 夜雨聆风
夜雨聆风





从源码角度看 vLLM:进程模型与推理执行链路
我花了三周业余时间,一行行跟着源码把 vLLM 从启动流程、进程管理、调度逻辑一直跟到真正跑模型的那一刻走完了整条链路。
不是简单看个 README 或复制 config 参数,而是像读系统源码一样,把每一个进程、每一个组件、每一层并行到底在干什么都梳理清楚了。
这篇文章不讲玄学优化、不讲参数推荐,也不讲 benchmark 排名。
它讲的是 vLLM 内部 真正发生了什么。
前置环境
vllm main分支,version = 0.14.0rc1.dev389+g72c068b8e
commit 72c068b8e0f084a6a6257d6736e459495f9f56a8 (HEAD -> main, origin/main, origin/HEAD)Author: TJian <tunjian.tan@embeddedllm.com>Date: Thu Jan 8 21:42:01 2026 +0800[CI] [Bugfix] Fix unbounded variable in `run-multi-node-test.sh` (#31967)Signed-off-by: tjtanaa <tunjian.tan@embeddedllm.com>
使用的是Nvidia RTX 3090 or RTX 5090. 编译了cuda 内核
下面是全链路解析vLLM, vLLM的全景图
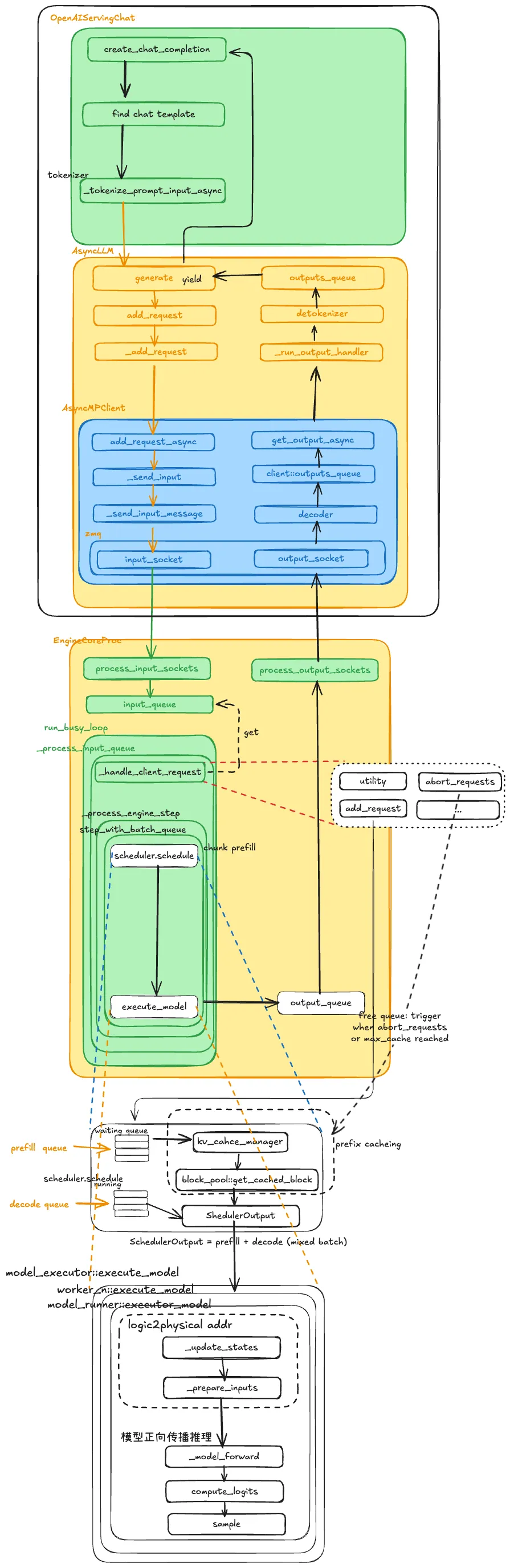
整体结构
客户端请求API Server→ AsyncLLM→ EngineCore→ Scheduler→ KV Cache 管理→ Executor→ Worker→ Model→ 输出返回
GPU 只是最后干活的,
真正决定 谁先算、一起算谁、显存够不够 的,是中间那层 EngineCore。
请求刚进来时,从用户角度,就是一句:
client.chat.completions.create(...)全链路拆解
API Server 里做了两件事
-
拼 prompt Chat 模型会:
这一步还是纯字符串操作。
-
把 system / user / assistant 拼起来 -
找 chat template -
做 tokenizer
这一步很关键:Tokenizer 在 API Server 进程里就做完了。后面传给 EngineCore 的,不是文本,而是:
List[int] # token ids所以:
-
EngineCore 不关心 tokenizer -
GPU 更不关心你原始问了啥
具体流程:
当客户端调用 create_chat_completion 这样的接口时,请求首先进入的是 vLLM 提供的 OpenAI 兼容 API Server。这一层本质是一个标准的服务端应用,负责 HTTP 协议处理和业务层逻辑,它还没有进入真正的“推理引擎”。
首先发生的是 prompt 的构造。如果是 Chat 类型模型,服务端会根据模型配置选择对应的 chat template,然后把 system、user、assistant 等角色的内容拼接成一段完整的 prompt 文本。这一步是纯字符串层面的处理,与模型推理还没有直接关系。
接下来是 tokenizer 执行。API Server 会调用对应模型的 tokenizer,将刚刚构造好的 prompt 字符串转换为 token id 序列。从这一刻开始,请求就从“文本语义”进入了“数值计算”领域。需要强调的是,这一步是在 API Server 进程内完成的,后续的 EngineCore 和 GPU 侧完全不会再做 tokenizer,它们只处理已经分好词的 token 序列。
当 token ids 准备好之后,API 层会调用 AsyncLLM.generate,把这次请求交给底层的推理系统。到这里为止,整个过程都还停留在 API Server 进程内。
AsyncLLM:只是个跨进程搬运工
AsyncLLM.generate()这个类名字很唬人,其实核心职责很朴素:
把请求通过 ZMQ 发给 EngineCore,再把结果收回来。
这里发生了一次进程边界的跨越:
|
之前 |
之后 |
|
API 逻辑 |
推理引擎逻辑 |
|
文本世界 |
token + 调度世界 |
AsyncLLM 本身不参与调度、不参与模型计算,只维护:
-
add_request -
outputs_queue -
后台线程收结果
具体流程:
AsyncLLM 处在 API Server 和 EngineCore 之间,是一个典型的客户端适配层。它本身并不参与模型调度和计算,而是负责把请求安全、异步地送入推理引擎,并把结果再取回来。
在这一层,系统会为当前请求构造一个内部的请求对象,其中包含 token ids、采样参数、最大生成长度、request_id 等元信息。这是一次推理任务在引擎内部的完整描述形式。
随后 AsyncLLM 会通过 ZeroMQ 的 input socket,把这个请求发送到 EngineCore 所在的进程。这里是整个系统的第一次关键进程边界切换,从 API 服务进程进入专门的推理调度进程。也正因为是多进程架构,API 层的稳定性与推理层的高负载被隔离开来。
同时,AsyncLLM 内部还会维护一个输出队列和后台线程,用于持续从 EngineCore 接收模型生成的 token 结果,为后续的流式返回做准备。
每个请求对应一个输出队列 dict[str, RequestState] 是每个请求有一个request state,里面包含一个queue,
self.request_states: dict[str, RequestState]class RequestState:def __init__(self,request_id: str,parent_req: ParentRequest | None,request_index: int,lora_name: str | None,output_kind: RequestOutputKind,prompt: str | None,prompt_token_ids: list[int] | None,prompt_embeds: torch.Tensor | None,logprobs_processor: LogprobsProcessor | None,detokenizer: IncrementalDetokenizer | None,max_tokens_param: int | None,arrival_time: float,queue: RequestOutputCollector | None,log_stats: bool,stream_interval: int,top_p: float | None = None,n: int | None = None,temperature: float | None = None,):
当通过协程_run_output_handler,通过zmq 拉取到响应之后,根据request_id 找到请求的RequestState 来把收到的消息push 到state的queue中
_run_output_handlerAsyncMPClient —— 异步多进程 EngineCore 客户端
在 vLLM 的异步推理架构里,AsyncMPClient 是连接 AsyncLLM 与核心引擎 EngineCore 的关键组件。
它在结构上是一个 异步 + 多进程 的客户端,用于在主进程(通常是 API Server / AsyncLLM 所在进程)和一个或多个引擎进程之间进行异步通信。
具体细节
-
多进程隔离与并行执行AsyncMPClient 派生自 MPClient,在内部通过启动一个或多个独立 EngineCore 进程来执行推理任务;这样主进程无需加载模型,也不会被推理阻塞。EngineCore 在子进程中运行、循环读取请求、输出结果。 -
异步非阻塞调度与传统的同步客户端不同,AsyncMPClient 支持一套基于 asyncio 的异步方法(如:add_request_async()、get_output_async() 等),可以通过 await 进行非阻塞的提交与取回。对于高并发 API Server 场景而言,这种设计极大提升了吞吐量和响应效率。 -
实现细节(IPC + 负载均衡)它通常通过 ZMQ 或类似的进程间通信(IPC)机制,将序列化后的推理请求发送给后台 EngineCore 进程,再将执行结果取回;同时在多 EngineCore 时,AsyncMPClient/其派生类(如 DPLBAsyncMPClient)会做一定的负载均衡分发。 -
与 AsyncLLM 的关系
-
AsyncLLM 是面向外部 HTTP/OpenAI 协议的异步推理接口层,它负责处理输入、输出、流式响应等逻辑。 -
AsyncMPClient 则作为 AsyncLLM 与 EngineCore 之间的桥梁,负责将 AsyncLLM 提交的异步推理任务传递给 EngineCore 并异步获取结果。换句话说,AsyncLLM 实现了协议层的异步逻辑,而 AsyncMPClient 实现了 IPC + 多进程异步推理的执行层。
EngineCore:真正的主角
EngineCore 是一个独立进程,里面有两个关键组件:
|
组件 |
职责 |
|
Scheduler |
决定这一轮 GPU 要算哪些序列 |
|
Executor |
真正去调 Worker 执行模型 |
它一直在跑一个循环,大概是:
while True:收新请求更新请求状态调度一批序列执行一轮模型计算处理输出
这看起来像普通 event loop,但里面有 vLLM 最核心的设计。
具体流程:
EngineCore 是 vLLM 在线推理的核心。每一个 EngineCore 都是一个独立进程,内部包含调度器 Scheduler 和执行器 Executor。它通过一个持续运行的事件循环,驱动整个推理系统向前推进。
EngineCore 的主循环会不断执行几个步骤。首先,它通过 process_input_sockets 从 ZMQ 读取新的请求,并将其放入内部的 input_queue。接着,系统调用内部的请求处理逻辑,把这些新请求注册到 Scheduler 中,为它们初始化状态。
从这里开始,请求在系统里的身份就从“外部调用”变成了“可调度的推理序列”。后续的每一步计算,都会围绕 Scheduler 的决策展开。
vLLM 的核心机制:Continuous Batching
传统推理框架的思路是:
凑一个 batch → 一起跑 forward
vLLM 的思路完全不同:
GPU 每走一步,我都要重新决定“这一步一起算谁”
它把每个请求拆成两个阶段:
|
阶段 |
特点 |
|
Prefill |
处理 prompt,一次很多 token,算力重,但只发生一次 |
|
Decode |
每步只生成 1 个 token,很轻,但要重复很多次 |
调度时,Scheduler 会同时从两类队列里选:
-
一些还没开始的请求 → 做 Prefill -
一些已经在生成中的请求 → 做 Decode
拼成一个混合 batch。
这就是所谓的 Continuous Batching:
batch 不是一次性固定的,而是每一小步都在重组。
GPU 几乎不会等所有序列“步调一致”,谁能算就先上。
具体流程:
Scheduler 是 vLLM 架构中最关键的组件。它的职责不是计算模型,而是决定在当前这一步 GPU 计算中,应该让哪些序列参与。
每个新请求进入系统后,首先会被放入 waiting 队列,表示它还没有真正开始执行模型。与此同时,已经生成了一部分 token 的请求则位于 running 队列中,等待继续 decode。
Scheduler 在每一轮调度时,都会执行一次 schedule 逻辑,核心问题是“这一小步 GPU 该算哪些 token”。它会同时从 waiting 和 running 两个队列中挑选合适的序列,形成一个混合 batch。
这里的关键在于 vLLM 将请求分为 prefill 阶段和 decode 阶段。Prefill 阶段用于处理完整 prompt,一次会涉及多个 token 的 attention 计算,计算量较大但只发生一次。Decode 阶段则是每次只生成一个新 token,计算量较小但会重复很多次。Scheduler 会在同一个 batch 中混合 prefill 和 decode 任务,从而让 GPU 在每一个计算步都保持较高利用率。这就是所谓的 Continuous Batching。
KV Cache:显存管理才是硬问题
真正限制并发的不是算力,而是显存,也是目前硬件的现状 memory bound。
vLLM 没给每个请求一整块连续 KV cache,而是:
1 把 KV Cache 切成 block
可以理解为:
把 KV cache 当成“显存分页系统”
2 调度时先问:还有没有 block?
Scheduler 在安排 Prefill / Decode 之前,会检查:
-
这个请求接下来需要多少 KV block? -
当前 pool 里够不够?
不够就不调度,避免 OOM。
所以调度器不仅在排“算力队列”,还在排“显存队列”。
3 Prefix Caching:前缀能复用就复用
如果两个请求前半段 prompt 一样:
-
后来的请求可以直接复用已有的 KV block -
不用重新算那一段 attention
这对长 prompt、多相似请求的场景非常关键。
总结 KV 设计:vLLM 基本不挪动 KV 数据,只是在改 token 到 block 的映射关系。
这就是 Paged KV Cache 的核心思想。
具体流程:
在调度阶段,系统不仅要考虑算力,还要考虑显存。vLLM 将 KV Cache 设计成分页管理的形式,而不是为每个请求分配一整块连续显存。
具体来说,KV Cache 被划分为大量固定大小的 block,由一个全局的 block pool 管理。每个序列在不同阶段需要占用一定数量的 block,这些 block 的分配和回收由 BlockSpaceManager 统一管理。
在 Scheduler 决定一个序列能否参与本轮计算之前,会先检查当前可用的 KV block 是否足够。如果显存资源不足,该序列即使在算力上可以执行,也会被延迟调度,从而避免 OOM。这意味着调度器本质上同时在管理“计算资源队列”和“显存资源队列”。
此外,vLLM 还支持 prefix caching。如果一个新请求的前缀与某个已有序列完全一致,系统可以直接复用已有的 KV blocks,而无需重新计算那部分 attention。这种复用对于长 prompt 或高相似度请求场景尤为重要。
调度完成后,Scheduler 会生成一个调度结果对象,其中包含本轮需要参与计算的所有序列、它们的 KV block 映射关系,以及本轮属于 prefill 还是 decode 阶段。
模型执行
当 Scheduler 决定好这一轮要算哪些 token 后,会生成一个执行计划,然后:
Executor.execute_model()→ Worker.execute_model()→ ModelRunner.execute_model()
接下来就是标准流程:
-
根据 block mapping 准备 KV -
调模型 forward -
得到 logits -
采样下一个 token
它的优势在于:
GPU 几乎每一步都被调度系统喂得很满。
具体流程:
调度结果生成后,EngineCore 会调用 Executor.execute_model,把本轮的执行计划发送给底层的 Worker 进程。
每个 Worker 对应一组 GPU 资源,内部包含 ModelRunner 等组件。Worker 首先根据调度结果中的 block 映射信息,准备好对应的 KV Cache 视图和 attention 输入数据。这一步的重点是把逻辑上的 token 序列,映射到物理显存中的 block 位置。
准备完成后,系统进入模型前向计算阶段。这里的流程就是标准的 Transformer 推理,包括 attention 计算、前馈网络计算以及最终的 logits 输出。随后根据采样策略,从 logits 中选出下一个 token。
从模型计算本身来看,这一部分并没有与传统推理框架有本质区别。vLLM 的性能优势并不主要来自更快的 forward,而是来自前面调度层面带来的高 GPU 利用率。
结果是怎么一路回来的
模型产出的 token 会:
-
放进 EngineCore 的 output_queue -
通过 ZMQ 发回 AsyncLLM -
AsyncLLM 解码 token → 文本 -
API Server 以流式方式返回给客户端
你在客户端看到的一小段小段输出,其实是:
GPU → Worker → EngineCore → ZMQ → AsyncLLM → API Server
一整套多进程流水线的产物。
具体流程
当 Worker 生成新的 token 后,会将结果封装成内部的输出结构并返回给 EngineCore。EngineCore 再通过 ZMQ 的输出通道,将结果发送回 AsyncLLM 所在的进程。
AsyncLLM 收到 token ids 后,会调用 tokenizer 的 decode 逻辑,将其转换为文本片段,并按流式方式逐步返回给 API Server。API Server 再通过 HTTP 流式响应,把这些文本发送给客户端。
用户在客户端看到的一段段实时输出,实际上是从 GPU 侧经过 Worker、EngineCore、进程间通信,再到 API Server 的完整流水线结果。
总结
从实现角度看,vLLM 的在线推理流程并不是简单的“调用模型 forward”。它更像是一套围绕 GPU 构建的请求调度与显存管理系统。模型执行只是其中的一个环节,而调度策略和 KV Cache 的分页管理才是支撑高吞吐的关键基础设施。
理解了这一整条链路,再回头看 vLLM 的各种优化策略,就会发现它更像一个小型操作系统,而不是单纯的推理库。
