 夜雨聆风
夜雨聆风





别啃PDF了!这个开源神器,能把学术论文变成“播客”讲给你听
想象一下这样的场景:深夜,你面对着一篇长达几十页、布满复杂公式和陌生术语的学术论文,眼睛发酸,大脑过载,进度条却只走了不到三分之一。😫 或者,你需要在通勤路上快速了解一份行业报告的核心观点,但手机屏幕太小,文档又太长,根本无从下手。
如果这时候,有人能把这篇论文或报告的核心内容,用像听播客或参加一场生动讲座的方式,“讲”给你听,是不是就轻松多了?今天要介绍的这个开源项目——PDF2Audio,就能实现这个梦想。它就像一个贴心的“知识转述官”,能把任何枯燥的PDF文档,转换成活泼的播客对话、清晰的讲座音频,甚至是精炼的总结。
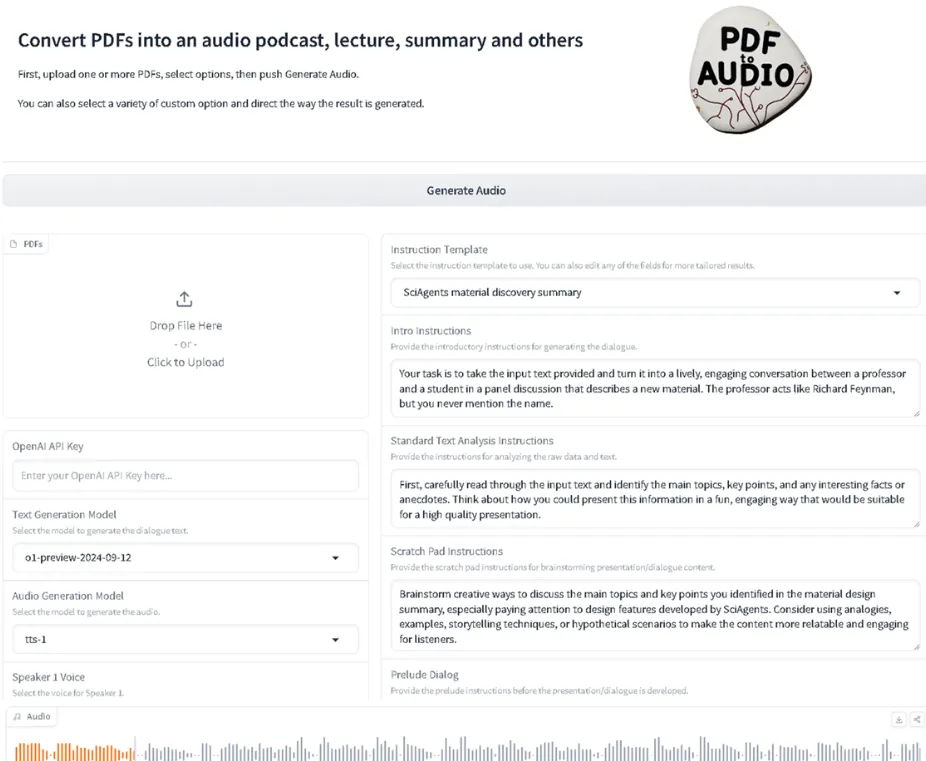
项目亮点
这个项目之所以令人惊喜,在于它将强大的AI能力封装成了一个极其简单易用的工具。它的核心魅力可以归结为以下几点:
🎙️ 一键转换,多种模式:你不再需要复杂的设置。上传PDF,选择你喜欢的输出模式(比如“播客”、“讲座”、“总结”),点击生成,剩下的就交给AI。它能将生硬的文字变成富有对话感和节奏感的音频内容。
🧠 理解,而不仅是朗读:它并非简单地“文本转语音”。其核心是利用了像GPT这样的大语言模型,先深度理解文档内容,提取关键主题、定义和有趣的事实,然后按照你选择的风格(如NPR风格播客)重新组织和演绎。这意味着你听到的是经过“消化”和“再创作”的精华,更容易吸收。
✏️ 支持迭代与精修:生成的第一版“草稿”不满意?没问题。你可以直接编辑AI生成的文字稿,或者给AI提供具体的修改意见(比如“这里讲得更生动一些”、“增加一个现实中的例子”),让它基于你的反馈重新生成,直到你满意为止。这就像拥有一个随时待命、任劳任怨的写作助理。
🌐 开箱即用,多途径访问:你既可以在本地电脑上安装运行,享受完全的掌控感和隐私性;也可以直接通过Hugging Face Spaces的在线网页版(https://huggingface.co/spaces/lamm-mit/PDF2Audio)快速体验,无需任何安装步骤,对新手极其友好。
解决什么痛点?
让我们通过两个更具体的故事,来看看PDF2Audio到底在解决什么问题。
故事一:研究生小王的“救星”小王的研究方向是计算材料学,每周需要阅读大量前沿论文。许多论文来自预印本网站arXiv,动辄几十页,充斥着复杂的图、表和公式。长时间盯着屏幕阅读让他疲惫不堪,效率低下。更头疼的是,有些论文的核心创新点隐藏在繁复的叙述中,需要反复琢磨才能领会。
后来,小王发现了PDF2Audio。他把需要精读的论文PDF拖进去,选择“讲座”模式。几分钟后,他戴上耳机,一边整理实验器材,一边听AI用清晰、有条理的方式,将论文的研究背景、方法、核心发现和创新点娓娓道来。AI还会特意解释那些专业术语。原本需要静坐两小时才能啃完的论文,现在在碎片时间里就掌握了概要,并且对重点印象深刻,极大提升了文献调研的效率。
故事二:市场经理李姐的“信息快餐”李姐每天需要快速浏览多份竞品分析报告和市场数据PDF,以便在晨会上给出见解。时间紧迫,她根本没有办法逐字阅读。
现在,她会把报告上传到PDF2Audio,选择“总结”模式。AI会迅速提取出报告中的关键数据、趋势判断和核心结论,生成一段精炼的摘要音频。在上班路上,李姐花10分钟听完,就能对报告了然于胸。她甚至可以利用“播客”模式,生成一份带有讨论色彩的音频,听起来就像两个行业专家在分析这份报告,让她能多角度理解内容。
手把手教程
看到这里,你是不是已经心动了?接下来,我们就手把手教你如何用上这个神器。这里提供两种方法:零门槛的在线体验和功能更完整的本地安装。
方法一:在线快速体验(最简单)
对于只是想尝鲜、或者没有编程基础的朋友,这是最推荐的方式。
-
打开你的浏览器,访问这个链接: https://huggingface.co/spaces/lamm-mit/PDF2Audio。 -
页面打开后,你会看到一个简洁的网页界面。在“Upload PDF files”区域,点击上传你的PDF文档。你可以一次上传多个。 -
在“Instruction Template”下拉菜单中,选择你想要的转换模式。比如“podcast”(播客)、“lecture”(讲座)或“summary”(总结)。 -
(可选)你可以在下方的文本框里,对AI的“创作”提出更具体的要求,比如“请用更通俗的语言解释量子计算概念”。 -
准备好之后,点击“Generate Audio”按钮。稍等片刻(时间取决于文档长度和AI的繁忙程度),下方就会显示出AI生成的文字稿和对应的音频播放器。 -
点击播放按钮,就可以收听你的专属“知识播客”了!如果对内容不满意,你可以在“Feedback/Edits”框里输入修改意见,然后再次点击生成,进行迭代优化。
方法二:本地安装运行(更灵活、私密)
如果你想更深入地使用,或者处理一些敏感的文档,在本地安装是个好选择。别担心,步骤也很清晰。
➤ 第一步:准备好“工作间”我们需要一个独立的Python环境,就像为这个项目单独准备一个干净的房间,避免和其他软件“打架”。推荐使用Conda来管理。
打开你的终端(Windows上是Command Prompt或PowerShell,Mac/Linux上是Terminal),依次输入以下命令:
conda create -n pdf2audio python=3.9这行命令创建了一个名叫pdf2audio的新环境。
conda activate pdf2audio这行命令进入这个新环境。成功后,你的命令行提示符前面通常会显示(pdf2audio)。
➤ 第二步:获取项目并安装依赖在(pdf2audio)环境下,继续操作:
git clone https://github.com/lamm-mit/PDF2Audio.gitcd PDF2Audiopip install -r requirements.txt这几行命令从GitHub上把项目代码“搬”到你的电脑里,并安装所有必需的软件库。
➤ 第三步:配置“钥匙”这个项目需要调用OpenAI的AI模型(比如GPT-4,GPT-3.5)和语音合成服务,所以你需要一把“钥匙”——API Key。
-
前往 OpenAI 官网注册/登录,获取你的API Key。
-
在
PDF2Audio项目文件夹里,创建一个新的文本文件,命名为.env(注意最前面有个点)。 -
用记事本或任何文本编辑器打开这个
.env文件,在里面输入:OPENAI_API_KEY=你的实际API密钥将
你的实际API密钥替换成你从OpenAI获取的那一串字符,然后保存文件。
➤ 第四步:启动应用,开始使用一切就绪后,在终端里运行:
python app.py你会看到几行日志输出,最后通常会告诉你一个本地网址,比如 http://127.0.0.1:7860。用浏览器打开这个链接,你就会看到和方法一里一样的操作界面了!现在你可以尽情使用,所有处理都在你的电脑上完成。
同类项目对比
市面上能将文档转为音频的工具不少,但侧重点各有不同。为了让你更清楚地了解PDF2Audio的定位和优势,我们把它和两类常见工具做个简单比较:
|
|
PDF2Audio | 传统TTS工具/浏览器插件 | 其他AI摘要工具 |
|---|---|---|---|
| 核心功能 | 理解、重构、演绎
|
直接朗读
|
|
| 输出质量 |
|
|
|
| 交互性 | 支持迭代编辑
|
|
|
| 上手难度 |
|
|
|
| 最佳适用场景 | 深度学习、知识吸收
|
快速“听”完
|
快速抓取要点
|
| 生态/扩展性 |
|
|
|
简单来说,如果你只是想“听”完一篇小说或新闻,传统TTS工具就够了。如果你只想看一段摘要,很多AI工具都能做到。但如果你想真正“消化”一篇艰深的学术论文、技术报告或商业文档,希望它以一种生动、结构化、易于记忆的方式进入你的大脑,那么PDF2Audio提供的“理解后转述”的能力,是目前其他工具难以替代的。
它把从“阅读”到“理解”这个最耗脑力的环节,外包给了AI,让你可以专注于更高层次的思考、联想和创新。在这个信息过载的时代,这或许是我们提升学习与工作效率的一次重要进化。
