 夜雨聆风
夜雨聆风





架构师的文档修养:用ADR(Architecture Decision Records)记录关键技术决策
你好,我是 Howell。
你们技术团队是否有自己的 Wiki 文档?是否记录架构演变历史和决策记录?接下来要谈一个让所有接盘侠(包括未来的你自己)都痛哭流涕的话题——架构决策文档。
1. 开篇:代码里的“考古学”悲剧
你有没有经历过这种场景?
你刚入职一家公司,接手了一个核心交易系统。你发现代码里有一个极其诡异的设计:所有的金额计算没有用 BigDecimal,而是用了 long 存分,这倒也没啥,但所有的数据库字段全是 VARCHAR。
你跑去问团队里的老鸟:“为啥这核心金额字段是字符串?”老鸟吸了一口烟,眼神迷离:“三年前,架构师老王还在的时候,说是为了兼容某个老旧的COBOL外部接口,或者是为了防止精度丢失?反正老王走了,没人敢动。”
这就是典型的**“架构失忆症”**。
在软件工程中,代码只告诉了我们“它是这样做的(How)”,但永远不会告诉我们“为什么要这样做(Why)”。注释里很少写架构决策,Wiki 文档通常是三年前的,早就过时了。
当团队面临技术选型(比如选 RabbitMQ 还是 Kafka,选 Spring WebFlux 还是 Virtual Threads)时,往往是几次激烈的会议讨论,白板上画满了图。决定做完,大家散会写代码。
半年后,遇到性能瓶颈,你想改架构,却发现根本不知道当初为什么选了这个方案。是因为当时的技术限制?还是因为当时团队只会这个?还是因为某个政治原因?
这时候,你需要的是 ADR(Architecture Decision Records,架构决策记录)。
它不是那种几百页没人看的“软件架构说明书”,它是轻量级、跟随代码库、开发者友好的决策快照。今天,我们就来聊聊架构师的这项核心修养。
2. 正文解析:什么是 ADR 及其核心价值
ADR 是一种轻量级的文档格式,用于捕获重要的架构决策及其上下文和后果。
一个标准的 ADR 包含以下核心要素:
-
1. 标题:简短描述决策(如:ADR-001 使用 Java 21 虚拟线程替代 WebFlux)。 -
2. 状态:提议中、已通过、已废弃、已取代。 -
3. 背景(Context):我们面临什么问题?有什么约束?(例如:高并发IO密集型,但团队不熟悉响应式编程)。 -
4. 决策(Decision):我们决定做什么。 -
5. 后果(Consequences):决策带来的好处(Good)和坏处(Bad)。记住,所有架构决策都是Trade-off(权衡),没有完美的方案。
2.1 为什么要跟随代码库(Git)?
我见过太多公司把架构文档写在 Confluence、飞书文档或者 Word 里。结果就是:代码在演进,文档在腐烂。
ADR 的最佳实践是放在项目根目录的 /doc/adr 文件夹下,用 Markdown 编写,随 Git 提交。这样,代码回滚,决策记录也回滚;代码分支,决策也分支。Pull Request 时,架构决策也是 Code Review 的一部分。
我们先看一个 ADR 的生命周期图:
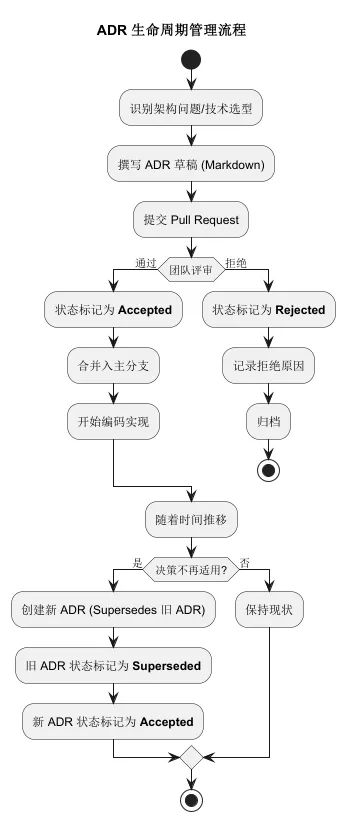
3. 实战案例:六个关键决策场景与 Java 21 代码落地
光说不练假把式。作为 Java 架构师,我用 6 个真实的生产环境场景,演示如何用 ADR 记录决策,并配合 Java 21/Spring Boot 3 的代码说明。
案例一:ADR-001 选择 Java 21 虚拟线程处理高并发 IO
背景:我们的网关服务需要处理海量并发 HTTP 请求。之前的方案是 Spring WebFlux(Reactor),但团队反馈响应式编程调试极其困难,堆栈信息不可读,开发效率低。
决策:使用 Spring Boot 3.2+ 搭配 Java 21 虚拟线程(Project Loom),抛弃 WebFlux,回归 Servlet 阻塞式编程模型。
代码落地:在 Spring Boot 3 中开启虚拟线程非常简单。
// application.ymlspring: threads: virtual: enabled: true或者自定义 Executor(如果你需要更细粒度的控制):
package com.howell.architecture.config;import org.springframework.boot.web.embedded.tomcat.TomcatProtocolHandlerCustomizer;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.concurrent.Executors;@Configurationpublic class VirtualThreadConfig { // 这是一个关键决策的落地代码 // 运行结果:Tomcat 将使用虚拟线程处理每个请求, // 吞吐量在 IO 密集型场景下大幅提升,且保留了传统的同步编程模型。 @Bean public TomcatProtocolHandlerCustomizer<?> protocolHandlerVirtualThreadExecutorCustomizer() { return protocolHandler -> { protocolHandler.setExecutor(Executors.newVirtualThreadPerTaskExecutor()); }; }}后果记录:
-
• ✅ Good: 开发心智负担低,堆栈清晰,吞吐量接近 Reactive。 -
• ❌ Bad: 需要确保依赖库没有严重的 synchronized块阻塞(Pinning 问题),需要升级大量中间件驱动。
案例二:ADR-002 使用 Java Record 承载 DTO 与不可变数据
背景:项目中充斥着大量的 Lombok @Data 注解,导致数据在传递过程中被随意修改,引发了线程安全问题和逻辑混乱。
决策:所有内部模块交互的 DTO(Data Transfer Object)强制使用 Java 16+ 引入的 record 关键字。
代码落地:
package com.howell.architecture.dto;import java.time.LocalDateTime;// 这是一个关键决策:使用 Record 定义不可变数据载体// 运行结果:自动生成构造器、getter、equals、hashCode、toString。// 且字段默认 final,无法被修改,保证了数据流转的安全性。public record UserTransactionEvent( String transactionId, String userId, long amountInCents, LocalDateTime timestamp, TransactionType type) { // 紧凑构造器进行校验 public UserTransactionEvent { if (amountInCents < 0) { throw new IllegalArgumentException("金额不能为负数"); } }}enum TransactionType { DEPOSIT, WITHDRAW }后果记录:
-
• ✅ Good: 线程安全,代码简洁,序列化性能好。 -
• ❌ Bad: 部分老旧的序列化框架(如某些版本的 Fastjson)支持不完善,需升级 Jackson。
案例三:ADR-003 模块化单体(Modulith)替代微服务起步
背景:新业务线刚起步,业务边界模糊。直接上微服务会导致分布式事务泛滥,运维成本过高。
决策:采用 Spring Modulith 构建“模块化单体”。在同一个 JVM 内通过 ApplicationEvent 解耦模块,保留未来拆分微服务的能力。
代码落地:
package com.howell.architecture.order;import org.springframework.modulith.ApplicationModuleListener;import org.springframework.stereotype.Component;import org.slf4j.Logger;import org.slf4j.LoggerFactory;@Componentpublic class InventoryListener { private static final Logger log = LoggerFactory.getLogger(InventoryListener.class); // 关键决策:模块间通信通过事件,而不是直接的方法调用 // 运行结果:当订单模块发布 OrderPlacedEvent 时,库存模块异步或同步响应。 // Spring Modulith 会强制检查模块间的依赖可视性。 @ApplicationModuleListener public void on(OrderPlacedEvent event) { log.info("接收到订单事件,准备扣减库存: {}", event.orderId()); // 业务逻辑... }}// 定义在 order 包下的事件record OrderPlacedEvent(String orderId) {}后果记录:
-
• ✅ Good: 部署简单,无网络开销,重构边界容易。 -
• ❌ Bad: 代码库庞大,编译时间变长。
案例四:ADR-004 使用 JdbcClient 替代复杂的 ORM
背景:项目中存在大量复杂的报表查询,JPA/Hibernate 生成的 SQL 难以优化,MyBatis XML 维护繁琐。
决策:对于复杂查询和报表模块,使用 Spring 6.1 引入的 JdbcClient(Fluent API),放弃 MyBatis。
代码落地:
package com.howell.architecture.repository;import org.springframework.jdbc.core.simple.JdbcClient;import org.springframework.stereotype.Repository;import java.util.List;@Repositorypublic class ReportRepository { private final JdbcClient jdbcClient; public ReportRepository(JdbcClient jdbcClient) { this.jdbcClient = jdbcClient; } // 关键决策:使用流式 API 编写原生 SQL // 运行结果:直观的 SQL 控制,自动映射到 Record,性能极致。 public List<DailyReport> getDailyReports(String date) { return jdbcClient.sql("SELECT category, SUM(amount) as total FROM transactions WHERE tx_date = :date GROUP BY category") .param("date", date) .query(DailyReport.class) .list(); }}record DailyReport(String category, long total) {}后果记录:
-
• ✅ Good: SQL 可控,无缓存黑盒,启动速度快。 -
• ❌ Bad: 失去了 JPA 的级联更新和脏检查功能(但这正是我们想要的,显式控制)。
案例五:ADR-005 统一异常处理与 RFC 7807 标准
背景:前后端联调时,异常格式五花八门,有的返回 HTTP 200 + code: 500,有的直接抛堆栈。
决策:全站采用 RFC 7807 (Problem Details for HTTP APIs) 标准,并利用 Spring Boot 3 的 ErrorResponse 接口。
代码落地:
package com.howell.architecture.exception;import org.springframework.http.HttpStatus;import org.springframework.http.ProblemDetail;import org.springframework.web.bind.annotation.ExceptionHandler;import org.springframework.web.bind.annotation.RestControllerAdvice;import java.net.URI;@RestControllerAdvicepublic class GlobalExceptionHandler { // 关键决策:标准化错误返回 // 运行结果:前端收到标准的 JSON 格式,包含 type, title, status, detail, instance @ExceptionHandler(IllegalArgumentException.class) public ProblemDetail handleArgumentError(IllegalArgumentException e) { ProblemDetail problem = ProblemDetail.forStatusAndDetail( HttpStatus.BAD_REQUEST, e.getMessage() ); problem.setTitle("参数校验失败"); problem.setType(URI.create("https://api.howell.com/errors/bad-request")); problem.setProperty("timestamp", System.currentTimeMillis()); // 扩展字段 return problem; }}后果记录:
-
• ✅ Good: 符合国际标准,利于 API 网关统一拦截监控。 -
• ❌ Bad: 需要前端修改统一拦截器适配新格式。
案例六:ADR-006 缓存一致性策略 – 旁路缓存(Cache Aside)
背景:用户中心数据频繁读取,但偶尔修改。之前使用了 @Cacheable 注解,但出现过数据库回滚而缓存未清除的脏数据问题。
决策:放弃 Spring Cache 注解的“黑盒”模式,手动实现 Cache Aside 模式,并引入“延迟双删”或“Binlog 订阅”机制(视一致性要求而定)。这里演示手动控制。
代码落地:
package com.howell.architecture.service;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.stereotype.Service;@Servicepublic class UserProfileService { private final StringRedisTemplate redisTemplate; private final UserRepository userRepo; // ... 构造器注入 // 关键决策:显式控制缓存逻辑 // 运行结果:先更库,后删缓存。虽然有极低概率并发问题,但比注解更可控。 public void updateUserProfile(String userId, String newName) { // 1. 更新数据库 userRepo.updateName(userId, newName); // 2. 删除缓存 (Cache Aside Pattern) // 实际生产中可能需要配合消息队列进行重试删除 redisTemplate.delete("user:" + userId); }}后果记录:
-
• ✅ Good: 逻辑清晰,不再被 Spring Cache 的 AOP 坑(如内部调用失效)。 -
• ❌ Bad: 代码量增加,业务逻辑混杂了缓存逻辑。
4. 逻辑图解:ADR 决策树
为了让大家更直观地理解如何做决策,我们用 画一个关于“并发模型选择”的决策逻辑图。这是架构师脑子里的回路,现在我们把它具象化。
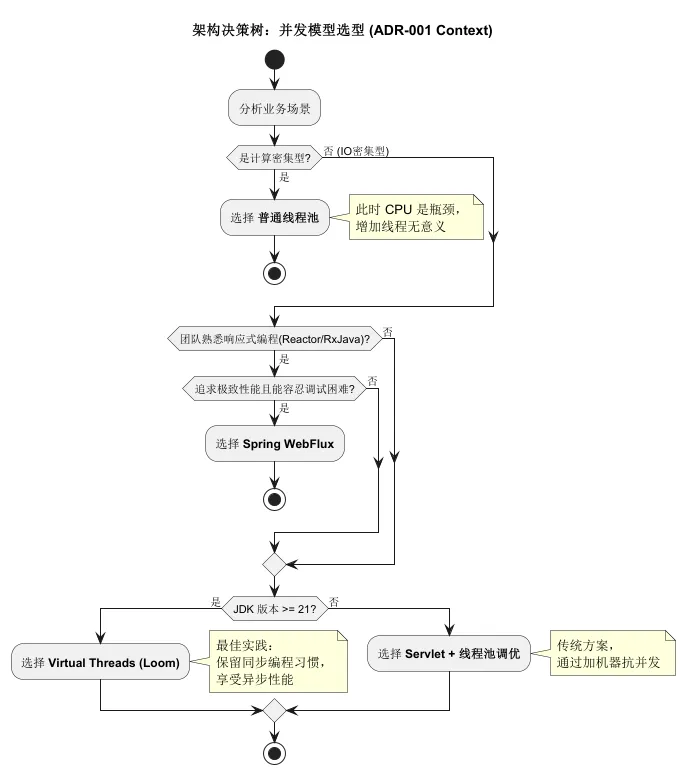
5. 思维拓展:架构师的“邪修”之道
讲完正统的 ADR,Howell 必须给你们讲点“邪修”版本(Dark Side of Architecture)。
在职场中,ADR 有时候不只是为了技术,更是为了**“甩锅”和“防御性架构”**。
-
1. 护身符模式:当业务方逼你上线一个明显有坑的功能(比如“双十一前一周重构核心链路”),你拦不住。这时候,写一个 ADR,详细列出 Consequences中的 Risks(风险):可能导致宕机、数据不一致。让老板在 Pull Request 上点 Approve。一旦炸雷,这个 ADR 就是你的免死金牌:“看,我当时明确警告过风险,是你们坚持要上的。” -
2. 反向卷王模式:有些架构师为了显得自己牛逼,引入了极其复杂的技术栈(比如 K8s + Service Mesh + GraphQL),但团队只有 5 个人。他在 ADR 里写满了“高可扩展性”、“云原生未来”。实际上,这是为了他自己的简历镀金。这种 ADR 我们称之为 RDD (Resume Driven Development,简历驱动开发)。兄弟们,千万别这么干,这是坑队友。 真正的架构师,是用最简单的方案解决最复杂的问题。 -
3. 常见误区: -
• 补作业:项目做完了才去写 ADR。那不叫决策记录,那叫回忆录。 -
• 写作文:一个 ADR 写了 5000 字。没人看的。ADR 必须短小精悍,直击痛点。
6. 总结
架构不是一蹴而就的设计,而是一连串决策的累积。
代码决定了系统现在的样子,而 ADR 记录了系统为什么长成这个样子。
对于想要进阶的 Java 开发者,我的建议是:
-
1. 从今天开始,在你的项目里建一个 /doc/adr目录。 -
2. 不要追求完美,哪怕只记录一个“为什么我们用 MySQL 而不是 PostgreSQL”,也是巨大的进步。 -
3. 用代码思维写文档,Markdown + Git,让文档活在代码库里。
Takeaway (今日要点):
一流的架构师,不仅能写出高性能的代码,更能通过清晰的文档(ADR),管理技术债务,统一团队认知,防止系统在人员更迭中发生“架构腐烂”。
