 夜雨聆风
夜雨聆风





买不起专业 De-Esser 消齿音插件?DAW自带与免费插件照样做得到(三)
齿音(sibilance),是人声录制过程中或多或少会出现的问题。并非所有音乐人都有足够的条件从录音环节的源头减少齿音,以及有足够的经济实力购买FabFilter Pro-DS、oeksound soothe2等专业且昂贵的专门插件,因此我编写了《“买不起”专业De-Esser插件?DAW自带与免费插件照样做得到!》系列教程,以免费/低成本的方式,使用DAW自带插件与免费插件实现去齿音(De-Essing)的目标。
在前两篇教程中,我先后介绍了利用压缩器与动态 EQ 组合、单独使用动态 EQ 以及多段压缩等方法来去除齿音,这些方案能够应对大多数常见的齿音问题。但在实际的混音工作中,我们总会遇到一些更为棘手的情况——比如齿音位置飘忽不定,在频谱上没有固定的集中区域;或者对于追求极致细节的混音师来说,需要更精细、更透明的处理方式。
本文作为本系列的第三篇教程,将带大家走进更“技术流”的去齿音世界。我会与大家探讨 FFT 动态均衡与频谱编辑这种近乎“极致精细”的处理方法,深入挖掘TDR Nova这款免费动态均衡器的进阶去齿音技巧,同时还会介绍一种基于侧链技术的实用方案:使用侧链噪声门(Gate)控制并行压缩。
本文依旧以REAPER 7.39为DAW来展开讲解,所涉及的方法同样具有普适性,你可以根据自己使用的 DAW 和插件进行灵活套用。
本系列教程传送门:
买不起专业De-Esser消齿音插件?DAW自带与免费插件照样做得到(一)》
买不起专业De-Esser消齿音插件?DAW自带与免费插件照样做得到(二)》
“极致精细”之一:使用ReaFIR进行FFT动态均衡
当齿音位置飘忽不定,在不同的词句中出现在不同的频率点,并且你有足够的时间进行精细处理时,FFT动态均衡的方案会是你的不二之选。这种方法能够实现对齿音频点的“精准打击”,最大限度地保留人声主体的质感。这套方案,在应对歌手唱法多变、台风姿态随性的演绎风格(如快节奏说唱)时非常有用。典型场景是:一些快节奏的说唱片段,其中的“s”“sh”等音在不同位置的频率分布差异较大。
REAPER自带的ReaFIR插件是一款强大的FFT均衡器,它能够通过实时的FFT分析来识别并处理特定的频率成分,非常适合用来对付那些难以捉摸的齿音。
由于截至发稿时市面上尚没有功能和用法与之相近的产品,如果你使用REAPER之外的DAW,你可以安装ReaPlug插件包中的ReaFIR独立版本(https://www.reaper.fm/reaplugs/,VST 2.4格式)。
原理
ReaFIR 去齿音的核心原理是“实时FFT相减”。简单来说,它会先分析一段纯齿音信号的频谱特征,建立一个“噪声profile”(噪声轮廓),然后在处理整段音频时,将与这个profile相匹配的频率成分进行衰减,从而实现只对齿音频点下手,而人声主体几乎不受影响的效果。
这种方式比传统的动态EQ或压缩器具有更高的频率分辨率,处理起来也更为透明。
实操
以一段人声片段为例,我们来演示ReaFIR的具体操作步骤。
(说唱唱词:不会再堕落我要突破自我一步一步过上自己理想的生活不会再沉默现在开始行动我的未来就由我自己来把握)
第一步:新建并行处理轨道
这里我们需要两个人声轨道:一个是“Vocal De-Ess Wet”,另一个是“Vocal De-ess Dry”。前者加载ReaFIR,后者则是原始的人声信号。由于截止发稿时,ReaFIR没有提供干湿信号混合功能,因此我们要以这种并行处理的方式来调节信号缩混。
第二步:加载 ReaFIR 插件
在“Vocal De-Ess Wet”音轨上插入REAPER自带的ReaFIR插件(显示为“ReaFir (FFT EQ+Dynamics Processor)”)。打开插件界面,可以看到其主要分为几个区域:Mode(模式)选择栏、频谱显示区以及各种参数调节区。
 图 1 ReaFIR 的初始界面
图 1 ReaFIR 的初始界面
第二步:设置模式与参数
在“Mode(模式)”下拉菜单中,选择“Subtract(相减)”模式。这是实现 FFT 相减去齿音的关键模式。
然后,勾选“Mode”右侧新出现的“Automatically build noise profile(自动建立噪声轮廓)”选项。这个选项会让插件在我们播放纯齿音片段时自动分析并建立齿音的频谱轮廓(profile)。
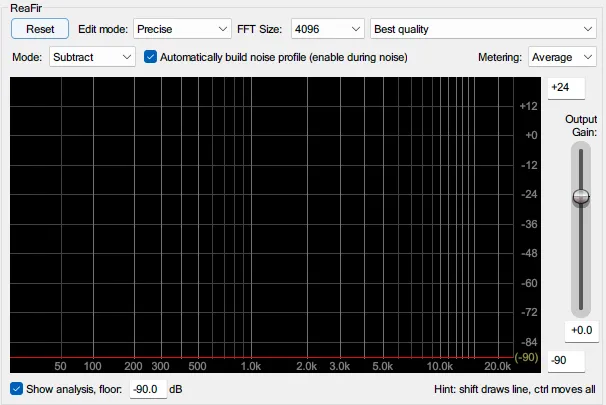 图 2 切换到“Subtract”模式后的界面。
图 2 切换到“Subtract”模式后的界面。
第三步:选择并播放纯齿音片段
在人声素材中,找到一小段只有纯齿音的部分(比如单独发“s”音的片段,确保这段片段中没有其他的人声主体内容)。精确选中这段片段,然后播放。
在播放的过程中,ReaFIR会自动分析这段齿音的频谱特征,并在频谱显示区以某种颜色(通常是红色)显示出建立的噪声轮廓。你可以观察到,频谱上那些齿音集中的频率点会被清晰地标记出来。
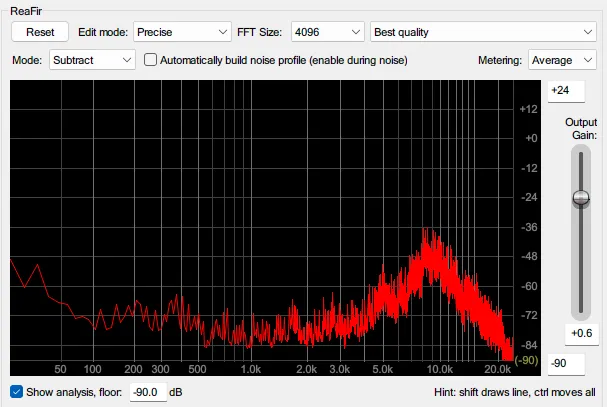 图 3 ReaFIR建立的噪声轮廓。
图 3 ReaFIR建立的噪声轮廓。
如果选择的片段不合适,可以点击插件的“Reset”按钮清空设置,然后重新找纯齿音片段。
第四步:调整Wet(湿信号)比例
建立好噪声轮廓后,停止播放纯齿音片段。此时,取消对“Automatically build noise profile” 选项的勾选,以免后续处理时噪声轮廓被误更新。
然后,调节“Vocal De-Ess Wet”的音量推子到合适的水平,随后播放整段人声素材,同时慢慢将“Vocal De-ess Dry”的推子从最底部开始逐渐向上推,边调节边聆听效果。两个推子配合,控制的是经过处理的信号比例。“Dry”音轨音量越小,去齿音的效果越强,但也有可能会对人声主体造成一定的影响,所以需要找到一个平衡点——既让齿音变得不刺耳,又不影响人声的自然质感。
效果展示
经过ReaFIR处理后的人声片段,齿音得到了有效的抑制,而且人声的主体部分几乎没有受到明显的影响。大家可以对比听听去齿音前后的效果。
注意事项
·选择的纯齿音片段质量非常关键。这段片段必须足够“纯净”,不能包含过多的人声主体或其他杂音,否则建立的噪声轮廓会不准确,导致处理效果变差,甚至会损伤人声主体。
·如果处理后的人声出现了“空洞感”或“闷感”,可能是“Vocal De-Ess Wet”信号过强,或者建立的轮廓包含了过多的人声主体频率。这时可以适当调节“Wet”和“Dry”两个音轨的音量,或者重新选择更纯净的齿音片段建立轮廓。
·对于一些极短的、瞬态极强的齿音,可能需要多次尝试建立轮廓,或者结合手动调节频谱显示区的衰减曲线来进行更精确的处理。
“极致精细”之二:频谱编辑
面对飘忽不定的齿音,除了使用ReaFIR这种FFT动态均衡器外,频谱编辑是另一种更为“可视化”和“纯手工”的精细去齿音方法。通过频谱编辑功能,你可以直接在频谱图上看到齿音的尖峰,并手动将其降低,实现点对点的精确处理。
一些主流DAW自带频谱编辑功能,例如Logic的Flex Pitch、Cubase的Spectralayers,以及REAPER的 Spectral Edit。
适用场景
这种方法非常适合处理配音、播客、旁白等对人声清晰度要求高,但齿音问题相对单一且出现频率不高的素材。典型的场景是配音,例如商业配音(广告、纪录片等)、游戏配音,特点是素材短小精致,且对质量要求极高。
对于录唱人声,由于齿音出现的频率高、变化快,一般不需要这么细抠,否则会耗费大量的时间。
实操(以REAPER的Spectral Edit 为例)
在这一节,我使用自己尝试录制的一段广告配音,来演示REAPER中频谱编辑的操作。
台词:“青花郎,赤水河左岸庄园酱酒”
第一步:开启频谱编辑视图
在REAPER中,选中需要处理的人声片段,右键点击片段,在弹出的菜单中找到“Spectral edits”,选中它,然后在子菜单里勾选“Always show spectrogram(始终显示频谱图)”选项。
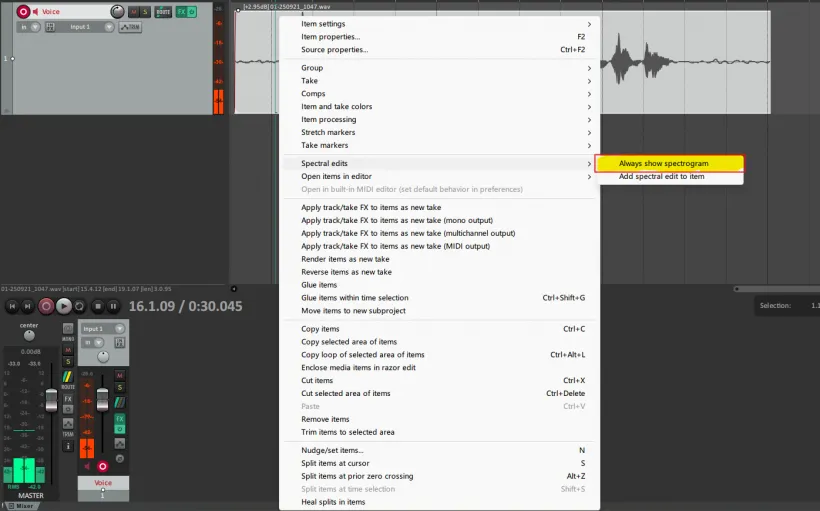 图 4 红框高亮的菜单项即为开启频谱图的选项。
图 4 红框高亮的菜单项即为开启频谱图的选项。
此时,片段会显示出频谱图,横轴代表时间,纵轴代表频率,颜色的深浅代表信号的强度。
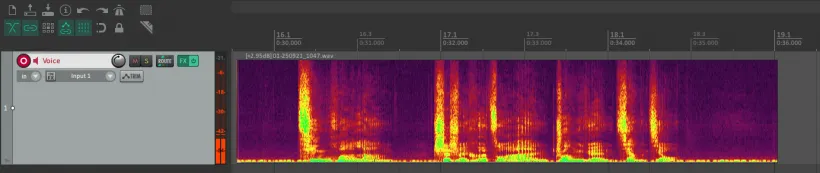 图 5 REAPER中开启频谱编辑后的视图
图 5 REAPER中开启频谱编辑后的视图
第二步:定位齿音区域
播放人声片段,观察频谱图,找到齿音出现时的尖峰区域。通常来说,齿音主要集中在4~8 kHz的频率范围内,在频谱图上表现为明亮的、短暂的尖峰。
放大频谱图,以便更清晰地观察这些齿音尖峰的位置和形态:
·你可以使用鼠标滚轮来放大或缩小时间范围;
·你可以纵向放大音轨视图(点击音轨视图纵向滚动条下方的加号图标),或者拖动音轨列表中当前音轨的下边界,纵向放大频率范围。
◆提示:为了更精细地定位齿音,你可以关闭DAW的“对齐到网格”功能,例如在REAPER中将工具栏上“磁铁”图标的开关关闭。
第三步:手动降低齿音尖峰
将时间光标移到齿音所在的位置,右键点击人声片段,依次选择“Spectral edits”→“Add spectral edits to item(添加频谱编辑窗)”。此时频谱视图中就会出现一个白色方框,附有各种控制按钮,这就是用于编辑频谱的工具——频谱编辑窗(spectral edit)。框住的频谱区域就是编辑的目标。
频谱编辑窗的基本操作如下:
·拖动白色方框四周或四个角落,可以调节编辑窗的大小。方框越宽,影响的时间范围越广;越高,则影响的频率范围越广。
·直接拖动白色方框内部,可以移动其位置。
·最靠右上角的旋钮,调节选中区域的增益水平。
调节频谱编辑窗,使其“框”注齿音尖峰的部分,通常对应频谱图中最明亮(乃至亮到“发绿”)的位置。操作时要注意,尽量只选中齿音尖峰部分,避免影响周围的人声频率成分。
然后,调节最靠右上角的旋钮,降低选中区域的增益。通常降低的范围是3~10 dB,你需要一边试听一边上下微调增益值,直到齿音不再过于尖锐。
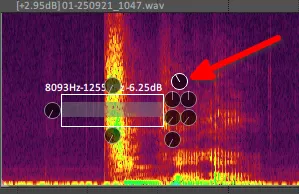 图 6 调节其中一处齿音尖峰的示意(“青花郎”的“青”字)。箭头指向的按钮即为调整选中频率增益的按钮。
图 6 调节其中一处齿音尖峰的示意(“青花郎”的“青”字)。箭头指向的按钮即为调整选中频率增益的按钮。
对于多个分散的齿音尖峰,需要添加多个频谱编辑窗,逐个进行处理。处理完成后,可以播放片段,聆听效果,根据需要进行进一步的微调。
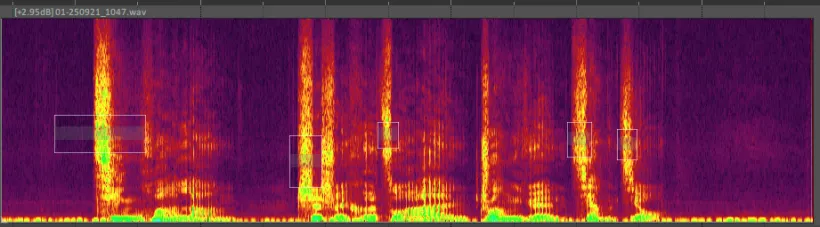 图 7 手动降低示例音频中所有明显齿音的操作示意。图中的白框即为频谱编辑窗(显示得不够明显,需要仔细观察)。
图 7 手动降低示例音频中所有明显齿音的操作示意。图中的白框即为频谱编辑窗(显示得不够明显,需要仔细观察)。
效果展示
经过频谱编辑处理后,那些明显的齿音尖峰被有效降低,人声听起来更加平滑。听听看是不是舒服多了:
其他软件的操作思路
·Logic的Flex Pitch:在Flex Pitch编辑界面中,切换到频谱视图,找到齿音对应的频谱峰值,使用相关工具进行衰减处理。
·Cubase 的 SpectralLayers:SpectraLayers提供了更强大的频谱分层编辑功能,可以将齿音所在的频谱层分离出来,单独进行处理,然后再与原始信号混合。
注意事项
·频谱编辑是一项非常耗时的工作,对于长篇的音频素材(例如听书、对谈等播客),需要权衡处理的精细度和时间成本。若时间成本过高,可优先考虑第一篇教程中的动态EQ。
·过度处理会导致人声变得不自然,出现“口齿不清”的感觉,甚至会出现音质损失的情况(就像是你收听低码率的“全损”音频那样)。因此,每次衰减的量不宜过大,3~10 dB是比较合适的范围,具体要根据实际听感来判断。
·在处理过程中,要反复切换聆听原始信号和处理后的信号,反复比对、查漏补缺,确保处理效果自然且有效。
TDR Nova进阶去齿音技巧
TDR Nova作为一款免费的动态均衡器,在去齿音方面有着出色的表现。在本系列第一篇教程中,我介绍了它的基本用法。当然,它在De-Ess上的潜力远不止于此,在本节中,我将深入探讨其进阶技巧,帮助你更精准、更自然地处理齿音问题。
若其他的动态均衡器有相应功能,这一章的技巧同样适用。
技巧一:细调与A/B对比
在使用 TDR Nova 去齿音时,参数的细微调整可能会对最终效果产生较大的影响。通过A/B对比功能,我们可以在两个不同的参数设置之间快速切换,比较不同参数设置下的效果,通过听觉判断,选出最自然的方案。
对于去齿音来说,主要关注的是齿音是否被有效抑制,同时人声的 “S” 音是否依然清晰自然,没有出现 “口齿不清”(lisp)的现象。
接下来开始实操,以一段流行歌曲的人声片段为例,其中包含一些明显的齿音。
第一道工序:加载 TDR Nova 并设置初始参数
在人声轨道上插入TDR Nova插件,找到齿音所在的核心频率(可参考前两篇教程中的扫频定位方法),例如5 kHz左右。设置一个合适的带宽(Q 值),确保只针对齿音区域进行处理。
第二道工序:设置 A、B 两套参数
点击 TDR Nova 界面顶部的“A B”按钮,创建两套参数设置。
若该按钮为灰色不可点击,则点击“A > B”按钮,先将A参数的设置复制一份到B参数,以激活“A B”按钮功能。
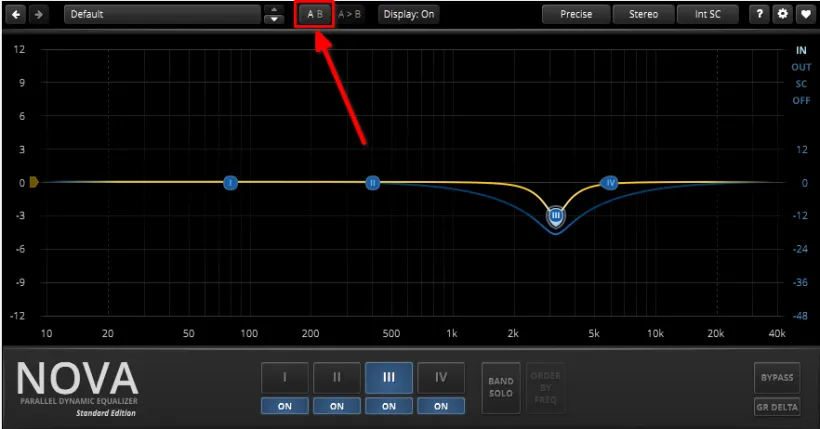 图 8 箭头指向的按钮就是切换A、B两套参数的按钮。
图 8 箭头指向的按钮就是切换A、B两套参数的按钮。
右边的“A>B”按钮作用是将A配置复制到B配置。
然后,按以下思路创建设置:
·A 方案:“Ratio”(比率)设为3:1,“Gain”(增益)设为-4 dB。这是一套相对温和的参数设置,对齿音的压缩力度较小。(注:部分动态EQ可能会把Gain写成“Range”。)
·B 方案:“Ratio”设为5:1,“Gain”设为-6 dB。这是一套压缩力度稍大的参数设置。
·两套方案采用相同的“Threshold”(阈值),以-20 dB为起点,一边试听一边调低,直到齿音刚好能触发动态EQ工作。
·两套方案均只使用TDR Nova的第3频段。
·其余设置保持默认值。
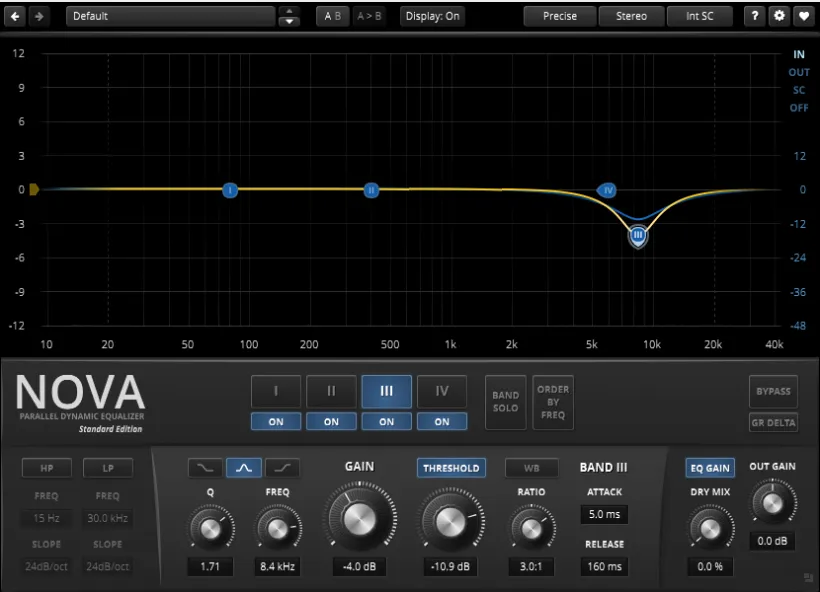
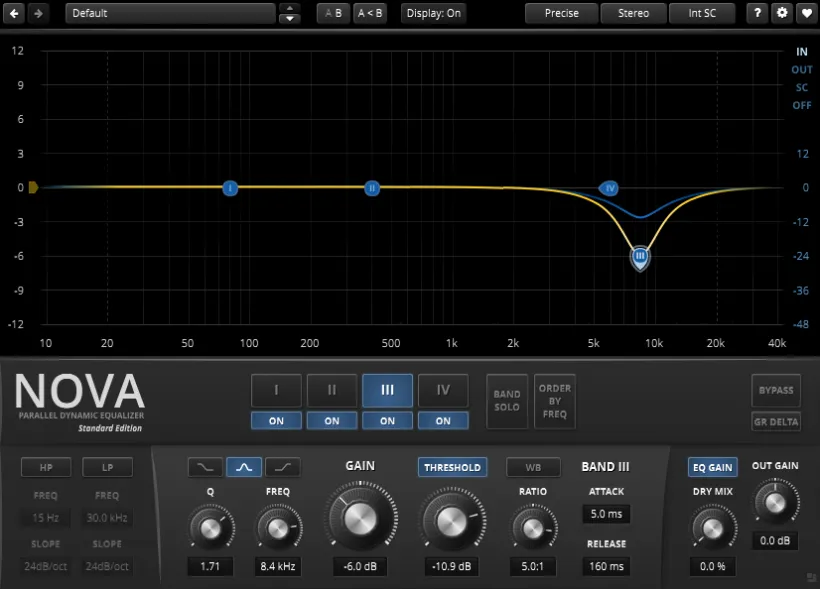 图 9 TDR Nova 中 A/B 参数设置界面示意。两张图分别对应A参数和B参数。(仅供示意)
图 9 TDR Nova 中 A/B 参数设置界面示意。两张图分别对应A参数和B参数。(仅供示意)
第三道工序:Loop播放并对比
选择包含齿音的乐句,开启Loop(循环)播放功能,反复聆听这段乐句。然后,不断点击“A B”按钮,在两套参数之间切换,仔细对比它们的效果。
我们遵循以下判断标准:
·齿音是否消失或变得不刺耳。
·“S”音是否依然清晰可辨,没有出现含糊不清的情况。
·整体人声的质感是否自然,没有因为处理而变得生硬或闷暗。
第四道工序:选择并微调
根据对比结果,选择更自然的一套参数作为基础。如果发现齿音消失但 “S” 音开始变得模糊(出现“口齿不清〔lisp〕”的现象),则需要把“Ratio”或“Gain”往回调整一点。例如,如果选择了B方案,但出现了“口齿不清”,可以将“Ratio”降低到4:1,或者将Gain调整为- 5 dB,再进行聆听判断。
效果展示
经过细调和A/B对比后,处理后的人声齿音得到有效控制,同时保持了自然的清晰度。
技巧二:多句检查与自动化
一首歌曲中的人声,齿音的强度可能会随着唱法、情绪的变化而有较大的差异。仅仅针对某一句或某一段进行处理,可能无法满足整首歌的需求。因此,需要进行多句检查,并根据情况使用自动化功能来实现动态的处理。
第一道工序:整首播放检查
将整首人声素材从头到尾播放一遍,仔细聆听每一句的齿音情况。注意那些齿音强度突然变大的乐句,以及在不同段落中齿音表现的差异。
第二道工序:全局参数调整
如果发现大部分乐句的齿音都比较强,或者处理效果不够理想,可以对TDR Nova的全局参数进行微调。例如,将“Threshold”(阈值)稍微再降1 dB,让压缩器更容易触发,以处理更强的齿音;或者把“Gain”放宽到-8 dB,大幅增加衰减量。
但要注意,全局参数的调整要适度,避免对那些齿音较弱的乐句造成过度处理。
第三道工序:局部处理与自动化
如果只有一两句的齿音特别刺耳,而全局调整又会影响其他乐句,可以采用以下两种方法:
① 单独切割片段处理:
在DAW中,将那几句齿音特别刺耳的片段单独切割出来,为这部分片段单独添加一个TDR Nova插件实例,并设置更激进的参数(如更高的“Ratio”,削弱幅度更大的“Gain”,或更低的“Threshold”),而其他部分保持原有的参数设置。
这种方法的优点是操作简单直接,针对性强;缺点是如果片段较多,会使轨道显得杂乱。
② 使用自动化:
另一种方法是为TDR Nova的“Threshold”或“Gain”参数编写自动化曲线。在齿音大的地方,降低“Threshold”(让压缩更易触发),或增大Gain参数削弱的幅度(增加衰减量),多压2 dB左右;在其余时间,让参数自动回到原来的温和值。
一般“Threshold”与Gain的自动化操作只需要“二选一”,根据实际情况来决定使用哪个参数。具体操作以你的DAW为准。
效果预期
通常,通过多句检查和自动化处理后,整首人声的齿音都得到了均匀、自然的控制,不容易出现局部过处理或处理不足的情况。
技巧三:多频带处理
免费版的TDR Nova最多可以同时使用4个动态频段。当齿音横跨多个频率区域(例如,同时在4 kHz和8 kHz附近都有明显的齿音尖峰)时,使用多频带处理比单频段处理更加透明和精准。辅以TDR Nova内置的频谱图,多频带去齿音操作方式更为直观。
原理和操作思路
每个动态频段可以独立设置“Threshold”、“Ratio”、“Attack”、“Release”等参数。对于不同频率区域的齿音,我们可以根据其强度和特性设置不同的处理参数,从而实现更具针对性的处理,避免单一频段处理时对某些频率难以有效处理的问题。
每个频段的操作方法与我在第一篇教程中介绍的方法相同,只需要注意几个细节:
·需要将频段的工作模式设为“Bell”(频段增益)。
·若两处齿音频率距离过近,两个工作频段的作用范围就可能相互干扰。可以通过适当调高Q值,收窄频段的工作范围。
技巧四:向上扩展
向上扩展是TDR Nova的一个特殊功能,通过将比率设为小于1:1(如 0.8:1),并将阈值设置为高于齿音峰值,可以在齿音之间“抬升”一点高频,让声音更加明亮。其作用类似于向上扩展器插件(upward expander)。
原理
通常情况下,压缩器的压缩比率大于1:1时是起到压缩(衰减)信号的作用;而当比率小于1:1时,则会起到扩展(提升)信号的作用。动态均衡器的“Ratio”参数与此类似。
将阈值设置为高于齿音峰值,意味着在齿音出现时(信号超过阈值),扩展器不工作;而在齿音之间(信号低于阈值),扩展器会对设定频段的信号进行提升,从而增加高频的亮度。
在处理一些高频略显暗淡的人声时,可以尝试使用向上扩展功能。
第一步:设置频段和阈值
选择一个合适的高频频段(如8~12 kHz),这个频段主要影响人声的亮度和空气感。如果频率大于10 kHz,你可以直接使用TDR Nova的第4个频段(该频段默认为高频增益的搁架式均衡〔high shelf〕)。
将“Threshold”设置为高于齿音的峰值,旨在确保只有在齿音不出现的时候,扩展功能才会生效。
第二步:设置压缩比率和增益
将“Ratio”设为0.8:1,这意味着当信号低于 “Threshold” 时,该频段的信号会被提升(提升量 = (1 – “Ratio”) × 信号与“Threshold”的差值)。同时,可以适当增加该频段的静态增益(Gain),进一步增强高频的明亮感。
第三步:调整启动时间和释放时间
“Attack”可以设置得稍长一些(如50 ms),避免快速的信号变化触发不必要的扩展。这与去齿音“Attack时间越短越好”的策略是完全相反的,需要特别注意。
“Release“设置为适中(如100 ms),确保扩展效果的平滑过渡。
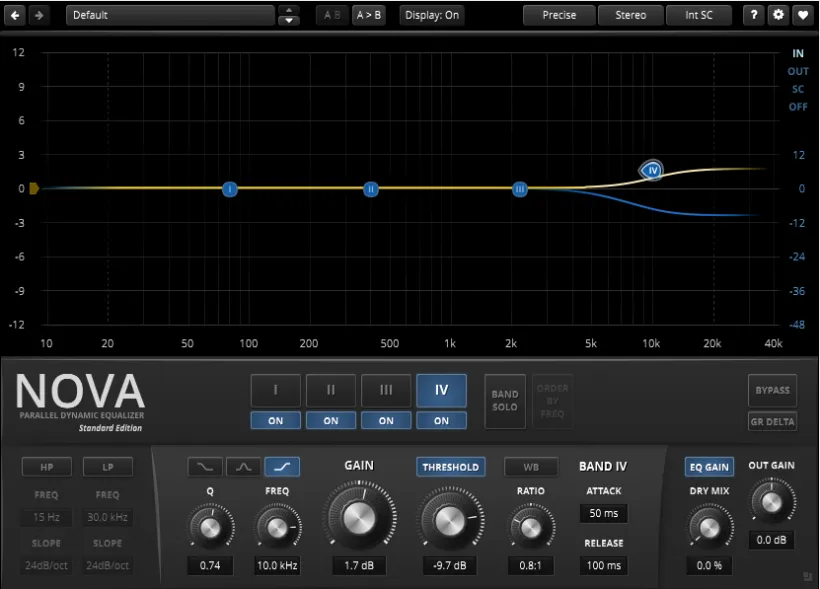 图 10 TDR Nova 向上扩展参数设置示意。
图 10 TDR Nova 向上扩展参数设置示意。
效果预期
经过向上扩展处理后,人声在齿音之间的高频部分得到了适当的提升,整体听起来更加明亮、有活力,同时齿音并没有因为高频的提升而变得刺耳。
技巧四:侧链 De-Ess
TDR Nova 支持外部侧链输入,我们可以将另一条经过EQ处理“只保留齿音”的轨道发送到Nova的“Sidechain”通道,实现超精准的触发,这种方法与传统的 Split-Band De-Esser 原理相似,但更加灵活。
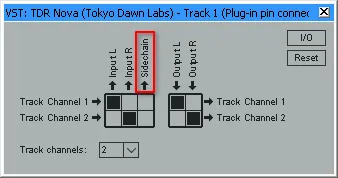 图 11 REAPER中的TDR Nova插件IO跳线板,左侧3×2的表格是输入跳线。可以看到TDR Nova有一个专门的“Sidechain”输入通道(红框所示),可以接收侧链输入。
图 11 REAPER中的TDR Nova插件IO跳线板,左侧3×2的表格是输入跳线。可以看到TDR Nova有一个专门的“Sidechain”输入通道(红框所示),可以接收侧链输入。
原理
传统的去齿音插件通常是通过内部检测齿音来触发压缩,而侧链 De-Ess 则是通过外部的一条专门的“齿音检测轨”来触发压缩器。这条检测轨经过EQ处理,只保留了齿音的频率成分,因此能够更精准地检测到齿音的出现,从而让压缩器的触发更加准确,避免误触发或漏触发。
第一步:创建侧链检测轨
复制一份原始人声轨道,将其命名为“Sidechain – Sibilance”(侧链 – 齿音)。在这条轨道上插入一个EQ插件,将除了齿音所在频段(如4~8 kHz)之外的所有频率都进行大幅度衰减,只保留齿音的频率成分。可以借助EQ插件的“Band Pass(带通)”功能。
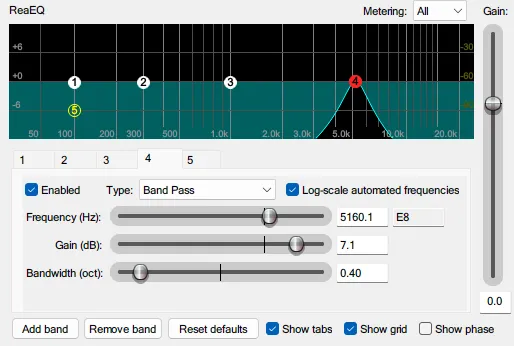 图 12 借助REAPER自带的ReaEQ,使用带通滤波器单独留下齿音所在频段。
图 12 借助REAPER自带的ReaEQ,使用带通滤波器单独留下齿音所在频段。
第二步:设置TDR Nova的侧链输入
在原始人声轨道上插入TDR Nova,然后设置TDR Nova的侧链模式。在界面右上角找到一个标有“Int SC”(以主输入信号作为侧链信号源)的按钮,点击它,在弹出的菜单中选择“Ext SC”(以外部侧链输入信号作为侧链信号源)。
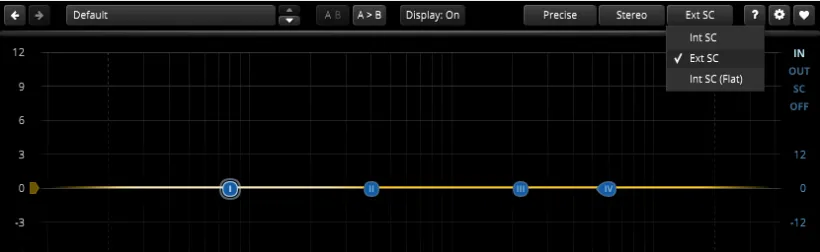 图 13 设置TDR Nova的侧链模式。
图 13 设置TDR Nova的侧链模式。
接着,借助DAW的“轨道路由(track routing)”功能,把“Sidechain – Sibilance”轨道的音频信号发送到TDR Nova插件的“Sidechain”输入通道中。不同的DAW操作方式不同,具体操作以你的DAW为准。
附:如何在REAPER中设置侧链路由
·右键点击混音器里原始人声轨道的推子,打开路由对话框,将“Track Channels(音轨音频通道数)”设置为4,如图 14所示。
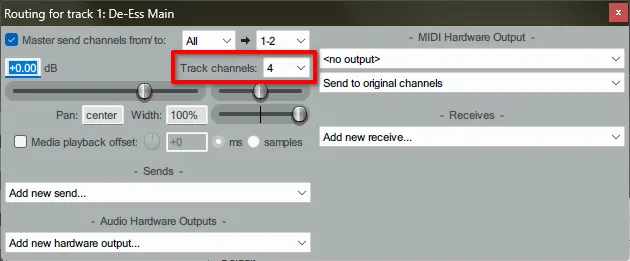 图 14 设置音频通道数。
图 14 设置音频通道数。
·在原始人声轨道的路由对话框中,找到“Receives”区域,点击“Add new receive(添加新的接收路由)”,选择“Sidechain – Sibilance”音轨,建立侧链轨道到原始人声轨道的路由。
·此时,路由对话框的“Receives”会多出侧链轨道的这一栏(背景为深灰色)。找到该栏中的“Audio:1/2 → 1/2”,点击第二个“1/2”(这是个下拉框),在弹出的菜单中选择“3/4”,即可将侧链轨道的音频定向到第3和第4个通道。
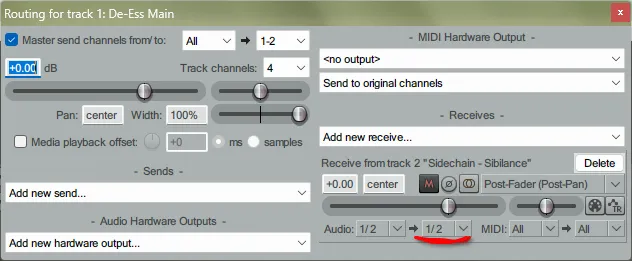 图 15 点击红笔勾画出的这个“1/2”下拉框,随后在弹出菜单中选择“3/4”。
图 15 点击红笔勾画出的这个“1/2”下拉框,随后在弹出菜单中选择“3/4”。
·打开原始人声轨道的TDR Nova插件,点击右上方的“4 in 2 out”按钮,此时你会发现第3和第4通道被自动映射到了TDR Nova的两个侧链输入通道。
·打开侧链音轨“Sidechain – Sibilance”,取消勾选“Master send channels from”复选框,不要将侧链音轨的输出发送到主总线。这一步很关键。
第三步:调整 TDR Nova 参数
经过第二步的设置后,动态均衡的触发将由侧链检测轨的信号决定,只有当检测轨中有齿音信号时,TDR Nova才会对原始人声轨道的对应频段进行动态削减。接下来,在TDR Nova中,设置一个覆盖齿音频率的频段,然后参照第一篇教程的思路,调整“Threshold”、“Ratio”等参数。
这种方法可以让TDR Nova只在真正有齿音的时候工作,极大地提高了处理的精准度。
效果预期
侧链 De-Ess 处理后,齿音的触发更加精准,压缩器只在齿音出现时工作,最大限度地减少了对人声主体的影响。
使用侧链噪声门,控制并行压缩
在本系列的第二篇文章中,我们介绍了分频段并行压缩的方法来保留人声的空气感。而结合侧链Gate(噪声门)来控制并行压缩,可以让这种方法更加智能化:只在需要处理齿音的时候才启用并行压缩的效果。如此,你可以进一步提升处理的自然度。
特别注意:这种做法只适用于齿音瞬间电平远高于其他地方的情况。如果齿音瞬间电平与其他乐句相差不大,侧链噪声门反而会起到反效果(例如,声音出现异常抖动)。
原理
在一些场景里,齿音的瞬间电平非常高,远高于人声的其他元素,这正是侧链噪声门擅长“驯服”的目标。侧链噪声门在这里的作用是充当一个“开关”。我们用原始人声轨道(或经过 EQ处理只突出齿音的轨道)作为噪声门的侧链输入:
·当齿音出现时(信号超过噪声门的阈值〔“Threshold”〕),噪声门打开,让并行压缩处理后的齿音信号通过;
·当没有齿音时,噪声门关闭,并行压缩的信号被静音,只有原始的人声主体信号通过。
这样一来,并行压缩只在齿音出现时发挥作用,避免了对非齿音部分的不必要处理(例如过分处理导致声音发暗、音质损失等)。
实操
我们继续使用并行压缩来进行演示,首先听一段原始的人声素材。
第一步:设置并行轨道
如第二篇文章所述,创建“Body”轨和“Sibilance”轨,“Body”轨保持原始人声,“Sibilance”轨使用多段压缩处理齿音(根据人声情况,频段设为4~8 kHz,比率设为4:1~6:1等)。
第二步:在“Sibilance”轨插入侧链Gate
在 “Sibilance” 轨上,在多段压缩器之后插入一个带侧链功能的噪声门插件(如REAPER自带的ReaGate)。
第三步:设置噪声门的侧链输入
借助DAW的轨道信号路由功能,将噪声门的侧链输入设置为“Body”轨,这样噪声门可以根据原始人声中齿音的有无来控制自身的开合。不同的DAW有不同的操作方法,以你的DAW使用手册为准,REAPER用户可以参考上一章中的讲解。
你还可以选用另一条经过EQ处理只突出齿音的轨道,作为侧链输入信号源。具体做法是:创建一个“Sib Enhanced”音轨,将“Body”轨的素材复制到该音轨中,然后添加一个EQ(如REAPER的ReaEQ),使用钟形曲线(Band模式)给齿音所在频率施加增益。你可以Solo“Sib Enhanced”轨,一边监听,一边选择足够窄、包裹住齿音的频段带宽(或Q值),并调节增益大小,直到齿音格外刺耳,那么这个参数就合适了。
◆注意:务必在设置侧链时关闭侧链音轨到主总线的输出,否则侧链音轨会干扰混音。
第四步:调整噪声门参数
·Threshold:设置为刚好在齿音出现时能触发噪声门打开,而在没有齿音时噪声门保持关闭。可以通过播放音频,观察噪声门的指示灯(或电平表)来判断“Threshold”是否合适。
o以ReaGate为例,观察“Threshold”滑杆两侧的绿色电平表,当电平表超过滑块所在位置时,噪声门才把声音放出来。
o“Body”轨的音量与Threshold参数是直接相关的。若你调整了“Body”轨的音量,那么Threshold参数将不适用于新情况,你必须要重新设置该参数。
·Attack:设为0~5 ms,确保噪声门能快速响应齿音的出现。
·Release:设为20~50 ms,根据齿音的长度调整,确保在齿音结束后,噪声门能及时关闭,避免引入不必要的背景噪声。
·Range:设为-∞,确保噪声门关闭时,“Sibilance” 轨的信号被完全静音。若插件上无该参数,但有干湿混合参数,则确保干信号的比例或电平为0。
·Hold(持续时间):若监听时发现声音抖动严重,可酌情调高该参数,让噪声门开得久一些。
·Detector信号源(触发噪声门的信号源):部分插件支持切换Detector信号源,但默认信源常常是音轨的音频,而非外部侧链输入。以ReaGate为例,要将“Detector Input”参数设为“Auxiliary Inputs”(辅助信号输入)。
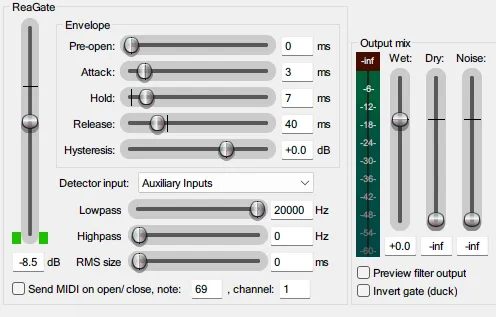 图 16 侧链 Gate 参数设置示意
图 16 侧链 Gate 参数设置示意
第五步:平衡两条轨道的音量
按照第二篇文章中介绍的方法,先确定 “Body” 轨的音量,然后调节 “Sibilance” 轨的音量,直到齿音刚好不刺耳且自然。
效果展示
通过侧链 Gate 控制的并行压缩,齿音部分得到了有效的处理,而在没有齿音的地方,只有 “Body” 轨的信号,整体听感更加自然,没有多余的处理痕迹。
注意事项
·再次强调,这种做法只适用于齿音瞬间电平远高于其他地方的情况。
·噪声门的Threshold设置非常关键,过高会导致齿音出现时噪声门无法打开,处理不到位;过低则会导致噪声门误打开,引入不必要的并行压缩信号。务必反复试听以调整至最佳水平。
·Release时间不宜过长,否则在齿音结束后,噪声门还未关闭,会将“Sibilance”轨中后续的非齿音信号(如背景噪声)引入,影响音质。
·可以结合监听“Sibilance”轨的信号,单独判断噪声门的工作状态是否理想。完成参数调节后,独奏“Sibilance”轨,理想的情况就是只留下齿音(如“ch”“sh”“s”等)。
总结与拓展
在本文中,我们介绍了几种更为高阶和精细的去齿音方法,进一步丰富了在不使用专业De-Esser插件情况下的处理手段:
·FFT动态均衡(如ReaFIR)与频谱编辑的组合,适用于齿音位置飘忽不定且需要极致精细处理的场景,能够实现对齿音频点的精准打击,最大限度地保留人声主体。但这种方法相对耗时,更适合有充足时间进行细抠的项目。
·TDR Nova 的进阶技巧则展示了这款免费动态均衡器的强大潜力,通过细调与 A/B 对比、多句检查与自动化、多频带处理、向上扩展以及侧链De-Ess等功能,可以应对各种复杂的齿音情况,实现自然、透明的处理效果。
·使用侧链噪声门控制并行压缩,是对分频段并行压缩方法的升级,通过智能化的“开关”控制,让并行压缩只在齿音出现时工作,进一步提升了处理的自然度和精准度。
在实际的混音工作中,并没有一种“放之四海而皆准”的去齿音方法,需要根据具体的音频素材、音乐风格以及个人的混音理念来选择合适的方案,甚至可以将多种方法结合使用,以达到最佳的效果。
同时,无论使用哪种方法,都要牢记“适度处理”的原则,过度的去齿音会导致人声失去自然的质感和清晰度。反复的聆听、A/B对比以及不同监听设备(耳机、音箱)的验证,都是确保去齿音效果理想的重要环节。
本系列教程到这里就告一段落了。希望这些免费或低成本的去齿音方法,能够帮助预算有限的音乐人在混音工作中更好地处理齿音问题,打造出专业水准的人声音频。
本文出自《midifan月刊》2025年12月第237期

可下载 Midifan for iOS 应用在手机或平板上阅读(直接在App Store里搜索Midifan即可找到,或扫描下面的二维码直接下载),在 iPad 或 iPhone 上下载并阅读。

♬ ♯ ♩ ♪ ♫ ♬ ♭♬ ♯ ♩ ♪ ♫ ♭♬ ♯ ♩ ♪


广告:传新科技

广告:真力 GLM


