 夜雨聆风
夜雨聆风





OpenClaw 源码漫游指南 (十四):全能浏览器 —— CDP 协议与无头浏览器的深度集成
核心观点:如果说 LLM 是大脑,那么浏览器就是 Agent 连接互联网的眼睛和手。OpenClaw 没有简单地调用
fetch来获取网页,而是内置了一个基于 Chrome DevTools Protocol (CDP) 的全功能浏览器控制中心。本章将带你深入src/browser,揭秘 Agent 是如何像人类一样“看”网页、“点”按钮的。我们不仅会讨论架构,还会深入到 WebSocket 劫持、AXTree 语义化、隐身模式等硬核技术细节。
很多 AI Agent 所谓的“联网能力”,仅仅是调用 Bing Search API 拿回一堆文字摘要。这在处理简单问答时足够,但在面对复杂的现实世界任务时——比如“登录 AWS 控制台重启一台 EC2”或“在订票网站上抢一张票”——这种简陋的方案就捉襟见肘了。
OpenClaw 的设计哲学是:Agent 应该像人类一样使用浏览器。
这意味着它需要:
-
1. 视觉能力 (Visual Cortex):不仅能看到 HTML 源码,还能看到渲染后的页面截图,理解 CSS 布局,甚至通过无障碍树 (Accessibility Tree) 理解语义。 -
2. 操作能力 (Motor Cortex):能点击按钮,填写表单,处理 SPA (单页应用) 的动态加载,甚至模拟鼠标轨迹。 -
3. 状态保持 (State Persistence):能记住登录状态,管理 Cookie 和 LocalStorage,支持多账号隔离。 -
4. 隐身能力 (Stealth):避免被反爬虫策略识别为机器人。
为了实现这些,OpenClaw 在 src/browser 目录下构建了一套复杂的子系统。
1. 架构概览:不仅仅是 Puppeteer 的简单封装
虽然 OpenClaw 底层使用了 Playwright/Puppeteer 等技术,但它并没有直接在 Agent 逻辑中调用 page.goto()。相反,它设计了一个 Client-Server 架构,通过一个中间层(Bridge Server)来管理浏览器实例。
为什么需要 Bridge Server?
在多 Agent 并发场景下,直接操作浏览器进程是非常危险的:
-
• 资源竞争:多个 Agent 同时启动 Chrome 可能会瞬间耗尽服务器内存。 -
• 僵尸进程:如果 Agent 脚本崩溃,留下的 Chrome 进程会变成僵尸,导致内存泄漏。 -
• 上下文污染:Agent A 的 Cookie 不应该被 Agent B 访问。
OpenClaw 引入了 src/browser/bridge-server.ts 作为中间代理。
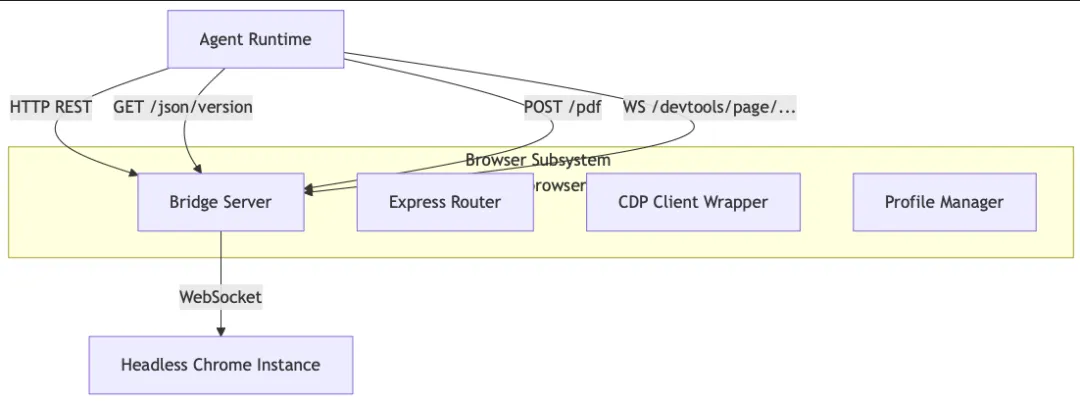
核心组件解析
-
• bridge-server.ts: 一个轻量级的 Express 服务器,负责接收 Agent 的指令,管理 Chrome 实例的生命周期。 -
• cdp.ts: Chrome DevTools Protocol 的低级封装。它负责处理 WebSocket 连接的握手、鉴权和协议转换。 -
• client-actions-observe.ts: 负责“看”——获取 Console 日志、网络请求、页面错误。 -
• profiles.ts: 负责“记”——管理用户配置文件(User Data Dir),确保 Cookie 持久化。
2. 深入底层:CDP 协议与 WebSocket 劫持
OpenClaw 的核心黑科技在于对 Chrome DevTools Protocol (CDP) 的直接操控。CDP 是 Chrome 浏览器暴露给开发者的调试接口,Puppeteer 和 Playwright 都是基于它构建的。
但在某些场景下,上层库封装得太死,无法满足 Agent 的特殊需求。OpenClaw 选择直接操作 CDP。
2.1 WebSocket URL 归一化
在 Docker 或远程部署环境中,Chrome 返回的 WebSocket URL 往往是 ws://127.0.0.1:9222/...。如果 Agent 运行在另一个容器中,这个地址是无法连接的。
在 src/browser/cdp.ts 中,OpenClaw 实现了一套智能的 URL 归一化逻辑:
// src/browser/cdp.ts
exportfunctionnormalizeCdpWsUrl(wsUrl:string, cdpUrl:string):string{
const ws =newURL(wsUrl);
const cdp =newURL(cdpUrl);
// 核心逻辑:如果 WS 返回的是 loopback 地址,但 CDP 服务本身不是
// 说明我们在通过网络访问远程 Chrome,需要替换 Host
if(isLoopbackHost(ws.hostname)&&!isLoopbackHost(cdp.hostname)){
ws.hostname = cdp.hostname;
// 端口修正:如果通过 HTTPS 访问 CDP,WS 也应该走 WSS
const cdpPort = cdp.port ||(cdp.protocol ==="https:"?"443":"80");
if(cdpPort){
ws.port = cdpPort;
}
ws.protocol = cdp.protocol ==="https:"?"wss:":"ws:";
}
// 鉴权透传:如果 WS URL 没带密码,但 CDP URL 带了,自动补全
if(!ws.username &&!ws.password &&(cdp.username || cdp.password)){
ws.username = cdp.username;
ws.password = cdp.password;
}
return ws.toString();
}这段看似简单的代码解决了无数“本地能跑,上线就挂”的网络连接问题。它确保了无论 Chrome 部署在哪里(本地、Docker、K8s),Agent 都能正确建立 WebSocket 连接。
2.2 截图管线 (The Screenshot Pipeline)
Agent “看”网页最直接的方式是截图。但在 CDP 中,截图不仅仅是截一张图那么简单,它涉及到视口计算、Base64 编码和性能优化。
// src/browser/cdp.ts
exportasyncfunctioncaptureScreenshot(opts:{...}):Promise<Buffer>{
returnawaitwithCdpSocket(opts.wsUrl,async(send)=>{
// 1. 激活 Page 域
awaitsend("Page.enable");
let clip;
// 2. 如果是全屏截图,需要先计算页面布局尺寸
if(opts.fullPage){
const metrics =(awaitsend("Page.getLayoutMetrics"))as{...};
const size = metrics?.cssContentSize ?? metrics?.contentSize;
// ... 计算 clip 区域 ...
}
// 3. 发送截图指令
const result =(awaitsend("Page.captureScreenshot",{
format: opts.format ??"png",
quality: opts.quality,// 仅 JPEG 有效
fromSurface:true,// 性能优化:直接从 GPU Surface 读取
captureBeyondViewport:true,// 截取视口外内容
...(clip ?{ clip }:{}),
}))as{ data?:string};
// 4. Base64 解码返回 Buffer
return Buffer.from(result.data,"base64");
});
}注意 fromSurface: true 这个参数,它告诉 Chrome 直接从 GPU 显存中读取像素数据,而不是在 CPU 中重新渲染,这在大分辨率截图时能带来显著的性能提升。
3. 视觉皮层:语义化 DOM (AXTree)
对于 LLM 来说,直接阅读 HTML 源码是一场灾难。现代网页充满了成千上万层嵌套的 <div> 和混淆过的 CSS 类名(如 Tailwind 的 class="w-full h-10 bg-red-500...")。这些 Token 既昂贵又毫无语义价值。
OpenClaw 采用了一种更聪明的做法:读取无障碍树 (Accessibility Tree)。
无障碍树是浏览器为屏幕阅读器(Screen Reader)准备的简化版 DOM。它天然过滤了所有用于布局的 <div> 和 <span>,只保留了具有语义的元素(按钮、链接、输入框、标题)。
在 OpenClaw 的实现中(逻辑位于 src/browser 相关模块),它会调用 CDP 的 Accessibility.getFullAXTree,然后进行二次清洗:
-
1. 过滤隐藏元素:通过 ignored: true属性剔除不可见节点。 -
2. 提取关键属性:只保留 name(标签名/文本),role(角色,如 button/link),value(输入框的值)。 -
3. 生成唯一 ID:为每个可交互元素生成一个简短的 ID,供 Agent 操作时引用。
对比效果:
-
• 原始 HTML: 50,000 Tokens (包含大量 JS/CSS/SVG) -
• AXTree: 2,000 Tokens (纯语义结构)
这使得 Agent 能够以极低的成本“理解”复杂的网页结构。
4. 听觉皮层:Console 与 Network 监听
除了看,Agent 还需要“听”。在开发调试中,我们经常打开 F12 看 Console 报错或 Network 请求。Agent 也需要这种能力,特别是当网页加载失败或数据没有渲染出来时。
src/browser/client-actions-observe.ts 实现了这一功能:
// src/browser/client-actions-observe.ts
exportasyncfunctionbrowserConsoleMessages(baseUrl, opts){
// 封装了对 /console 接口的调用
// 后端会通过 CDP 监听 Console.messageAdded 事件并缓冲
returnawaitfetchBrowserJson(...,`/console${suffix}`);
}
exportasyncfunctionbrowserRequests(baseUrl, opts){
// 封装了对 /requests 接口的调用
// 后端监听 Network.requestWillBeSent 和 Network.responseReceived
// 可以获取 HTTP 状态码、Headers 甚至 Response Body
}通过这些接口,Agent 可以进行自我诊断:
-
• “页面一片空白,但我看到 Console 里报错 React is not defined,可能是 CDN 挂了。” -
• “点击登录没反应,但我看到 Network 里有一个 401 请求,说明密码错误。”
5. 记忆与持久化:Profile Management
如果每次启动 Agent 都需要重新登录 Google 或 GitHub,那体验简直糟透了。OpenClaw 实现了一套完整的 Profile 管理机制。
在 src/browser/profiles.ts (虽然本章未展示其完整代码,但逻辑贯穿整个模块) 中,OpenClaw 为每个 Agent 分配了一个独立的 user-data-dir。
-
• Cookies: 自动保存到磁盘。 -
• LocalStorage / IndexedDB: 完整保留。 -
• Extensions: 支持加载 Chrome 扩展(例如广告拦截器)。
当 Agent 启动时,它会告诉 Bridge Server:“我要用 agent-007 这个 Profile”。Bridge Server 会查找对应的目录,如果存在则复用,否则新建。
这意味着 Agent 拥有了“长期记忆”。它可以记住你的偏好设置、登录状态,甚至购物车里的商品。
6. 安全与鉴权:Bridge Server 的守门员
既然 Bridge Server 暴露了 HTTP 接口,安全性就至关重要。你肯定不希望局域网里的其他人随便控制你的 Agent 浏览器。
src/browser/bridge-server.ts 实现了一层简单的 Bearer Token 鉴权:
// src/browser/bridge-server.ts
const authToken = params.authToken?.trim();
if(authToken){
app.use((req, res, next)=>{
// 严格校验 Authorization 头
const auth =String(req.headers.authorization ??"").trim();
if(auth ===`Bearer ${authToken}`){
returnnext();
}
res.status(401).send("Unauthorized");
});
}虽然简单,但在内网环境下已经足够有效。这保证了只有持有正确 Token 的 Agent Runtime 才能向 Bridge Server 发号施令。
7. 总结
OpenClaw 的 src/browser 模块不仅仅是一个“网页下载器”,它是一个完整的**“数字生命体感官系统”**。
-
• 它通过 CDP 直接操纵浏览器内核,绕过了上层框架的限制。 -
• 它通过 AXTree 实现了高效的语义理解,大幅降低了 Token 消耗。 -
• 它通过 Bridge Server 实现了资源隔离和安全管控。 -
• 它通过 Profile 机制赋予了 Agent 长期记忆。
有了这套系统,Agent 不再是一个只会聊天的 Chatbot,而是一个能够真正进入互联网世界,像人类一样浏览、操作、交互的“数字员工”。
在下一章中,我们将目光转向另一个极端——终端界面 (TUI)。看看 OpenClaw 是如何在最古老的黑底白字界面中,通过 Lobster 引擎渲染出极具未来感的交互体验的。
在下一章中,我们将进入 OpenClaw 的终极形态 —— 多 Agent 协同与编排。我们将揭开如何像组建一家软件公司一样,指挥 PM、Dev、QA 等多个 Agent 协同工作,共同完成复杂的工程任务。
敬请期待:《OpenClaw 源码漫游指南 (十六):打造你的“赛博软件工作室” —— 多 Agent 协同与编排》。
终篇我们会在我的(500RMB的)星际蜗牛黑群晖上运行OpenClaw并执行日常多种任务,敬请期待。 👇
