 夜雨聆风
夜雨聆风





Python PyPDF2模块详细介绍
1. 创始时间与作者
-
创始时间:PyPDF2 首次发布于 2010年(首个版本 1.0.0)
-
核心开发者:
-
Mathieu Fenniak:初始创建者和主要维护者
-
Phaseit, Inc.:后续维护机构
-
开源社区贡献:超过100位开发者参与优化
-
项目定位:纯Python PDF工具包,提供PDF文件的读取、分割、合并、转换等操作功能
2. 官方资源
-
GitHub 地址:https://github.com/py-pdf/PyPDF2
-
PyPI 地址:https://pypi.org/project/PyPDF2/
-
文档地址:https://pypdf2.readthedocs.io/
-
官网地址:https://pypdf2.readthedocs.io/
注意:PyPDF2 已停止维护,推荐使用其继任者 pypdf,API 完全兼容
3. 核心功能

4. 应用场景
1. PDF合并与拆分
from PyPDF2 import PdfReader, PdfWriter# 合并多个PDFdef merge_pdfs(input_paths, output_path):writer = PdfWriter()for path in input_paths:reader = PdfReader(path)for page in reader.pages:writer.add_page(page)with open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 拆分PDF为单页文件def split_pdf(input_path, output_dir):reader = PdfReader(input_path)for i, page in enumerate(reader.pages):writer = PdfWriter()writer.add_page(page)output_path = f"{output_dir}/page_{i+1}.pdf"with open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 使用示例merge_pdfs(["doc1.pdf", "doc2.pdf"], "merged.pdf")split_pdf("large_document.pdf", "split_pages")
2. PDF文本提取
from PyPDF2 import PdfReaderimport redef extract_text_from_pdf(pdf_path, output_txt=None):reader = PdfReader(pdf_path)text = ""for page in reader.pages:page_text = page.extract_text()if page_text:# 基本清理cleaned_text = re.sub(r'\s+', ' ', page_text) # 替换多个空格text += cleaned_text+"\n\n"if output_txt:with open(output_txt, "w", encoding="utf-8") as f:f.write(text)return text# 提取并分析文本text = extract_text_from_pdf("report.pdf", "report.txt")print(f"提取字符数: {len(text)}")
3. PDF加密与解密
from PyPDF2 import PdfReader, PdfWriter# 添加密码保护def encrypt_pdf(input_path, output_path, password):reader = PdfReader(input_path)writer = PdfWriter()for page in reader.pages:writer.add_page(page)writer.encrypt(user_password=password, owner_password=None, use_128bit=True)with open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 解密PDFdef decrypt_pdf(input_path, output_path, password):reader = PdfReader(input_path)if reader.is_encrypted:reader.decrypt(password)writer = PdfWriter()for page in reader.pages:writer.add_page(page)with open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 使用示例encrypt_pdf("sensitive.pdf", "protected.pdf", "mysecret123")decrypt_pdf("protected.pdf", "unlocked.pdf", "mysecret123")
4. PDF高级操作
from PyPDF2 import PdfReader, PdfWriterfrom PyPDF2.generic import RectangleObjectdef watermark_pdf(input_path, watermark_path, output_path, position="center"):# 读取主文档和水印文档reader = PdfReader(input_path)watermark_reader = PdfReader(watermark_path)watermark_page = watermark_reader.pages[0]writer = PdfWriter()for page in reader.pages:# 创建水印层page.merge_page(watermark_page)# 调整水印位置if position!= "center":page_width = page.mediabox.widthpage_height = page.mediabox.heightwm_width = watermark_page.mediabox.widthwm_height = watermark_page.mediabox.heightif position == "bottom-right":x = page_width-wm_width-20y = 20elif position == "top-left":x = 20y = page_height-wm_height-20else: # 自定义位置x = 100y = 100# 创建新的水印框watermark_page.mediabox = RectangleObject((x, y, x+wm_width, y+wm_height))writer.add_page(page)with open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 添加目录书签def add_bookmarks(input_path, output_path, bookmarks):reader = PdfReader(input_path)writer = PdfWriter()# 添加所有页面for page in reader.pages:writer.add_page(page)# 添加书签parent = Nonefor title, page_num in bookmarks:writer.add_outline_item(title, page_num, parent)with open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 使用示例watermark_pdf("document.pdf", "watermark.pdf", "watermarked.pdf", "bottom-right")add_bookmarks("long_document.pdf", "with_toc.pdf", [ ("Introduction", 0), ("Chapter 1", 4), ("Chapter 2", 10), ("Conclusion", 25)])
5. 底层逻辑与技术原理
核心架构
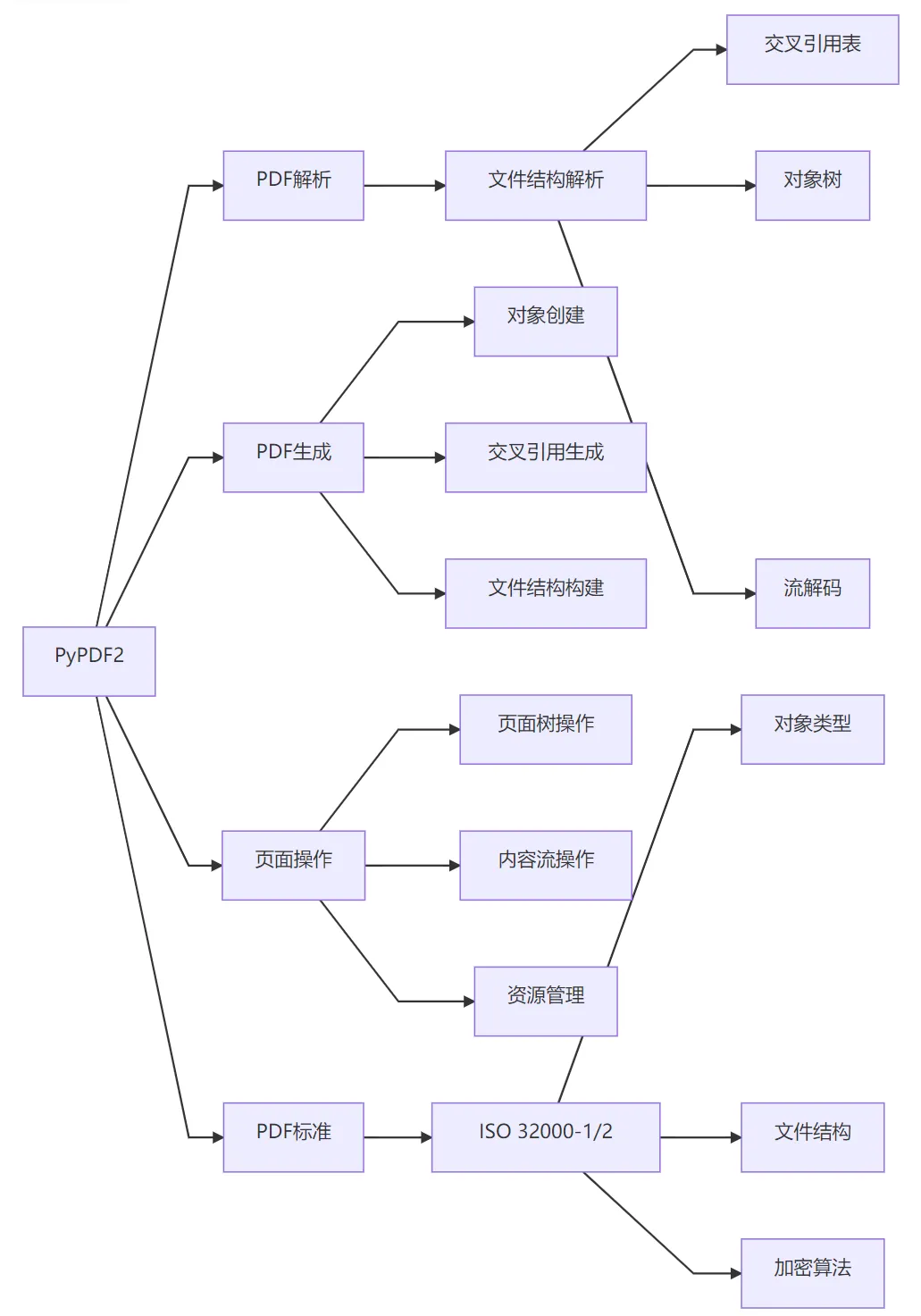
关键技术实现
-
PDF文件结构处理:
-
解析PDF的物理结构:文件头、主体、交叉引用表、文件尾
-
处理PDF的逻辑结构:对象树、页面树、书签树
-
支持对象流和交叉引用流(PDF 1.5+)
-
内容流处理:
-
解析页面内容流(包含文本、图形指令)
-
基本文本提取(基于文本对象位置)
-
不支持高级布局分析(如表格识别)
-
加密系统:
-
支持标准安全处理程序(Standard Security Handler)
-
实现RC4和AES(PDF 1.6+)解密算法
-
支持用户密码和所有者密码
-
内存管理:
-
延迟加载(不立即解析整个文件)
-
流式处理大文件
-
可选的内存优化模式
6. 安装与配置
基础安装
pip install PyPDF2
替代方案安装(推荐)
# 安装活跃维护的pypdf(完全兼容API)pip install pypdf
可选依赖
| 功能 | 依赖包 | 安装命令 |
|---|---|---|
| 加密加速 | PyCryptodome | pip install pycryptodome |
| 图像处理 | Pillow | pip install pillow |
| PDF分析 | pdfminer | pip install pdfminer.six |
环境要求
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| Python | 3.6+ | 3.8+ |
| 内存 | 512MB | 2GB+(大文件处理) |
| 磁盘空间 | 无特殊要求 | 足够存储PDF文件 |
7. 核心组件详解
主要类与功能
| 类 | 功能 | 常用方法 |
|---|---|---|
PdfReader |
读取PDF文件 | .pages, .metadata, .outline |
PdfWriter |
创建/修改PDF | .add_page(), .write(), .encrypt() |
PdfMerger |
合并多个PDF | .append(), .merge(), .write() |
PageObject |
页面操作 | .extract_text(), .rotate(), .merge_page() |
PdfFileReader |
旧版读取器 | (兼容旧版本) |
PdfFileWriter |
旧版写入器 | (兼容旧版本) |
文本提取方法对比
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
page.extract_text() |
简单易用 | 格式丢失,顺序可能错乱 | 快速内容提取 |
page.extract_text(0) |
保留垂直文本 | 布局不准确 | 垂直排版文档 |
page.extract_text(1) |
保留布局 | 可能包含无关字符 | 需要保持文本位置 |
| 结合pdfminer | 高精度提取 | 需要额外依赖 | 精确文本提取 |
8. 高级用法
1. PDF表单处理
from PyPDF2 import PdfReader, PdfWriterdef fill_pdf_form(input_path, output_path, field_data):reader = PdfReader(input_path)writer = PdfWriter()# 复制所有页面for page in reader.pages:writer.add_page(page)# 获取表单字段fields = reader.get_fields()# 填充表单数据for field_name, value in field_data.items():if field_name in fields:writer.update_page_form_field_values(writer.pages[0], {field_name: value} )# 保存填充后的PDFwith open(output_path, "wb") as out_pdf:writer.write(out_pdf)# 使用示例form_data = {"name": "张三","email": "zhangsan@example.com","phone": "13800138000","signature": "电子签名数据"}fill_pdf_form("application_form.pdf", "filled_form.pdf", form_data)
2. PDF元数据分析
from PyPDF2 import PdfReaderimport jsondef analyze_pdf_metadata(pdf_path):reader = PdfReader(pdf_path)metadata = reader.metadata# 基础元数据result = {"title": metadata.get("/Title", ""),"author": metadata.get("/Author", ""),"creator": metadata.get("/Creator", ""),"producer": metadata.get("/Producer", ""),"creation_date": metadata.get("/CreationDate", ""),"mod_date": metadata.get("/ModDate", ""),"pages": len(reader.pages),"encrypted": reader.is_encrypted,"bookmarks": [] }# 提取书签if reader.outline:for item in reader.outline:if isinstance(item, list):result["bookmarks"].append(extract_bookmark(item))# 提取嵌入文件result["attachments"] = list(reader.attachments.keys())return resultdef extract_bookmark(bookmark):if isinstance(bookmark, list):return [extract_bookmark(item) for item in bookmark]else:return {"title": bookmark.title,"page": bookmark.page.idnumifbookmark.page else None }# 使用示例pdf_info = analyze_pdf_metadata("document.pdf")print(json.dumps(pdf_info, indent=2, ensure_ascii=False))
3. PDF/A合规转换
from PyPDF2 import PdfReader, PdfWriterfrom PyPDF2.pdf import ContentStreamdef convert_to_pdfa(input_path, output_path):reader = PdfReader(input_path)writer = PdfWriter()# 添加所有页面for page in reader.pages:# 清理不兼容内容clean_page(page)writer.add_page(page)# 设置PDF/A元数据writer.add_metadata({"/Producer": "PyPDF2 PDF/A Converter","/Trapped": "/False","/GTS_PDFAVersion": "/PDF/A-1b" })# 添加输出配置writer.addMetadata({"output": "pdfa-1b","version": "1.4" })# 保存为PDF/Awith open(output_path, "wb") as out_pdf:writer.write(out_pdf)def clean_page(page):# 移除不兼容的注释if "/Annots" in page:del page["/Annots"]# 清理内容流content = page.get_contents()if content:stream = ContentStream(content, page.pdf)# 简化操作 - 实际需要更复杂的清理page[NameObject("/Contents")] = stream# 移除透明效果if "/Group" in page and page["/Group"]["/S"] == "/Transparency":del page["/Group"]# 使用示例convert_to_pdfa("input.pdf", "output_pdfa.pdf")
4. PDF内容分析
from PyPDF2 import PdfReaderimport redef analyze_pdf_content(pdf_path):reader = PdfReader(pdf_path)results = {"page_count": len(reader.pages),"text_pages": 0,"image_pages": 0,"form_fields": list(reader.get_fields().keys()) if reader.get_fields() else [],"font_usage": {},"security": {"encrypted": reader.is_encrypted,"permissions": {} } }# 提取权限信息if reader.is_encrypted:results["security"]["permissions"] = {"print": reader.decrypt("") != 0, # 空密码尝试"modify": bool(reader._permissions & 0b100),"copy": bool(reader._permissions & 0b1000),"annotate": bool(reader._permissions & 0b10000) }# 分析每页内容for i, page in enumerate(reader.pages):page_data = {"number": i+1,"size": {"width": page.mediabox.width,"height": page.mediabox.height },"rotation": page.get("/Rotate", 0),"has_text": False,"has_images": False,"fonts": set() }# 检查文本text = page.extract_text()if text and len(text.strip()) >10: # 简单阈值page_data["has_text"] = Trueresults["text_pages"] += 1# 简单字体分析if "/Font" in page["/Resources"]:for font_ref in page["/Resources"]["/Font"]:font = page["/Resources"]["/Font"][font_ref]font_name = font.get("/BaseFont", font_ref).lstrip("/")page_data["fonts"].add(font_name)if font_name in results["font_usage"]:results["font_usage"][font_name] += 1else:results["font_usage"][font_name] = 1# 检查图像if "/XObject" in page["/Resources"]:xobjects = page["/Resources"]["/XObject"]for obj in xobjects:if xobjects[obj]["/Subtype"] == "/Image":page_data["has_images"] = Trueresults["image_pages"] += 1break# 添加到结果results[f"page_{i+1}"] = page_datareturn results# 使用示例analysis = analyze_pdf_content("technical_document.pdf")print(f"文档共 {analysis['page_count']} 页")print(f"包含文本的页数: {analysis['text_pages']}")print(f"包含图像的页数: {analysis['image_pages']}")print(f"使用的字体: {list(analysis['font_usage'].keys())}")
9. 最佳实践
-
处理大文件
# 使用流式处理避免内存溢出with open("large.pdf", "rb") as pdf_file:reader = PdfReader(pdf_file)for page in reader.pages:# 逐页处理process_page(page)
-
错误处理
from PyPDF2.errors import PdfReadErrortry:reader = PdfReader("corrupted.pdf")except PdfReadError as e:print(f"PDF解析错误: {e}")# 尝试修复或使用备用工具
-
文本提取优化
# 结合pdfminer提高文本提取精度from pdfminer.high_level import extract_textdef extract_text_accurate(pdf_path):return extract_text(pdf_path)
-
兼容性处理
# 检查PDF版本reader = PdfReader("document.pdf")pdf_version = reader.pdf_headerif pdf_version.startswith(b"%PDF-1.5") or pdf_version.startswith(b"%PDF-1.6"):print("使用高级特性处理")
10. 与同类工具对比
| 特性 | PyPDF2/pypdf | pdfminer.six | PyMuPDF | ReportLab |
|---|---|---|---|---|
| 读取PDF | ✅ | ✅ | ✅ | ❌ |
| 写入PDF | ✅ | ❌ | ✅ | ✅ |
| 文本提取 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ❌ |
| 图像处理 | ⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 表单处理 | ⭐⭐ | ⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 渲染质量 | ⭐⭐ | ❌ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 性能 | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 学习曲线 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
11. 企业级应用案例
-
文档管理系统
-
自动提取PDF元数据和内容
-
批量添加水印和页眉页脚
-
文档分类和索引
-
金融服务
-
处理银行对账单和财务报告
-
自动提取表格数据
-
生成加密的客户报表
-
教育机构
-
合并教学材料
-
创建课程包
-
试卷自动批改系统
-
法律行业
-
合同合并与拆分
-
添加数字签名
-
敏感信息自动遮盖
-
出版行业
-
批量处理图书章节
-
生成目录书签
-
转换PDF/A存档格式
总结
PyPDF2 是Python生态中历史悠久的PDF处理工具,核心价值在于:
-
纯Python实现:无需外部依赖
-
功能全面:覆盖PDF操作主要需求
-
简单易用:直观的API设计
-
轻量级:适合快速集成和脚本开发
技术演进:
-
2010: PyPDF2 首次发布
-
2016: 支持Python 3
-
2020: 停止维护
-
2022: pypdf 作为活跃分支出现
注意事项:
-
PyPDF2 已停止维护,推荐使用 pypdf
-
文本提取功能有限(推荐结合pdfminer)
-
复杂PDF操作可能受限
适用场景:
-
PDF文件合并与拆分
-
页面旋转与排序
-
添加水印和页眉页脚
-
基本文本提取
-
PDF加密与解密
-
元数据管理
安装使用:
# 安装PyPDF2(历史版本)pip install PyPDF2# 安装推荐替代品pypdfpip install pypdf
学习资源:
-
pypdf文档:https://pypdf.readthedocs.io/
-
示例代码:https://github.com/py-pdf/pypdf/tree/main/examples
-
进阶教程:https://realpython.com/pdf-python/
截至2023年,PyPDF2在PyPI的累计下载量超过 1亿次,虽然已停止维护,但其API设计影响了后续PDF处理库的发展。对于新项目,建议使用其活跃分支 pypdf。
