 夜雨聆风
夜雨聆风





翻了五遍openclaw源码,这五大架构设计让我彻底服了
翻了五遍openclaw源码,这五大架构设计让我彻底服了
作者:编程大帅链接:https://www.zhihu.com/question/2001064172218234123/answer/2002128702411146387来源:知乎
已授权转载。
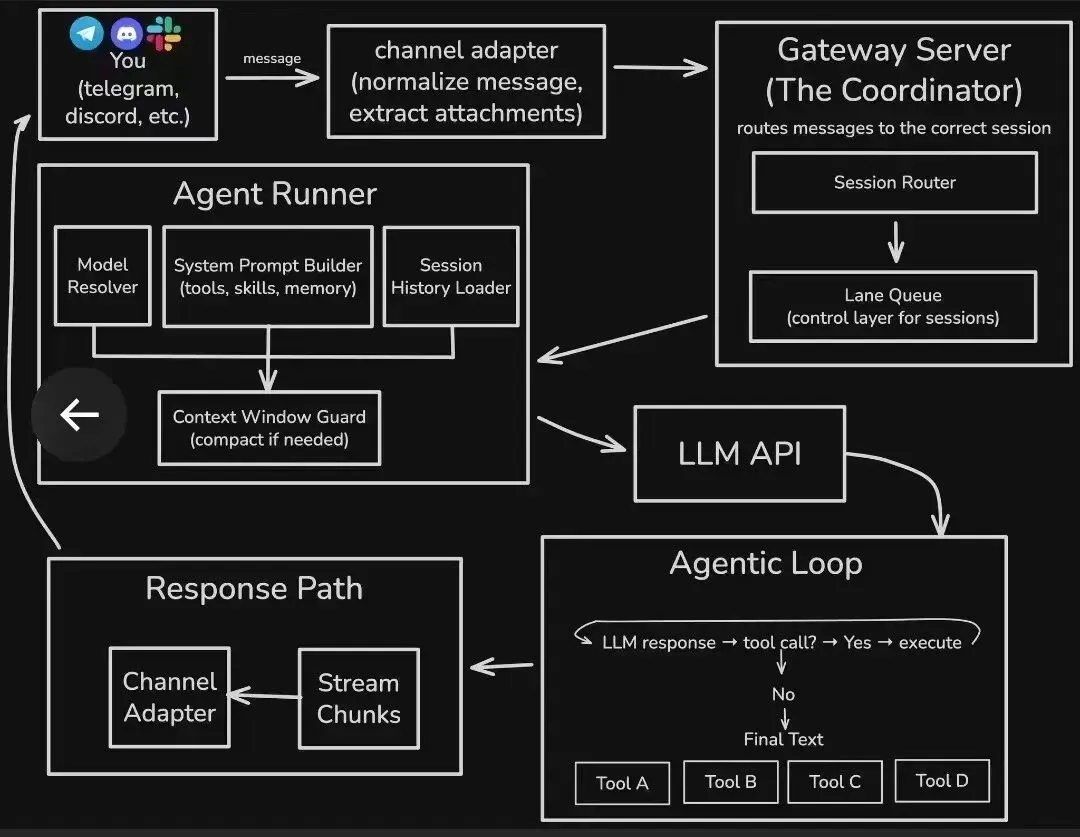
研究过 Clawdbot 源码的人可能不到这个圈子里的 1%,但凡认真看过的都会有种”卧槽原来可以这么做”的感觉。
我去年底开始关注这个项目,从几万星追到现在十几万星,代码翻了不下五遍,中间还照着它的架构重构过自己的一个小项目,踩了不少坑也学了不少东西。很多做 AI Agent 的创业公司花几百万请架构师,设计出来的东西还不如这个开源项目的十分之一精妙。
它不是那种学院派的”理论上正确”,而是工程上真正能跑、能维护、能扩展的东西。
一、两层记忆架构:流水与沉淀的哲学
市面上的两种主流方案,都不太行
做过 AI Agent 的都知道,记忆是个老大难问题。大模型本身是无状态的,每次对话都是从零开始。市面上大部分产品的解决方案:
-
• 把历史对话全塞进 context:token 消耗飞起,context 太长模型反而容易”走神” -
• 用向量数据库做 RAG 检索:检索质量不稳定,而且向量数据库本身就是个运维负担
Clawdbot 的做法:简单到让人觉得”这也行?”
它用了一个两层记忆架构:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
每次新对话开始,先读当天的 Daily Notes 拿到近期 context,再读 MEMORY.md 拿到长期记忆,两个加起来塞进 system prompt。就这么简单,但效果出奇地好。
为什么好使? 因为它区分了”流水”和”沉淀”。人的记忆是怎么工作的——昨天中午吃了什么你可能已经忘了,但你知道自己不吃香菜、对海鲜过敏。前者是流水,后者是沉淀。
用 Markdown 存储的讲究:人能直接打开看、能手动编辑、能用 git 做版本管理,不像向量数据库那样是个黑盒。我之前踩过一个坑,用某个 Agent 框架做项目,某天发现 Agent 的行为突然变得很奇怪,查了半天发现是记忆里存了一条错误信息,但我想删都不知道怎么删,因为那玩意儿不是给人看的。Clawdbot 就没这个问题,记忆出了问题你直接打开 md 文件改就完了。
二、插件与 Skills 系统:”核心精简,外围开放”
大而全的死路
现在做 AI Agent 的一个普遍思路是”大而全”——恨不得把所有功能都内置进去。这种思路的问题:
-
• ❌ 维护成本高得离谱,API 变了得跟着改 -
• ❌ 功能越多 bug 越多,改一个地方可能影响另一个地方 -
• ❌ 用户的需求千奇百怪,根本满足不完
Clawdbot 的反向路线
核心系统只做最基础的事情——消息路由、模型调用、上下文管理、安全沙箱。其他所有功能通过插件和 Skills 来实现。
社区现状:273 个 Skills,覆盖各种场景。官方只维护核心的 9 个,其他 264 个爱用不用、出了问题社区自己修。
你看成功的产品——VS Code、Obsidian、Raycast——哪个不是这个思路?核心团队专注做好底层,生态靠社区来搞。
Skills 系统的工程化设计:每个 Skill 就是一个标准格式的配置文件加一个执行脚本,有 manifest 描述元信息,有 input/output schema 定义接口,有 sandbox 配置指定权限边界。照着模板填就完了,不需要理解整个系统是怎么跑的。我自己照着写过几个,大概一两个小时就能搞定一个可用的 Skill。低门槛是生态繁荣的前提。
三、安全沙箱:务实工程师的取舍之道
AI Agent 的双刃剑
AI Agent 和普通 chatbot 最大的区别是能执行真实操作——跑命令、改文件、发请求、调 API。去年不是有个新闻吗,某个 AI Agent 平台上的应用被曝出数据泄露,原因就是 AI 生成的代码有漏洞。还有更离谱的,有个 Agent 为了”修复”bug 直接把数据库删了。只要 Agent 能执行代码,这类风险就永远存在。
Clawdbot 的沙箱机制
-
• 默认情况下执行任何敏感操作都需要用户确认 -
• 文件操作只能在指定目录里搞 -
• 网络请求有白名单限制,系统命令要过审批 -
• Docker 部署:非 root 用户运行、文件系统可以设成只读、capabilities 全部 drop 掉 -
• openclaw security audit --deep命令:扫描当前配置有没有安全隐患,出报告告诉你哪里有风险、怎么修
有个细节我特别想提:Clawdbot 的安全策略明确写了”prompt injection attacks are out of scope”——就是说它不试图防 prompt 注入,因为以现在的技术这玩意防不住。这种诚实比那些吹”100% 安全”的产品靠谱多了。它的思路是:既然 prompt 注入防不住,那就假设 Agent 会被”骗”,然后在执行层面做限制,让 Agent 就算被骗了也干不了太出格的事。这是务实的工程思维——不追求理论完美,而是在现有约束下做到实际可行的最好。
四、多平台架构:适配器模式的极致实践
多平台接入,坑在哪里
Clawdbot 支持 WhatsApp、Telegram、Discord、Slack、iMessage、Signal、Teams……基本上你能想到的聊天平台它都支持。这事儿听起来简单,不就是接个 API 吗?
每个平台的消息格式不一样、富文本能力不一样、附件限制不一样、webhook 机制不一样、rate limit 不一样。你要是每个平台单独写一套逻辑,代码会变成一坨屎,改一个功能得改八遍,bug 改不完。
WebSocket Gateway + 适配器模式
所有平台消息 → Channel Adapter(格式转换,仅此一件事) → WebSocket Gateway(统一内部格式) → AI Agent(只处理标准格式,不知道消息从哪来) → Channel Adapter(转成各平台格式输出)核心设计原则:
-
• ✅ 每个平台对应一个 Channel Adapter,Adapter 只负责格式转换,业务逻辑一行都没有 -
• ✅ 要加一个新平台,就写一个新 Adapter,不用动任何现有代码 -
• ✅ 中间的 AI Agent 根本不知道消息是从哪个平台来的
我照着这个思路重构过自己的一个多平台机器人项目,代码量直接砍了一半,而且之后加新平台变得特别轻松。这是经典的适配器模式,但它实现得特别干净。
五、CLI 系统:最被低估的用户体验
100+ 个 CLI 子命令,干的都是实事
Clawdbot 有 100 多个 CLI 子命令,能干的事情包括但不限于:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
--deep
--fix 自动修复 |
|
|
|
每个命令都有详细的 help,常用操作都有快捷方式,输出格式支持 JSON 方便脚本处理。
做产品的人总喜欢搞花里胡哨的 Web 界面,觉得命令行”不友好”。但对开发者用户来说,能用命令行搞定的事情就别让我点鼠标。 Clawdbot 的目标用户是技术人群,它就老老实实把 CLI 做好,而不是硬塞一个半吊子的 Web UI。这才是懂用户的产品。
总结
做产品的态度
我研究 Clawdbot 最大的收获不是学会了什么具体技术,而是看到了一种做产品的态度:
-
• 不追求功能多,追求每个功能都做对 -
• 不追求大而全,追求核心足够稳 -
• 不追求理论完美,追求工程可行
现在太多 AI 创业公司的思路是堆功能、卷参数。但 Clawdbot 证明了另一条路是可行的——把基础设施做扎实,把架构设计清楚,把扩展性留好,剩下的让社区来补。
也不是没有问题
-
• ⚠️ 文档写得一般,新手上手曲线有点陡 -
• ⚠️ 有些高级功能藏得很深,不翻源码找不到 -
• ⚠️ 社区 Skills 质量参差不齐,有些根本跑不起来
但瑕不掩瑜,作为一个开源项目,它在架构设计上展现出来的成熟度,确实是很多拿了融资的创业公司都比不了的。
如果你在做 AI Agent 相关的东西,我真心建议花点时间把 Clawdbot 的代码过一遍。不是说要照搬它的实现,而是去理解它为什么这么设计、它踩过哪些坑、它怎么在各种约束下做取舍。这些东西比学会用某个框架的 API 有价值多了。
欢迎留言讨论,点赞,转发。
