 夜雨聆风
夜雨聆风





PDF 全文翻译,保留样式,大模型加持的全新方案,附核心代码
Claude 这份创建 Skills 指南非常有价值
但是学习起来有点低效,我要将其翻译成中文

四名选手参加(后面有 GTP-5.2-Codex 参赛)
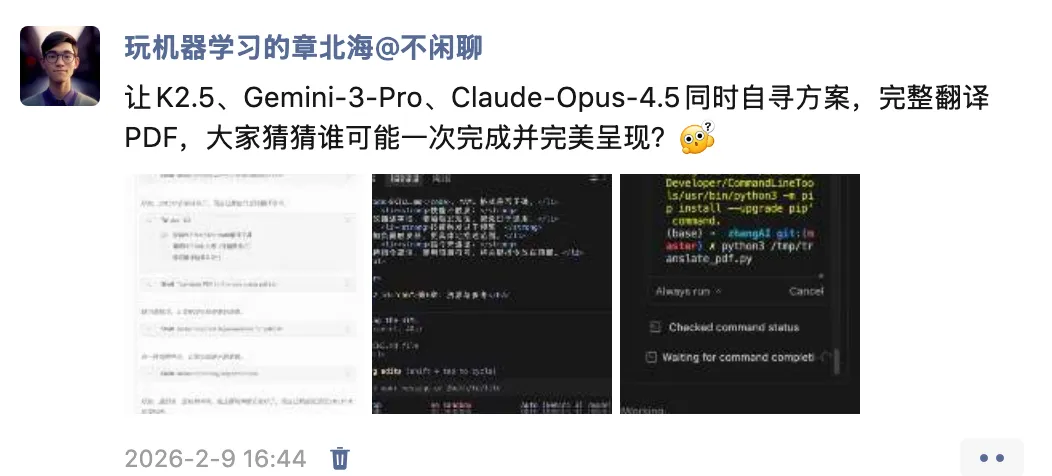
K2.5 其实中间找到了一个开源项目PDF2Zh,计划按要求实行翻译,但是部署时遇到了 bug,我有点不太喜欢成熟方案,太重了。K2.5 发现部署有麻烦后,也转为了下面方案,我没有让它继续
Gemini-3-Pro 和 Claude-Opus-4.5 不约而同偷懒,Gemini-3-Pro 选择了最简单的 PDF 抽取文字翻译后重构为结构清晰的 Markdown 文档,然后生成支持中文渲染的 HTML 页面,并利用 Google Chrome 的 Headless 打印成 PDF
Claude-Opus-4.5 选择了原始 PDF → pdf2docx 转 DOCX → 翻译 DOCX 内容 → docx2pdf 转回 PDF,感觉前者更省事儿一些。
我觉得挺好的,唯一缺点就是没有保留原始样式

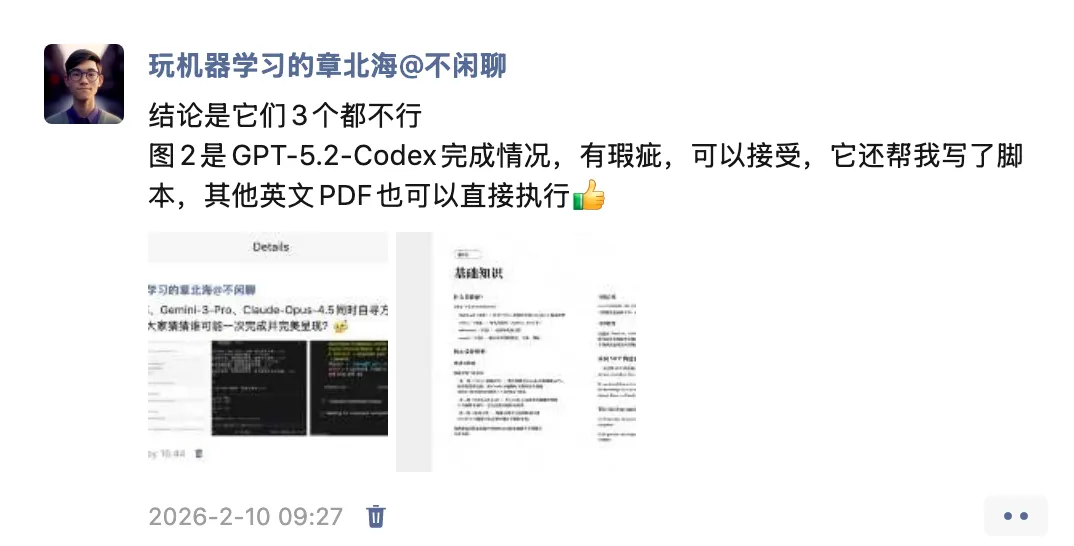
GPT-5.2-Codex 严格遵守的我的要求——保留样式
核心思路是“两阶段 + 缓存”:
-
文本抽取与翻译阶段
-
用 PyMuPDF 读取 PDF,每页提取文本块(bbox、字号、文本内容) -
调用模型 API 翻译文本块,按块 ID 存入翻译缓存 -
翻译缓存落盘,支持中断续跑
-
重新排版与导出阶段
-
把每一页先渲染成位图,避免字体嵌入导致的问号问题 -
在每个原文字块区域先画白底,彻底覆盖英文 -
按区域宽高自动缩放字号,回填中文文本 -
最后把所有页面合成为 PDF

这里只有一点瑕疵,就是文字白底,我尝试多次,它没有消除这个 bug
瑕不掩瑜


GPT-5.2-Codex 帮我写了 Python 脚本,其他英文 PDF 也可以直接执行
当然下一步也可以做成 Skills,这个下篇文章我再介绍
核心代码:
import jsonimport reimport fitzimport requestsfrom PIL import Image, ImageDraw, ImageFontdefextract_blocks(input_pdf): doc = fitz.open(str(input_pdf)) blocks = []for p in range(len(doc)): d = doc[p].get_text("dict")for b in d.get("blocks", []):if b.get("type") != 0:continue lines, sizes = [], []for line in b.get("lines", []): spans = line.get("spans", []) t = "".join(s.get("text", "") for s in spans)if t.strip(): lines.append(t)for s in spans:if"size"in s: sizes.append(s["size"]) text = "\n".join(lines).strip()ifnot text:continue blocks.append({"page": p,"bbox": b.get("bbox"),"text": text,"font_size": sizes[len(sizes)//2] if sizes else10 })return blocksdefcall_translate(api_base, model, api_key, items): payload = {"model": model,"messages": [ {"role": "system", "content": "Translate English to Simplified Chinese. Keep line breaks. Return JSON."}, {"role": "user", "content": json.dumps({"items": items}, ensure_ascii=False)}, ],"temperature": 0.2,"response_format": {"type": "json_object"}, } headers = {"Authorization": f"Bearer {api_key}", "Content-Type": "application/json"} r = requests.post(f"{api_base.rstrip('/')}/chat/completions", json=payload, headers=headers, timeout=120) r.raise_for_status() content = r.json()["choices"][0]["message"]["content"] m = re.search(r"\{.*\}\s*$", content, re.S)if m: content = m.group(0)return json.loads(content)["items"]deftranslate_blocks(blocks, api_base, model, api_key, batch_size=8): cache = {} pending = [(i, b["text"]) for i, b in enumerate(blocks)]for i in range(0, len(pending), batch_size): batch = pending[i:i+batch_size] items = [{"id": idx, "text": txt} for idx, txt in batch] translated = call_translate(api_base, model, api_key, items)for it in translated: cache[int(it["id"])] = it["text"]return cachedefbuild_pdf(input_pdf, output_pdf, blocks, translations, fontfile, dpi=200, min_font_size=3): doc = fitz.open(str(input_pdf)) scale = dpi / 72.0 font_cache = {}defget_font(size): key = int(size * scale)if key notin font_cache: font_cache[key] = ImageFont.truetype(fontfile, key)return font_cache[key] pages = []for p in range(len(doc)): pix = doc[p].get_pixmap(dpi=dpi, alpha=False) img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples) draw = ImageDraw.Draw(img)for idx, b in enumerate(blocks):if b["page"] != p:continue rect = fitz.Rect(b["bbox"]) x0, y0, x1, y1 = rect.x0*scale, rect.y0*scale, rect.x1*scale, rect.y1*scale# 覆盖英文 + 去灰条 draw.rectangle([x0, y0, x1, y1], fill=(255, 255, 255)) text = translations.get(idx, b["text"]).replace("\t", " ") size = max(float(b.get("font_size") or10), min_font_size) font = get_font(size)# 简化版直接写入(完整版里有自动缩放和换行) draw.text((x0, y0), text, font=font, fill=(0, 0, 0)) pages.append(img) first, rest = pages[0], pages[1:] first.save(str(output_pdf), "PDF", save_all=True, append_images=rest, resolution=dpi)使用方法
环境准备
安装依赖:
python3 -m pip install pymupdf pillow requests配置 API Key(示例):
export SILICONFLOW_API_KEY="YOUR_API_KEY"可选配置:
export SILICONFLOW_API_BASE="https://api.siliconflow.cn/v1"export SILICONFLOW_MODEL="MiniMaxAI/MiniMax-M2"最简命令
python3 -B /Users/zz/Library/Mobile\ Documents/iCloud~md~obsidian/Documents/zhangAI/tmp/pdfs/translate_pdf.py \ --input-pdf /absolute/path/to/source.pdf常用命令(指定输出与缓存目录)
python3 -B /Users/zz/Library/Mobile\ Documents/iCloud~md~obsidian/Documents/zhangAI/tmp/pdfs/translate_pdf.py \ --input-pdf /absolute/path/to/source.pdf \ --output-pdf /absolute/path/to/source-zh.pdf \ --work-dir /absolute/path/to/tmp/pdfs指定中文字体(推荐)
python3 -B /Users/zz/Library/Mobile\ Documents/iCloud~md~obsidian/Documents/zhangAI/tmp/pdfs/translate_pdf.py \ --input-pdf /absolute/path/to/source.pdf \ --font /System/Library/Fonts/Supplemental/Songti.ttc常见问题
-
看到问号或乱码
-
原因:字体不支持中文。 -
处理:使用 --font指定可用 CJK 字体。
-
部分文本太小或挤压
-
原因:中文长度通常大于英文,原块高度不足。 -
处理:提高 --dpi或调整--min-font-size。
-
重跑很慢
-
原因:重新翻译全部文本。 -
处理:保留 <stem>.translations.json,脚本会自动续跑。
-
英文没有完全隐藏
-
处理:当前脚本已对文本块区域强制白底覆盖;若个别英文仍存在,通常是未被识别为文本块(例如图像里的文字)。

