 夜雨聆风
夜雨聆风





Markdown导出Word文档技术方案
Markdown 导出 Word 文档技术方案
一、整体架构

核心设计原则:统一 HTML 源架构
• Markdown 渲染后维护一份干净的 HTML 变量
• 预览展示和 Word 导出共用同一 HTML 源
• Mermaid SVG 转图片逻辑复用,确保一致性
二、导出流程详解
2.1 第一阶段:Markdown → HTML
|
// 使用 marked.js 将 Markdown 转为 HTML import { marked } from ‘marked’ const htmlContent = marked.parse(markdownText) |
2.2 第二阶段:Mermaid 预处理
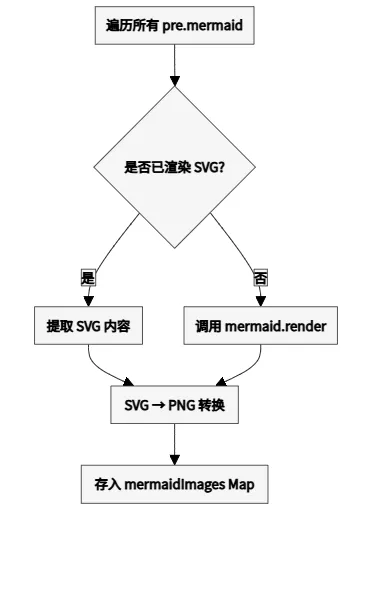
关键函数:
• collectMermaidImages() – 预收集所有 Mermaid 图表
• svgToPngForWord() – SVG 转 PNG(base64)
2.3 第三阶段:HTML → docx 元素
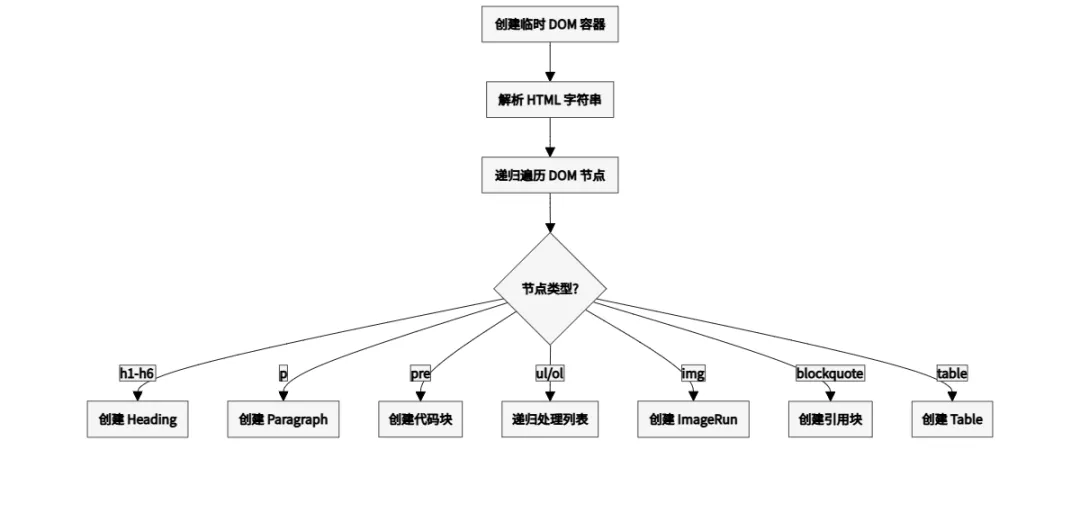
2.4 第四阶段:生成 Word 文件
|
const doc = new Document({ sections:[{ children:docxElements// 转换后的元素数组 }] }) const buffer = await Packer.toBlob(doc) await saveBlobToFile(buffer, filename) |
三、遇到的问题及解决方案
问题 1:第三方库支持不足
|
项目 |
描述 |
|
现象 |
使用 库导出时,代码块和图片丢失 |
|
原因 |
该库对复杂 HTML 结构(嵌套 table、inline style 包装)支持差 |
|
方案 |
弃用 ,改用 库自建解析器 |
|
经验 |
第三方库有局限性,核心功能需自主可控 |
问题 2:有序列表编号丢失
|
项目 |
描述 |
|
现象 |
导出后无编号,只有文字内容 |
|
原因 |
当 第一个子元素是 时(如 ), 为空, 不输出 prefix |
|
方案 |
检测到 是首个子元素时,将 prefix 与 内容合并后再输出 |
问题代码结构:
|
修复逻辑:
|
if (childTag === ‘p’ && isFirst && !textBuffer.trim()) { //首个子元素是 ,合并 prefix 和 内容 textBuffer= child.textContent flushTextBuffer()//此时 prefix + textBuffer 一起输出 } |
问题 3:嵌套列表内容丢失
|
项目 |
描述 |
|
现象 |
多级嵌套的 / 只输出第一层 |
|
原因 |
仅使用 获取内容,未递归遍历子元素 |
|
方案 |
实现通用递归解析架构,支持任意深度嵌套 |
错误做法:
|
// ❌ 只取文本,嵌套结构丢失 const text = li.textContent |
正确做法:
|
// ✅ 递归处理所有子元素 function processElement(element, indentLevel) { for(const child of element.children) { if(child.tagName === ‘UL’ || child.tagName === ‘OL’) { result.push(…processElement(child,indentLevel + 1)) } //… 其他元素处理 } } |
问题 4:内联元素错误换行
|
项目 |
描述 |
|
现象 |
被拆成三行 |
|
原因 |
、 等内联元素被误判为块级元素,触发换行 |
|
方案 |
精确区分内联/块级元素,内联元素追加到 ,块级元素才触发 flush |
元素分类:
|
// 块级元素(触发换行) const blockTags = [‘p’, ‘pre’, ‘div’, ‘ul’, ‘ol’, ‘li’, ‘blockquote’, ‘table’, ‘img’] // 内联元素(不换行,追加到 buffer) const inlineTags = [‘strong’, ’em’, ‘code’, ‘a’, ‘span’, ‘s’, ‘del’, ‘b’, ‘i’, ‘u’] |
问题 5:Mermaid CSS 残留污染
|
项目 |
描述 |
|
现象 |
导出的 Word 中出现 乱码 |
|
原因 |
Mermaid 渲染后 中残留 CSS 样式代码,被当作普通代码块输出 |
|
方案 |
正则检测 + 模式,显式跳过不输出 |
检测逻辑:
|
const text = preElement.textContent const isMermaidCss = /#mermaid-[^\s]+/.test(text) && /\{[^}]*\}/.test(text) if (isMermaidCss) { continue//跳过,不输出 } |
问题 6:Buffer 类型不兼容
|
项目 |
描述 |
|
现象 |
报错: |
|
原因 |
返回的是 Node.js ,而非浏览器 |
|
方案 |
在 中兼容处理,检测类型后统一转换 |
|
let arrayBuffer if (blobOrBuffer instanceof Blob) { arrayBuffer= await blobOrBuffer.arrayBuffer() } else if (Buffer.isBuffer(blobOrBuffer)) { arrayBuffer= blobOrBuffer.buffer } |
问题 7:HTML 预览列表无样式
|
项目 |
描述 |
|
现象 |
预览区的 无编号, 无符号 |
|
原因 |
Tailwind CSS Preflight 重置了 |
|
方案 |
在 样式中手动覆盖 |
|
.prose :deep(ol) { list-style-type:decimal; } .prose :deep(ul) { list-style-type:disc; } |
四、架构演进历程
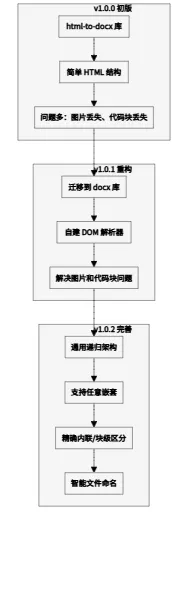
五、核心经验总结
|
序号 |
经验 |
|
1 |
:第三方库有局限性,核心功能需自主实现 |
|
2 |
:HTML 结构可无限嵌套,必须支持任意深度 |
|
3 |
:错误分类会导致格式混乱 |
|
4 |
:Tailwind Preflight 会重置原生样式 |
|
5 |
:预览和导出共用同一数据源,确保一致性 |
|
6 |
:Mermaid 图表先收集到 Map,解析时直接查表 |
