 夜雨聆风
夜雨聆风





Gemini 3.0 Pro 批量传文件踩坑指南!10 篇 PDF 一次传,超长文档处理不卡壳
导语
News Today
一次性上传 10 篇 PDF 文献,结果提示 “文件过大,上传失败”;好不容易分两次传完,AI 却把两组文献的内容混为一谈,分析结果逻辑混乱;处理 3 万字的学位论文,传到一半卡住不动,刷新后又要重新上传;更崩溃的是,上传扫描版 PDF 后,AI 识别的文字全是乱码,根本无法分析…
作为科研人,批量上传文献、超长文档、多模态素材(图 / 文 / 视频)是高频需求,但很多人都因没掌握正确的上传方法,导致 “上传失败、识别错误、分析混乱”,白白浪费时间。
今天把 Gemini 3.0 Pro批量文件上传 超长文档处理的全套实操指南扒得明明白白,包括文件准备、分批次上传技巧、超长文档拆解方法,还总结了 8 个高频踩坑点和避坑方案,教你 10 篇 PDF 一次传成功,3 万字文档处理不卡壳,彻底解决文件上传的所有难题!
01
先划重点:Gemini 3.0 Pro 文件处理的核心规则
想要上传不踩坑,先摸清平台的底层规则,这 3 个核心限制和优势必须记牢,所有上传技巧都基于此:
文件格式支持:优先识别可编辑版 PDF/Word/TXT,图片版 / 扫描版 PDF 需提前转文字;支持图片(JPG/PNG)、视频(MP4/AVI),单视频时长建议≤3 小时;
大小与数量限制:单文件大小≤200MB,单次批量上传≤10 个文件(总 Token 不超 200 万),超出则会提示上传失败或处理卡顿;
上下文关联规则:同一会话中,按上传顺序识别文件关联,若分批次上传无明确标注,AI 会默认所有文件为同一主题,导致分析混乱。
02
实操第一步:文件预处理,从源头避免 90% 的问题
批量上传前的文件预处理是关键,这 3 步做对,能直接避免上传失败、识别乱码等问题,耗时 5 分钟,效率提升 10 倍:
1. 格式统一:优先转可编辑版,清理无效内容
扫描版 / 图片版 PDF:用 OCR 工具(如天若 OCR、WPS)转可编辑 PDF,转后检查文字识别准确率,修正乱码、错字;
可编辑 PDF/Word:删除无关内容(如页眉页脚、广告水印、空白页),避免 AI 识别冗余信息,占用 Token;
多模态素材:视频转 MP4 格式(分辨率 720P 即可),图片压缩至≤5MB / 张,保证清晰度的同时减少文件大小。
2. 分类命名:按 “主题 + 序号” 标注,避免关联混乱
批量上传的文件,按研究主题 / 类型分类,命名格式统一为「主题_序号_文件类型」,示例:
文献分析:肺癌免疫治疗_01_PDF、肺癌免疫治疗_02_PDF;
论文修改:硕士论文_引言_PDF、硕士论文_实验部分_PDF;
多模态素材:小鼠行为实验_01_视频、小鼠行为实验_02_图片。
3. 大小拆分:超 200MB 文件按内容拆解
单文件超 200MB(如 3 万字学位论文、超长实验视频),按内容模块拆分:
文档类:按章节拆分为多个小文档(每篇≤1 万字),标注 “XX 论文_第 1 章”“XX 论文_第 2 章”;
视频类:按实验时段拆分为多个短视频(每段≤30 分钟),标注 “XX 实验_0-30 分钟”“XX 实验_30-60 分钟”。
避坑点:别直接上传原始文件!尤其是导师发的带水印、多空白页的文献,和自己未整理的初稿,会大幅降低 AI 处理效率,甚至导致识别失败。
03
核心干货:3 类场景上传技巧,10 篇 PDF / 超长文档一次搞定
结合科研人高频的批量文献上传、超长文档处理、多模态素材上传3 类场景,整理了针对性的上传技巧,附实操步骤,照做就能成功:
1
场景 1:批量文献上传(≤10 篇 PDF)
一次上传,精准关联
适用场景:文献综述、批量文献分析,需 AI 识别多篇文献的关联,挖研究缺口 / 对比结论
实操步骤:
按「研究主题_序号」命名所有文献,确保格式为可编辑 PDF,单篇≤200MB;
单次选中所有文献(≤10 篇),一次性上传,不要分多次;
上传后立即发送指令,明确文件关联要求:“以下 10 篇为【肺癌免疫治疗】领域的核心文献,按上传顺序标注为文献 1 – 文献 10,请分析各文献的核心结论,对比研究差异,挖掘领域研究缺口”。
核心优势:一次上传能让 AI 识别完整的文献关联,避免分批次上传的上下文断裂,分析结果更连贯。
2
场景 2:超长文档处理(≥3 万字 / 超 200MB)
分章上传,标注衔接
适用场景:学位论文润色、标书修改、长篇报告分析,文档内容为同一主题,需按逻辑衔接处理
实操步骤:
按章节拆解为多个小文档,命名为「XX 论文_第 X 章」,单章≤1 万字;
按章节顺序分批次上传,每上传 1 章,发送一次衔接指令,示例:
上传第 1 章后:“这是【XX 硕士论文】的第 1 章(引言),请先梳理本章的核心研究背景和问题,为后续章节分析做铺垫”;
上传第 2 章后:“这是该论文的第 2 章(实验部分),结合上一章的研究背景,分析本章实验设计的合理性,关联研究问题”;
全部上传完成后,发送整合指令:“请结合已上传的第 1-6 章,对整篇论文进行逻辑梳理,指出各章节的衔接问题”。
核心优势:分批次上传避免 Token 超限,衔接指令让 AI 保留上下文记忆,确保整篇文档分析不脱节。
3
场景 3:多模态素材上传(图 / 文 / 视频混合)
按 “文 + 素材” 配对上传
适用场景:实验视频分析、图表结合论文解读、定性研究(访谈视频 + 文字稿),需 AI 关联多类型素材分析
实操步骤:
按「研究主题_序号_类型」命名所有素材,如「细胞实验_01_论文 PDF」「细胞实验_02_实验视频」「细胞实验_03_结果图 PNG」;
按 **“文字素材 + 配套多模态素材”** 配对上传,先传文字稿(论文 / 实验方案),再传对应的视频 / 图片;
上传后发送关联指令:“以下为【细胞凋亡实验】的配套素材:文字稿为实验方案,视频为实验过程,图片为实验结果图,请结合实验方案,分析视频中的实验操作规范性,关联结果图解读实验数据”。
核心优势:文字素材为 AI 提供分析框架,多模态素材补充细节,配对上传让 AI 的分析更精准,避免素材脱节。
04
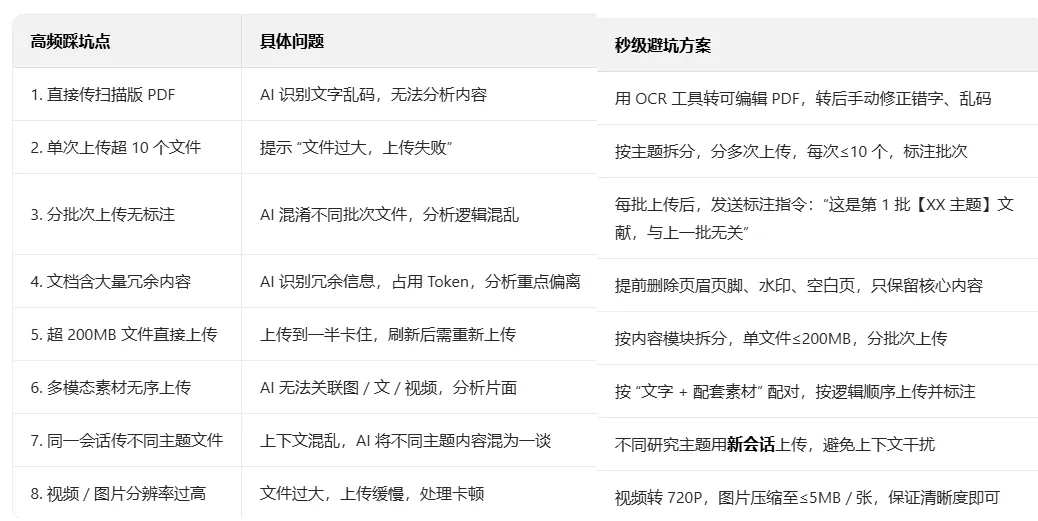
高频踩坑点:8 个最易犯的错误,附秒级避坑方案
整理了科研人上传文件时的 8 个高频踩坑点,每个坑都附具体的避坑方案,看完再也不用反复上传、返工:
05
进阶技巧:提升文件处理效率的 3 个小妙招
掌握基础上传方法后,结合这 3 个进阶技巧,能让 AI 的文件处理效率再提升 80%,分析结果更精准:
上传后补充核心需求:文件上传完成后,立即发送 “主题 + 需求 + 限制条件”指令,避免 AI 默认泛化分析,示例:“以下 10 篇为【乳腺癌靶向治疗】2024-2025 年的顶刊文献,仅分析实验研究类文献,排除综述,总结各文献的实验方法和核心结果”;
利用 “文件引用” 精准提问:多文件分析时,直接引用文件序号提问,让 AI 聚焦分析,示例:“请对比文献 3 和文献 7 的实验设计差异,分析哪种方法更适合临床转化”;
超长文档处理用 “分步指令”:润色 / 分析超长文档时,分步骤给指令,示例:“第一步:梳理本章的逻辑结构;第二步:润色语言,修正语法错误;第三步:按 GB/T 7714 规范标注参考文献”,避免 AI 信息过载。
06
最后避坑:这些细节别忽视,否则白忙活!
保存会话记录:批量文件处理完成后,保存会话链接,避免刷新后丢失文件和分析结果,方便后续继续提问;
关键内容手动核对:AI 识别的扫描版 PDF / 图片文字,需手动核对核心信息(如实验数据、文献作者),避免识别错误导致分析偏差;
大文件上传选网络稳定时段:上传超 100MB 的文件时,选择 WiFi 稳定的时段,避免网络中断导致上传失败,前功尽弃。
写在最后
2026/2/12
Gemini 3.0 Pro 的超长上下文和多模态处理能力,本就是为科研人批量处理文件、高效分析内容设计的,很多时候上传失败、处理卡顿,不是工具不行,而是我们没找对方法。
文件预处理的 5 分钟,能省去反复上传、返工的 1 小时;精准的标注和指令,能让 AI 的分析结果直接贴合科研需求。今天的这套上传指南,覆盖了所有科研高频场景,从预处理到上传技巧,再到避坑方案,照做就能让批量文件处理变轻松。
希望宝子们都能掌握这些技巧,告别上传的崩溃瞬间,让 Gemini 3.0 Pro 真正成为批量文件处理的 “神器”,把更多时间花在核心研究上!

点击蓝字 关注我们
Spring Festival




