 夜雨聆风
夜雨聆风





Typhoon OCR:面向泰语文档提取的开源视觉语言模型
📖 核心导读
在数字化浪潮中,文档提取是核心环节,但现有视觉语言模型(VLM)在处理泰语等低资源语言时表现不佳。泰语因非拉丁字母、无显式词边界及高度非结构化文档等特性,给现有开源模型带来巨大挑战。本文介绍的Typhoon OCR,是一个专为泰语和英语文档提取设计的开源VLM。它通过多阶段数据构建流程,结合传统OCR、VLM重构与合成数据,实现了文本转录、布局重建和文档级结构一致性。最新版本Typhoon OCR V1.5在保持轻量级与高效推理的同时,性能媲美甚至超越大型专有模型,为低资源语言的文档理解提供了强大且可部署的解决方案。
研究背景
文档提取是数字工作流的核心组件,然而现有的视觉语言模型(VLM)主要偏向高资源语言。泰语因其独特的语言特性——如堆叠的变音符号、依赖语境的元音位置以及缺乏显式词边界——给可靠的文本分割和识别带来了持续挑战。此外,泰语行政表格、财务记录、收据和表格报告等文档材料通常包含密集且不规则的布局,进一步增加了准确提取和结构重建的难度。
尽管通用VLM(如Qwen3-VL、Gemma 3、InternVL 3.5)在高资源语言上表现强劲,但在低资源环境下,它们常常无法捕捉泰语的这些特性,导致识别错误率升高、布局误解和语义不一致。一个根本原因是泰语多模态数据的稀缺。与英语或中文相比,泰语缺乏大规模的、将文档图像与结构化文本和语义标注对齐的数据集,这限制了现有模型的适应性。因此,许多现有VLM对泰语特定的视觉和语言模式接触有限,难以在公共管理、金融和教育等领域进行泛化。
这些挑战促使我们开发一个专门适配泰语的文档理解模型。先前的研究表明,通过语言和领域特定的监督对大型预训练模型进行微调,可以在无需从头训练的情况下获得显著提升。本研究提出的Typhoon OCR,正是一个面向泰语和英语文档理解的端到端开源VLM。它通过微调一个开源VLM主干网络,并使用由精选真实文档和合成数据构建的任务对齐语料库进行训练,实现了文本提取、布局重建和文档级语义建模等多种视觉语言能力。
研究方法
Typhoon OCR 的核心在于其创新的数据构建流程和模型训练策略。为了应对泰语文档的复杂性和多样性,研究团队设计了一个多阶段的数据构建管道,并针对不同文档类型采用了两种操作模式。
数据构建管道
为了支持不同类型的文档,研究团队构建了一个训练语料库,允许模型在两种模式下运行:默认模式和结构模式。这两种模式在输出中保留的布局信息量不同。单一监督格式既不适合松散结构的文档(如收据或手写笔记),也不适合高度结构化的文档(如财务报告或政府表格)。因此,研究团队根据文档结构进行了简单实用的划分:文档布局结构较弱或无结构的文档,以及具有清晰复杂布局组织的文档。
如图2所示,训练数据收集自多种来源,包括数字原生文档和扫描材料,涵盖多个领域。研究团队采用多阶段管道逐步细化标注,同时平衡可扩展性和监督质量。这些阶段包括:1)使用传统OCR系统和文档文本层解析提取文本内容;2)使用开源VLM和结构化提示重新组织提取的文本;3)通过基于代理的一致性检查进行自动化质量控制;4)选择一部分样本进行人工验证。这种多阶段管道能够在可扩展的数据集构建与减轻自动化标注噪声之间取得平衡。
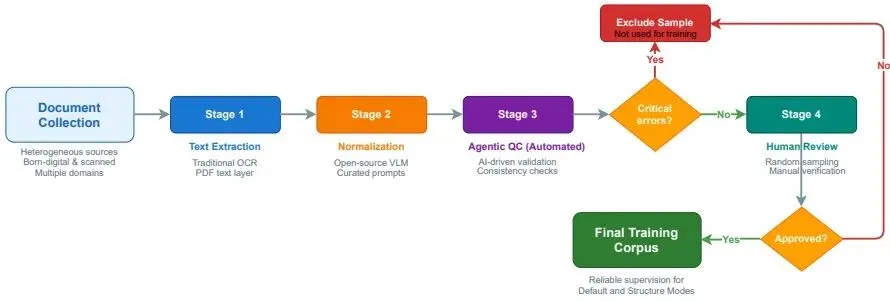
图2 Typhoon OCR结构模式下训练数据生成所使用的多阶段数据集构建流程概览。该流程从多样化来源收集数据,经过文本提取、VLM重构、自动化质量控制和人工验证四个阶段,最终生成高质量的结构化标注数据,用于模型微调。
模型架构与训练
Typhoon OCR 通过在Qwen2.5-VL模型系列(3B和7B参数变体)上进行全参数监督微调(SFT)进行训练。训练流程基于开源olmOCR框架,并进行了扩展以支持多文档理解和长上下文建模。模型在4张H100 GPU上训练三个周期,最终检查点根据保留验证集的性能选择。输入文档图像被调整为固定宽度1800像素,锚文本长度设置为8000个token,最大序列长度限制为17000个token,以在视觉保真度和计算效率之间取得平衡。
在评估方面,研究团队使用了OCR和自然语言生成(NLG)的标准指标:BLEU(衡量预测文本与参考文本之间的n-gram重叠)、ROUGE-L(基于最长公共子序列衡量结构和序列相似性)以及Levenshtein距离(衡量字符级转录保真度,值越低表示编辑操作越少)。评估在内部泰语文档语料库上进行,涵盖泰语财务报告、政府表格和书籍三个类别。评估协议包括两种输入条件:带元数据的PDF(提供原生PDF信息)和纯图像(仅提供光栅化图像),以检验模型在不同文档表示下的鲁棒性。
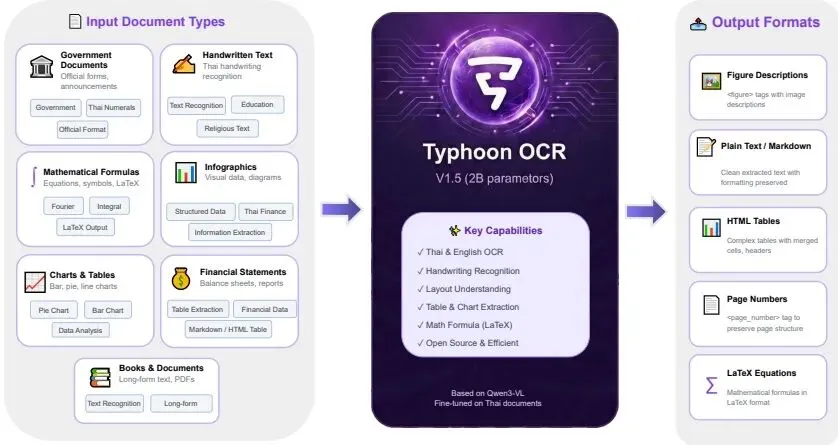
图1 Typhoon OCR概览,展示了支持的输入文档类型及对应的结构化输出表示。图中显示了从财务报告、政府表格、书籍到信息图表、手写笔记等多种文档类型,以及模型能够生成的Markdown、HTML等结构化输出格式。
Typhoon OCR V1.5 的改进
针对Typhoon OCR初版的局限性(如依赖PDF元数据导致推理延迟、操作模式分离增加用户复杂性、模型计算量仍有优化空间等),研究团队推出了Typhoon OCR V1.5。其核心改进在于数据和训练流程的优化。
在数据方面,V1.5采用了单一统一模式,消除了模式选择的需要,使标注能直接从视觉输入生成。同时,使用了更强大的多语言标注模型(Qwen3-VL和Dots.OCR)来提升标注质量。训练语料库进一步扩展,除了保留大部分V1数据外,还新增了泰语翻译的视觉问答(VQA)数据(来自The Cauldron数据集)以保留通用视觉语言基础能力,以及大量合成文档数据以弥补包含复杂数学表达式和图表的泰语文档的稀缺性。如图4所示,合成数据生成流程包括从PyThaiNLP采样泰语词汇并渲染、从SEA-VL和ChartCap采样视觉元素、从LaTeX OCR采样数学表达式,最后使用Augraphy进行图像增强以模拟真实世界的获取伪影。
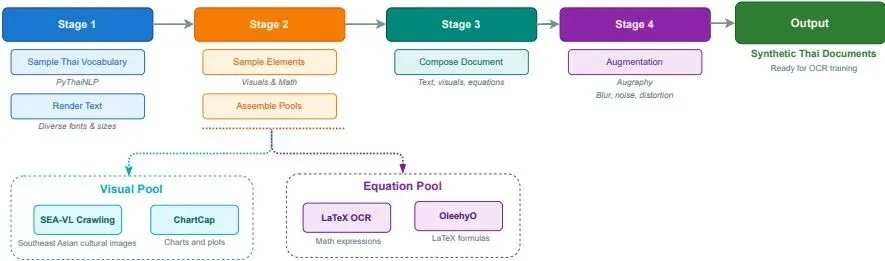
图4 用于OCR训练的合成泰语文档图像生成的多阶段流程。该流程整合了泰语词汇渲染、视觉元素采样、数学表达式采样和图像增强四个阶段,旨在生成包含混合文本、数学和视觉内容的多样化文档,以补充真实数据的不足。
在训练方面,V1.5基于Qwen3-VL 2B模型进行全参数SFT。训练框架基于开源Axolotl框架,并进行了扩展。预处理采用了分辨率感知策略:最大尺寸低于1800像素的图像保留原始分辨率,更大的图像则调整为最大宽度1800像素并保持宽高比。最大序列长度设置为16384个token。训练在4张H100 GPU上进行两个周期,并应用了量化感知训练,使模型在微调过程中暴露于量化效应,从而支持高效的低精度推理。
研究结果
研究团队在多个泰语文档类别上对Typhoon OCR及其后续版本进行了全面评估,并与GPT、Gemini等前沿专有模型进行了比较。结果表明,Typhoon OCR系列在结构化文档提取任务上表现优异,尤其在泰语财务报告和政府表格等密集布局文档上,其性能显著优于或媲美大型专有模型。
Typhoon OCR (V1) 性能表现
表2展示了Typhoon OCR(3B和7B参数)与GPT-4o、Gemini 2.5 Flash在泰语文档解析任务上的性能对比。在结构模式下,Typhoon OCR在财务报告和政府表格类别上持续优于基线模型。这些文档具有密集的布局和结构化内容,Typhoon OCR在有PDF元数据可用时性能提升最为明显,表明显式的布局线索有助于改进结构重建。
|
|
|
|
|
|---|---|---|---|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表2 Typhoon OCR在结构模式下泰语文档解析的性能比较。更高的BLEU和ROUGE-L分数以及更低的Levenshtein距离表示更好的性能。数据表明,Typhoon OCR在财务报告和政府表格上显著优于GPT-4o和Gemini 2.5 Flash,尤其在有PDF元数据时优势更明显。在泰语书籍上,所有模型性能均有所下降,表明当前VLM在处理复杂视觉元素(如插图)方面仍存在局限。
在泰语书籍子集上,所有模型的性能都较低。这类文档由于频繁出现的视觉元素(如插图和非标准图形)增加了图形表示和布局解释的模糊性。结果表明,图形理解仍是当前VLM的一个局限。PDF输入与纯图像输入之间的性能差异很小,表明Typhoon OCR在视觉和文本表示之间实现了有效对齐。值得注意的是,3B变体在多个任务上取得了与7B模型相当的结果,特别是在政府表格上,这表明在受限部署环境下,较小的模型也能有效工作。
Typhoon OCR V1.5 性能表现
表3至表5报告了Typhoon OCR V1.5与Typhoon OCR V1以及两个前沿VLM基线在多个泰语文档类别上的比较评估。尽管参数量更少(2B vs 7B),但Typhoon OCR V1.5在所有指标上的平均性能均高于Typhoon OCR V1。这表明改进的数据和训练策略对文档提取质量的影响大于模型规模本身。从部署角度看,结果表明紧凑的、任务适配的模型可以在降低计算开销的同时提供强大的性能。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表3 按文档类别划分的BLEU分数(越高越好)。数据清晰地显示,Typhoon OCR V1.5 2B在所有类别的平均BLEU分数(0.644)上均优于Typhoon OCR V1 7B(0.558)和两个专有模型。在结构化文档(如政府表格和财务报告)上优势尤为明显,但在信息图表和手写表格等视觉异质性类别上,专有模型仍有一定优势。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表4 按文档类别划分的ROUGE-L分数(越高越好)。在结构相似性衡量上,Typhoon OCR V1.5 2B的平均得分(0.774)同样领先于其他所有模型,特别是在政府表格上取得了0.967的高分,再次证明了其在结构化文档重建方面的优势。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
表5 按文档类别划分的Levenshtein距离(越低越好)。在字符级转录保真度上,Typhoon OCR V1.5 2B的平均距离(0.251)最低,表明其编辑错误最少。在结构化文档上,其距离显著低于专有模型,但在信息图表和手写表格上,专有模型的错误率更低,这与BLEU和ROUGE-L的观察一致,指明了未来改进的方向。
性能提升在结构化文档类型(包括泰语政府表格和财务报告)上最为显著。在这些类别中,Typhoon OCR V1.5在BLEU和ROUGE-L上持续优于专有基线,并实现了更低的Levenshtein距离。这种行为反映了显式布局建模和领域对齐监督对于具有规则结构模式的文档(常见于行政和财务工作流)的益处。
对于视觉异质性类别(如信息图表和手写表格),专有模型在字符级错误率上表现更好。然而,Typhoon OCR V1.5相比V1版本有了显著改进,在词汇和结构指标上缩小了差距。这是我们未来迭代中需要改进的领域。
结论与展望
本研究介绍了Typhoon OCR,一个专为解决泰语文档理解限制而设计的VLM家族。该模型在各种文档理解任务(包括转录准确性、布局重建和结构一致性)上持续显示出相对于基线模型的改进,并与前沿专有系统表现相当。值得注意的是,Typhoon OCR V1.5仅用2B参数的小模型就实现了这些提升,在降低推理成本的同时,在多个文档类别上匹配或超越了更大专有模型的性能。这些结果表明,通过针对预训练VLM的定向适配和精心设计的数据管道,可以在无需从头训练模型或依赖封闭系统的情况下,在低资源环境中实现稳健的文档理解,这使得该方法适用于资源受限和隐私敏感的部署场景。
然而,研究仍存在一些局限性。性能在严重退化的输入(如低分辨率图像、运动模糊和遮挡)上会下降,这表明需要改进数据配方或对噪声和采集伪影进行显式建模。此外,尽管模型目前主要支持泰语和英语,扩展到其他低资源语言是未来研究的自然方向。当前的Typhoon OCR模型系列侧重于文档提取,并不明确支持更高级的推理任务。未来的工作将把该框架扩展到图表理解和结构化信息提取等应用。虽然本评估适合当前的发展阶段,但在更广泛的学术基准(如ThaiOCRBench)上进行评估,是更好地理解模型能力的下一步。
展望未来,研究团队计划在以下几个方向进行深入探索:一是增强模型对恶劣输入条件的鲁棒性,通过更丰富的数据增强和噪声建模技术;二是将模型能力扩展到更多低资源语言,构建多语言文档理解框架;三是探索更高层次的文档推理任务,如从复杂图表中提取信息或进行逻辑推理;四是优化模型架构和训练策略,进一步提升效率和性能。Typhoon OCR的开源特性为社区提供了可扩展的基础,有望推动低资源语言文档理解技术的持续发展。
📚 文献信息
文献作者:Surapon Nonesung, Natapong Nitarach, Teetouch Jaknamon, Pittawat Taveekitworachai, Kunat Pipatanakul
发表时间:2025年(根据文献内容推断,具体月份未明确)
访问链接:GitHub项目主页 | Typhoon OCR 7B模型 | Typhoon OCR V1.5 2B模型 | 官方博客
