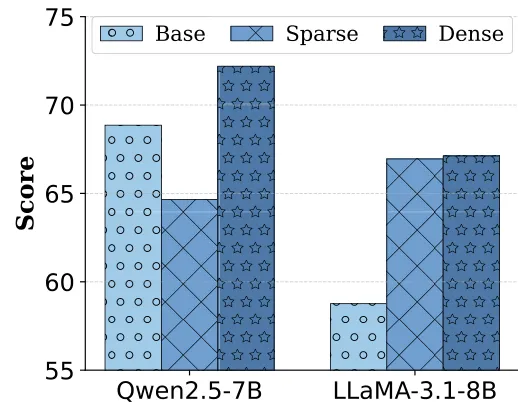
图 4:RULER 平均分对比密集奖励与稀疏奖励。
5.3 对选项混合比例的鲁棒性
实验表明(图 5),无论 的分布比例如何变化,模型性能均保持稳健,证明该框架不依赖于特定的数据组成。
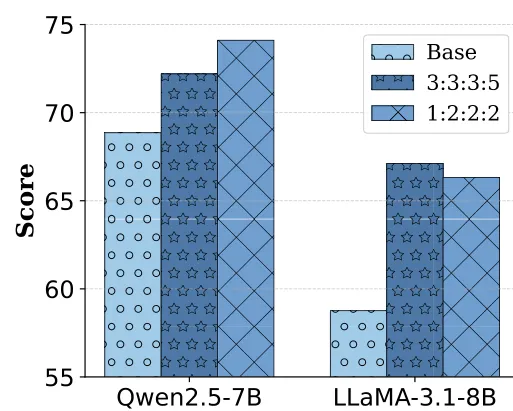
图 5:RULER 平均分对比不同选项长度混合比例的表现。
5.4 越长的文档带来越稳定的提升
对比最长、最短和随机文档训练。结果显示(图 6),长文档训练对增强长上下文理解至关重要。
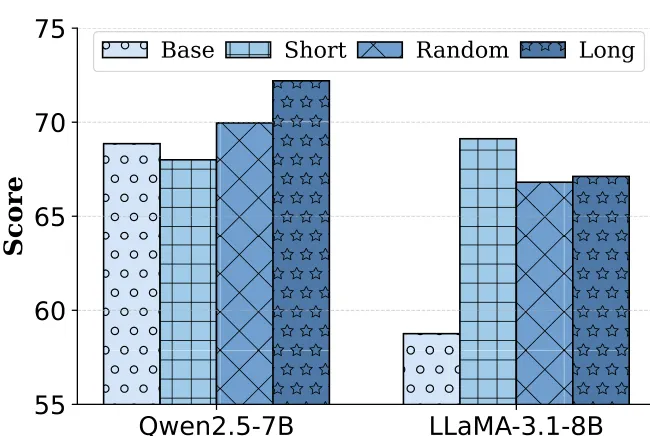
图 6:RULER 平均分报告。
5.5 数据规模效应
性能随重建训练样本数量的增加而提升。如图 7 所示,当样本量超过 4,000 时,性能显著增长,且在 14,000 规模下尚未见顶。
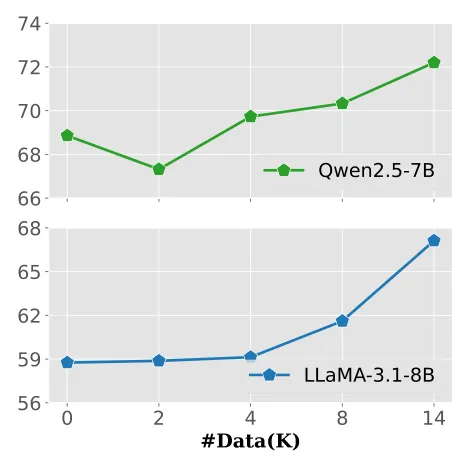
图 7:数据规模从 0 扩展到 14K 时的 RULER 平均分。
5.6 训练策略:是否打乱
课程学习(逐渐增加 )在两个模型上均优于完全打乱难度的训练。
5.7 选项长度分析
虽然 越大任务越难,但模型在不同固定 下的表现相对稳定(如表 2)。中等长度( 或 )在学习效率和难度之间取得了较好的平衡。
6 相关工作 (Related Work)
-
RLVR:目前主要用于数学和编程等具备明确对错标准的领域(如 DeepSeek 和 OpenAI o1)。 -
长上下文训练:传统方法多依赖合成数据的 SFT(监督微调),往往面临数据质量低或复杂度表面化的问题。本文提出的无监督 RLVR 为此提供了更具扩展性的替代方案。
7 结论 (Conclusion)
本文提出了一种基于文档重建的无监督强化学习框架。该方法通过直接从原始文档推导可验证奖励,消除了对人工标注的依赖。实验证明,该方法能有效提升 LLM 的全局连贯性和长程依赖处理能力,为开发更强大的长上下文语言模型提供了可扩展的路径。
8 局限性 (Limitations)
-
依赖高质量、结构化的长文档。 -
增益程度在不同架构的模型间存在差异。 -
更大规模数据和更大参数量模型下的表现仍待进一步研究。
Original Abstract: Reinforcement Learning with Verifiable Rewards~(RLVR) has become a prominent paradigm to enhance the capabilities (i.e.\ long-context) of Large Language Models~(LLMs). However, it often relies on gold-standard answers or explicit evaluation rubrics provided by powerful teacher models or human experts, which are costly and time-consuming. In this work, we investigate unsupervised approaches to enhance the long-context capabilities of LLMs, eliminating the need for heavy human annotations or teacher models’ supervision. Specifically, we first replace a few paragraphs with special placeholders in a long document. LLMs are trained through reinforcement learning to reconstruct the document by correctly identifying and sequencing missing paragraphs from a set of candidate options. This training paradigm enables the model to capture global narrative coherence, significantly boosting long-context performance. We validate the effectiveness of our method on two widely used benchmarks, RULER and LongBench~v2. While acquiring noticeable gains on RULER, it can also achieve a reasonable improvement on LongBench~v2 without any manually curated long-context QA data. Furthermore, we conduct extensive ablation studies to analyze the impact of reward design, data curation strategies, training schemes, and data scaling effects on model performance. We publicly release our code, data, and models.
PDF Link:2602.08237v1
