 夜雨聆风
夜雨聆风





OpenClaw 源码解读系列 (十五):实战篇 —— 打造你的“赛博软件工作室”:多 Agent 协同与编排
核心观点:当一个 Agent 的上下文窗口(Context Window)被撑爆时,增加 Token 上限只是治标不治本。真正的解法是组织架构(Organization)。本文将带你利用 OpenClaw 的多 Agent 架构,从零搭建一个包含产品经理、架构师、开发者的“赛博软件工作室”,实现任务的自动分发与递归执行。
在前面的十四篇文章中,我们已经彻底解剖了 OpenClaw 的每一个器官:从神经系统(ACP)到大脑皮层(Prompt),从海马体(Memory)到免疫系统(Sandbox),再到浏览器控制(Browser)、终端交互(Lobster TUI)和条件反射中枢(Auto-Reply)。我们学会了如何让 Agent “听懂”人话,如何让它“记住”用户偏好。
但是,所有的这些能力,都还停留在一个 单体智能 的范畴。我们不再满足于写一个简单的“Hello World”插件,也不再满足于让 Agent 帮我们写一段代码。今天,我们要挑战一个实战案例:多 Agent 协同
我们将不再是一个人在战斗。我们要扮演“老板”,指挥一支由 AI 组成的团队,自动完成复杂的软件开发任务。
1. 为什么要多 Agent?(The Case for Multi-Agent)
你可能问:“现在的模型已经有 100万甚至 200万 Token 的上下文了,为什么我还需要切分出多个 Agent?把所有文件都丢给一个 Agent 不香吗?”
这不仅仅是 Token 数量的问题
1.1 角色污染 (Role Pollution)
如果你让一个 Agent 既做“充满创意的产品设计”,又做“严谨刻板的代码审计”,它的 System Prompt 会变得极其精神分裂。
-
• 产品经理需要发散思维,容忍模糊性,关注用户价值。 -
• 代码审计需要收敛思维,追求精确性,关注语法正确。
当这两股力量在一个 Prompt 中打架时,模型往往会陷入“平庸陷阱”——既没有创意,也不够严谨。最终导致两边都做不好。
1.2 上下文干扰 (Context Noise)
开发者 Agent 不需要知道产品经理 Agent 之前的 50 轮头脑风暴,它只需要知道“需求文档”和“代码仓库”。
如果你把所有的聊天记录都塞给开发者 Agent,它不仅会消耗巨大的 Token 成本,更重要的是,过多的历史信息会诱发幻觉(Hallucination)。它可能会错误地引用已经被废弃的早期方案,或者在浩如烟海的闲聊中迷失了任务的重点。
Clean Context is King. 给 Agent 的上下文越纯净,它的执行效果越好。
1.3 权限隔离 (Privilege Separation)
你可能希望“运维 Agent”拥有删除服务器的权限,但绝不希望“实习生 Agent”也能这么做。
在单体 Agent 模式下,工具(Tools)是全局共享的。一旦你赋予了 rm -rf 的能力,任何一次误判都可能导致灾难。
而在多 Agent 架构中,我们可以精细控制每个 Agent 的工具箱:
-
• Manager: 只有 sessions_spawn(派发任务)和read_file(审查)。 -
• Worker: 有 write_file(写代码)和run_command(跑测试)。
OpenClaw 的设计哲学是:One Agent, One Brain, One Persona.
2. 架构设计:赛博工作室 (The Cyberpunk Studio)
我们将构建一个经典的**层级式(Hierarchical)**多 Agent 系统。
2.1 组织架构图
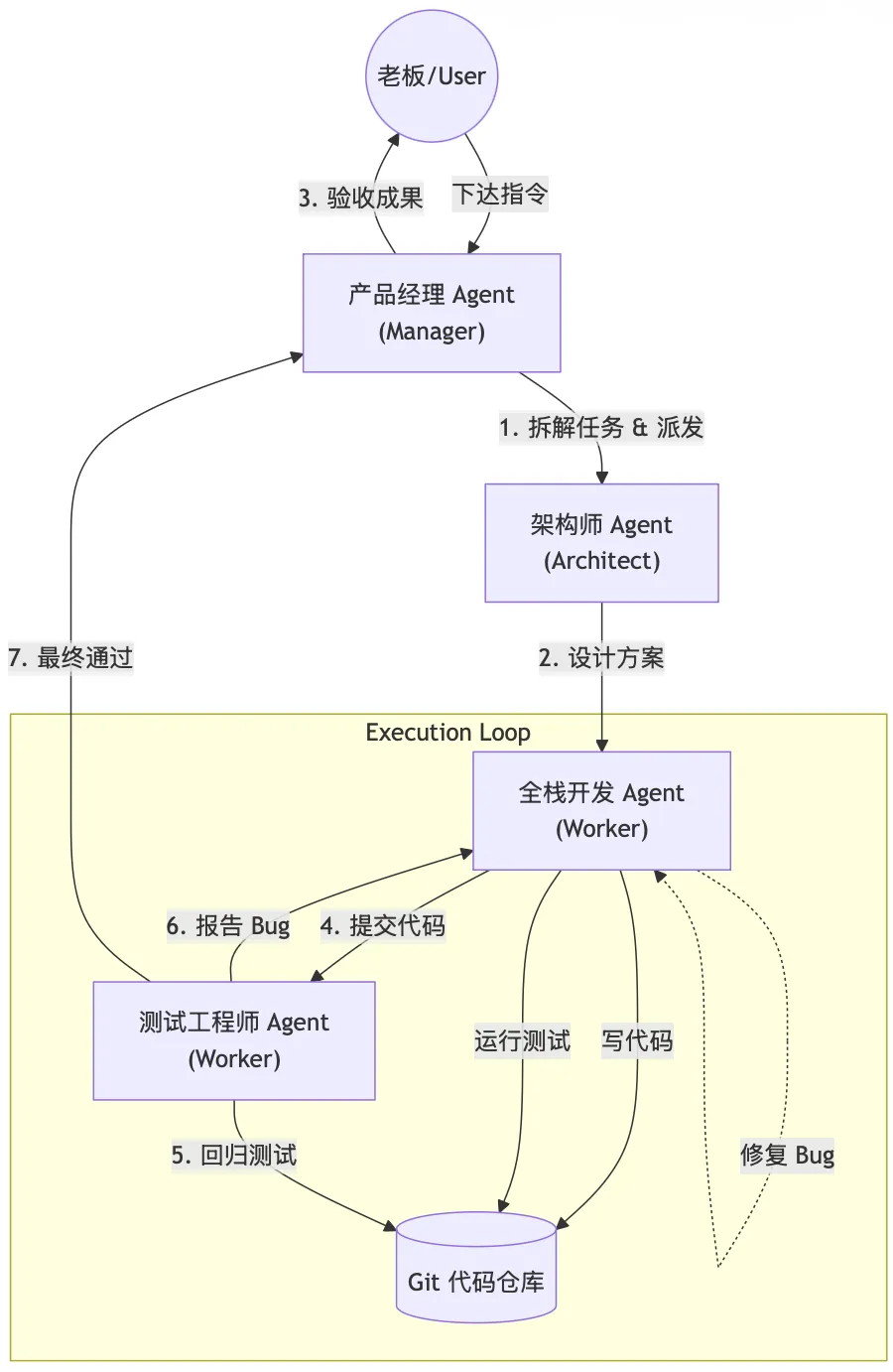
在这个架构中:
-
1. User (Boss):只与 PM 对话,只关心结果,不关心过程。 -
2. PM (Product Manager):负责需求分析和任务验收。它拥有上帝视角,但没有写代码的权限。 -
3. Dev (Developer):专注的执行者。它的上下文里只有代码和具体的任务描述。它不知道 User 是谁,也不知道 PM 的存在,它只知道“有人让我修这个 Bug”。 -
4. QA (Quality Assurance):冷酷的测试机器。它的任务就是找茬。
它们共享同一个 文件系统 (File System),通过 Git 仓库交换“实体”产物,通过 ACP 协议 交换“信息”指令。
3. 基础设施配置 (Infrastructure Setup)
在 OpenClaw 中,开启多 Agent 模式不需要额外部署微服务,只需要修改 openclaw.json 配置文件。
我们要定义三个核心“人格”。请打开你的 ~/.openclaw/openclaw.json:
// ~/.openclaw/openclaw.json
{
"agents": {
// 定义 Agent 列表
"list": [
{
多 Agent 协同与编排
多 Agent 协同与编排
"id": "main", // 默认入口,用户直接对话的对象
"name": "PM Alex",
"workspace": "/gitlab/openclaw", // 共享工作区
"systemPrompt": "你是一个资深技术产品经理。你的职责不是写代码,而是理解用户需求,拆解为技术任务,并指派给 Dev 和 QA 执行。不要自己动手写代码!遇到技术难题,先问架构师。",
// 关键配置:允许生成子 Agent
"subagents": {
"allowAgents": ["dev", "qa", "arch"]
},
// PM 只需要只读权限
"policy": "read-only"
},
{
// === 2. 全栈开发者 (Worker) ===
"id": "dev",
"name": "Coder Bob",
"workspace": "gitlab/openclaw",
"systemPrompt": "你是一个全栈工程师。你只负责执行具体的编码任务。接到任务后,阅读代码,修改代码,运行单元测试。不要做产品决策。代码风格必须遵循现有规范。",
// Dev 需要读写权限
"policy": "read-write",
// Dev 不允许再派发子任务 (防止无限递归)
"subagents": {
"allowAgents": []
}
},
{
// === 3. 测试工程师 (Worker) ===
"id": "qa",
"name": "Tester Cindy",
"workspace": "/gitlab/openclaw",
"systemPrompt": "你是一个严格的代码审计师。你的任务是运行测试套件,检查代码风格,并寻找潜在 Bug。如果发现问题,拒绝任务并返回详细的错误日志。",
"policy": "read-write" // 需要运行测试脚本
}
]
},
// 路由绑定 (可选)
// 这里我们将所有来自 WhatsApp 的消息默认路由给 PM
"bindings": [
{
"agentId": "main",
"match": { "channel": "whatsapp", "accountId": "*" }
}
]
}关键点解析:
-
• Workspace 共享:这里我们让三个 Agent 指向同一个 workspace目录。这模拟了“大家在同一个办公室(Repo)工作”的场景。OpenClaw 默认支持这种并发访问,虽然文件系统本身没有锁,但在实际操作中,通过 PM 的编排(先 Dev 后 QA),我们可以避免竞态条件。 -
• Subagents Allowlist: mainAgent 被授权调用dev和qa。这是权限控制的关键。如果我们不把dev加入这个列表,PM 就无法指派任务给它。 -
• Policy (权限策略):我们将 PM 设为 read-only,防止它产生幻觉去瞎改代码;将 Dev 设为read-write,赋予它修改世界的权利。
4. 核心协议 —— sessions_spawn 工具深度解析
OpenClaw 是如何实现 Agent A 调用 Agent B 的?
秘密藏在 src/agents/tools/sessions-spawn-tool.ts 中。当我们在配置中开启了 subagents 权限后,main Agent 的工具箱里会自动多出一个名为 sessions_spawn 的神兵利器。
4.1 工具定义 (The Interface)
让我们看看它的函数签名(伪代码,去掉了 TypeBox 的样板代码):
// src/agents/tools/sessions-spawn-tool.ts
typeSessionsSpawnInput={
/**
* 目标 Agent 的 ID,必须在 allowAgents 列表中。
* 例如 "dev" 或 "qa"。
*/
agentId:string;
/**
* 具体的任务描述。
* 这将成为子 Agent 的第一条 User Message。
* 例如 "修复 src/utils.ts 中的空指针异常"
*/
task:string;
/**
* (可选) 指定用什么模型来跑这个任务。
* 比如简单的任务可以用 "gemini-flash",复杂的用 "claude-3-opus"。
* 这实现了成本控制。
*/
model?:string;
/**
* (可选) 思考深度。
* "low" | "medium" | "high"
*/
thinking?:string;
/**
* (可选) 超时时间。防止子任务卡死。
*/
runTimeoutSeconds?:number;
};
typeSessionsSpawnOutput={
/**
* 任务 ID,用于后续查询状态。
*/
runId:string;
/**
* 状态,通常是 "accepted"。
* 注意:这是一个异步调用,accepted 仅代表任务已进入队列。
*/
status:"accepted"|"rejected";
/**
* 子任务的会话 Key。
* 格式如:agent:dev:subagent:run-12345-uuid
*/
sessionKey:string;
};4.2 幕后机制:Inception (盗梦空间)
当 main Agent 调用 sessions_spawn 时,OpenClaw 内部发生了一系列精妙的操作:
-
1. Context Fork (上下文分叉):系统会为目标 Agent ( dev) 创建一个新的 Session。 -
• 关键点:这个 Session 是全新的,没有 main之前的聊天历史包袱。它只有一条 System Prompt(Dev 的人设)和一条 User Message(PM 派发的task)。 -
• 优势:这实现了完美的上下文清洗。Dev Agent 不需要通过几千字的聊天记录去猜测意图,它的世界里只有这一件事。 -
• 会话 Key:子任务的 Session Key 包含 subagent标记,这让系统知道它是一个从属会话,从而在计费和日志上做特殊处理。 -
2. Recursion (递归执行): -
• sessions_spawn实际上是一个异步调用。它派发任务后会立即返回status: "accepted"。 -
• 这就引出了一个问题: mainAgent 怎么知道dev什么时候做完?是轮询?还是回调? -
3. Lifecycle Events (生命周期事件): -
• OpenClaw 引入了 agent.wait工具(或类似的等待机制)。PM Agent 在调用spawn后,通常会紧接着调用wait。 -
• Gateway 会挂起 PM 的请求(Suspend),直到 Dev 完成任务(输出最终结果或调用 task_complete)。 -
• 一旦 Dev 完成,Gateway 会捕获 Dev 的最后一条输出,将其作为 Tool Result返回给 PM。
这种 Spawn -> Wait -> Collect 的模式,就是经典的 MapReduce 思想在 Agent 领域的重现。
4.3 死锁与递归限制
为了防止无限递归(比如 A 叫 B,B 又叫 A),OpenClaw 实现了严格的检测机制:
// src/process/spawn-utils.ts (伪代码逻辑)
functionvalidateSpawn(parentSession, targetAgentId){
// 1. 检查 allowlist
if(!config.allowAgents.includes(targetAgentId)){
thrownewError("Permission denied");
}
// 2. 检查调用链深度
if(parentSession.depth >MAX_DEPTH){
thrownewError("Max recursion depth exceeded");
}
// 3. 检查循环调用 (Cycle Detection)
// 如果调用链中已经出现了 targetAgentId,说明发生了循环
if(parentSession.callChain.includes(targetAgentId)){
thrownewError(`Cycle detected: ${callChain} -> ${targetAgentId}`);
}
}5. 实战演练:修复一个真实 Bug
现在,让我们按下启动键,看看这个“赛博工作室”是如何运转的。
场景:我发现 src/utils/date.ts 里的 isLeapYear 函数在处理整百年(如 1900年)时有 Bug,请修复它并确保测试通过。
Round 1: PM 的调度 (The Manager)
User: “src/utils/date.ts 里的闰年判断有问题,1900年不应该是闰年。修复它。”
Main Agent (PM) 收到消息。它分析 System Prompt,意识到自己不该动手。它查看 ls,确认了文件存在。
PM (Thinking):
用户反馈了一个 Bug。虽然我可以自己改,但我的职责是 PM。我应该把这个任务派发给 Dev。
任务描述需要尽可能详细,我要把文件路径和具体的错误现象告诉 Dev。
PM Action:
{
"tool":"sessions_spawn",
"args":{
"agentId":"dev",
"task":"修复 src/utils/date.ts 中的 isLeapYear 函数。目前它错误地将 1900 年判断为闰年。请确保符合公历规则(整百年必须能被400整除)。修复后运行相关测试。",
"model":"claude-3-5-sonnet"// 这是一个编程任务,用强力模型
}
}Tool Output:
{
"runId":"run-abc-123",
"status":"accepted",
"sessionKey":"agent:dev:subagent:..."
}Round 2: Dev 的执行 (The Worker)
Dev Agent 被唤醒。它的上下文非常干净,只有 PM 给它的任务。
Dev (Thinking):
收到任务:修复闰年 Bug。
第一步:我需要读取代码,确认问题。
Dev Action 1: read_file("src/utils/date.ts")
File Content:
exportfunctionisLeapYear(year:number):boolean{
return year %4===0;// Bug!
}Dev (Thinking):
确实有问题。只判断了
% 4,漏掉了% 100和% 400的逻辑。
我需要修改它。
Dev Action 2: write_file("src/utils/date.ts", ...)
New Content:
exportfunctionisLeapYear(year:number):boolean{
return(year %4===0&& year %100!==0)||(year %400===0);
}Dev (Thinking):
代码修好了。但我不能直接交差,我得跑个测试证明我是对的。
我先看看有没有现成的测试文件。
Dev Action 3: ls("src/utils") -> 发现 date.test.ts
Dev Action 4: run_command("vitest run src/utils/date.test.ts")
Command Output: Tests passed.
Dev (Thinking):
测试通过。任务完成。
Dev Final Response:
修复已完成。更新了
isLeapYear逻辑,增加了对整百年的判断。单元测试已通过。
Round 3: PM 的验收 (The Acceptance)
PM Agent 收到了 sessions_spawn 的最终结果(Dev 的回复)。
PM (Thinking):
Dev 说修好了,测试也过了。
我需要最后确认一下,然后回复用户。
PM Final Response:
任务已完成。Dev 修正了
src/utils/date.ts中的逻辑,现在 1900 年能被正确识别为平年了。
6. 进阶玩法:动态团队与成本控制
OpenClaw 的这套架构不仅仅是“能用”,它还非常“省钱”。
6.1 动态模型路由 (Dynamic Model Routing)
在 sessions_spawn 中,PM 可以根据任务难度指定模型:
-
• 文档润色任务 -> 派发给 writerAgent (使用gemini-1.5-flash,便宜且快)。 -
• 复杂重构任务 -> 派发给 architectAgent (使用claude-3-opus,昂贵但逻辑强)。
这样,你就不需要为了偶尔的复杂任务,而全天候运行昂贵的大模型。好钢用在刀刃上。
6.2 并行执行 (Parallel Execution)
PM 可以同时派发多个任务:
// PM 的伪代码逻辑
const task1 =spawn("dev",{task:"Implement Feature A"});
const task2 =spawn("dev",{task:"Implement Feature B"});
// 等待所有任务完成
awaitPromise.all([task1, task2]);这对于大型重构非常有用。你可以让一个 Agent 改前端,一个 Agent 改后端,效率直接翻倍。
7. 高级配置技巧 (Advanced Configuration)
-
• 配置分离 ($include): -
• 不要把所有配置写在一个巨大的 openclaw.json里。利用$include语法将敏感配置(如auth.json5)和环境特定配置(如env-prod.json5)分离。 -
• GitOps: 将通用配置纳入版本控制,将敏感配置加入 .gitignore。 -
• 环境隔离: -
• 在同一台机器上运行多个 Agent 时,利用 OPENCLAW_HOME环境变量指向不同的配置目录,实现完全的物理隔离。 -
• 端口冲突处理: -
• 默认端口 18789若被占用,不要盲目kill。使用lsof -i :18789确认是否为另一个 OpenClaw 实例。若是,考虑在配置中修改gateway.port运行多实例。
8. 架构设计精要与技巧 (Architectural Design Patterns)
OpenClaw 之所以能保持轻量、高性能且易于扩展,得益于以下几个关键的架构决策和设计模式。理解这些,你就能真正看懂 OpenClaw 的源码之美。
8.1 “Local-First” 的网络穿透策略 (Inbound-First Networking)
-
• 挑战: 作为个人助手,OpenClaw 通常运行在家庭网络、笔记本或内网服务器上,没有固定的公网 IP。 -
• 技巧: 拒绝 Webhook,拥抱 Long Polling / WebSocket。 -
• 传统的 ChatBot 开发常依赖 Webhook(需要公网 IP 接收 HTTP POST)。OpenClaw 反其道而行,优先实现 Telegram Long Polling, Discord Gateway (WS), Slack Socket Mode。 -
• 优势: 零配置部署。用户无需折腾内网穿透(如 ngrok),开箱即用,且防火墙友好(只出不进)。
8.2 通用消息总线与归一化 (Unified Message Bus & Normalization)
-
• 设计: 系统内部不处理 “Telegram 消息” 或 “WhatsApp 消息”,只处理 “OpenClaw Message”。 -
• 技巧: Layered Abstraction (分层抽象)。 -
• 接入层 (Ingress): 各 Channel 插件负责将异构的第三方 Payload 转换为标准化的 InboundMessage(包含content,sender,threadId,attachments)。 -
• 核心层 (Core): Agent 只针对标准消息编程,完全不知道消息来自哪个平台。 -
• 输出层 (Egress): Dock接口负责将标准回复渲染回特定平台的格式(如将 Markdown 表格转为 Slack Block Kit,或 WhatsApp 纯文本)。
8.3 动态系统提示词工程 (Dynamic System Prompt Engineering)
-
• 痛点: 随着功能增加,System Prompt 会变得巨大,超出 Token 限制。 -
• 技巧: Modular Composition (模块化组装)。 -
• OpenClaw 不使用静态的 Prompt 字符串。System Prompt 是在运行时动态构建的: Base Persona+Time Context+Enabled Skills Instructions+User Preferences+Memory Snippets -
• 按需加载: 只有当用户启用了 jira插件时,Jira 相关的 Prompt 指令才会注入。这极大节省了 Token 并降低了模型幻觉。
8.4 状态管理的 “GitOps” 哲学 (Config-as-Code)
-
• 设计: 拒绝数据库(No Database)。 -
• 技巧: File-System is the Source of Truth。 -
• 所有的配置(Config)、记忆(Memory)、会话日志(Session Logs)都以人类可读的文本文件(JSON/JSON5/Markdown)存储在文件系统中。 -
• 优势: 用户可以用 Git 管理自己的 AI 助手配置;可以用 VS Code 直接编辑记忆;可以用 grep搜索日志。数据完全掌握在用户手中,而非黑盒数据库里。
8.5 异步事件驱动与流式处理 (Async Event-Driven & Streaming)
-
• 设计: 全链路流式(End-to-End Streaming)。 -
• 技巧: Observable Streams。 -
• 从 LLM 输出的第一个 Token 开始,数据就通过 WebSocket / SSE 流式传输到前端(Canvas/CLI)。 -
• Backpressure (背压): 在多步骤工具调用(Multi-Step Tool Use)中,中间步骤的日志也会实时推送,让用户感知到 Agent 的“思考过程”,缓解等待焦虑。
9. 局限性
-
• 调试复杂度 (Debugging Complexity): -
• 当多个 Agent 并发运行时,日志交织在一起,排查问题(如“谁修改了这个文件?”)变得非常困难 -
• 资源竞争 (Resource Contention): -
• 多个 Agent 同时运行会消耗大量 Token 和 CPU 资源,甚至触发 LLM Provider 的 Rate Limit。目前缺乏全局的资源调度器。
10. 总结:从 Copilot 到 Co-worker
如果我们把 AI 辅助编程的发展划分为三个阶段:
-
1. Copilot 阶段:你在写代码,AI 在旁边补全。你是主驾驶,它是副驾驶。上下文很短,它不知道整个项目的全貌。 -
2. ChatBot 阶段:你把代码贴给 ChatGPT,它给你改好你再贴回来。你是搬运工,它是外包。 -
3. Co-worker 阶段 (OpenClaw):你有一个团队。你是 CTO,AI 是你的 PM、架构师和程序员。你只需要定义目标,它们自己去拆解、执行、验证、协作。
OpenClaw 的多 Agent 架构,正是通向第三阶段的钥匙。
它通过 Workspace 共享 解决了数据孤岛,通过 Subagents 权限 解决了安全隐患,通过 ACP 协议 解决了工具调用,通过 Sessions Spawn 解决了上下文污染。
下期预告(第十六篇):
下一篇,我们会把视角从“多 Agent 架构设计”拉回到真实部署场景:在无法直接访问外网的前提下,如何在群晖 NAS 上通过本机交叉构建 Docker 镜像、离线导入和安全参数运行,把 OpenClaw Gateway 稳定地跑起来,并兼顾 HTTPS 访问、局域网安全和数据持久化。
