 夜雨聆风
夜雨聆风





自然语言处理中的word2vec
Word2Vec 是自然语言处理(NLP)领域中一个里程碑式的技术。它的核心作用,是将离散的词语(如”国王”、”苹果”)映射到一个连续的、低维的实数向量空间中。简单来说,就是为每一个词学习一个稠密的向量(也就是词嵌入),使得语义相近的词在向量空间中也彼此靠近。
它的出现主要是为了解决传统 One-hot 编码的缺陷。One-hot 向量虽然简单,但维度高、稀疏,且最关键的是无法表达词语间的语义相似度(任意两个不同词的 One-hot 向量余弦相似度都为0)。
核心模型:CBOW 与 Skip-gram
Word2Vec 包含两种不同的语言模型架构,它们的目标正好相反,但核心思想都是通过上下文来学习词向量。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
连续词袋模型 (CBOW)
CBOW 模型的目标是在给定某个中心词的上下文词汇时,预测出这个中心词。其训练过程是,将上下文词的 One-hot 向量通过一个共享的输入权重矩阵映射成词向量,然后对这些词向量取平均(或加权和),再通过另一个输出权重矩阵和一个 Softmax 函数,输出词典中每个词作为中心词的概率。训练的目标就是最大化预测出正确中心词的概率。
-
跳字模型 (Skip-gram)
Skip-gram 模型与 CBOW 正好相反。它给定一个中心词,目标是预测它周围的上下文词汇。训练时,将中心词的 One-hot 向量通过输入权重矩阵得到词向量,然后直接用这个向量去预测多个上下文词。由于每个中心词对应多个上下文词,因此模型需要输出多个概率分布,每个分布对应上下文窗口中的一个位置,目标是最大化这些位置上正确上下文词的出现概率。
训练优化技巧
Word2Vec 的训练本质上是一个超大规模(词汇量大小)的多分类问题,直接计算 Softmax 的代价极高。因此,原论文提出了两种高效的优化方法:
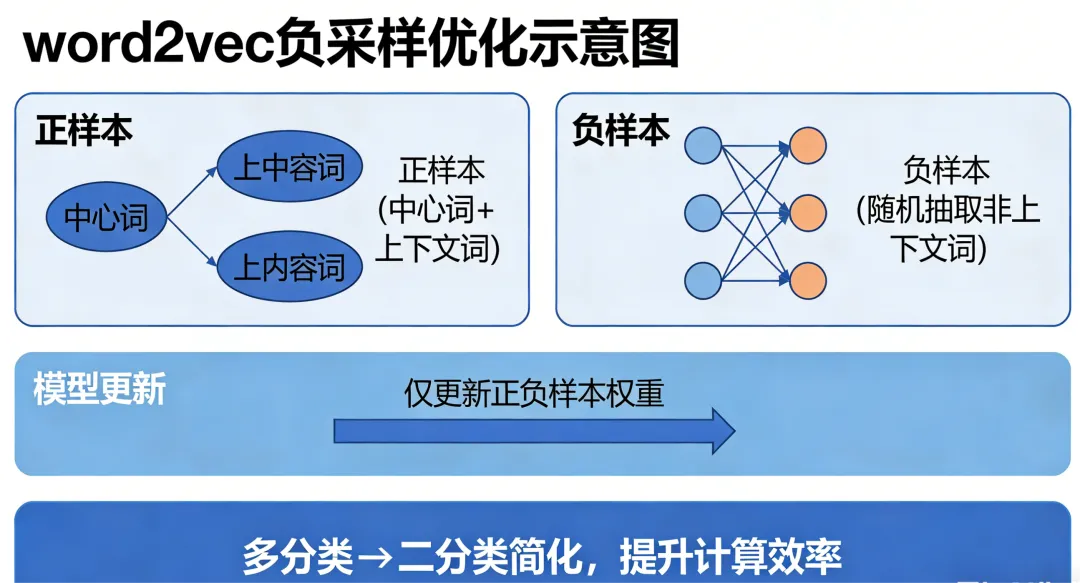
-
负采样 (Negative Sampling):这是最常用的优化技巧。它将多分类问题简化为一系列二分类问题。对于每个训练样本(中心词和上下文词组成的正样本),我们随机从词典中抽取几个词作为负样本(非上下文词)。模型只需要更新这些正负样本相关的权重,而不是整个词汇表,从而极大提升了计算效率。
负采样的核心思想:把“选择题”变成“判断题”
负采样想了一个聪明的办法:我们能不能不做那个复杂的 10 万分类,而是做几道简单的判断题?
-
原问题(多分类):给中心词“苹果”,下一个词是下面 10 万个词里的哪一个?(单选题)
-
新问题(二分类):给中心词“苹果”和一个候选词,请判断这两个词是否真的会在一起出现?(判断题:是/否)
负采样是怎么训练的?
我们拿一个真实的训练样本来举例:
-
训练样本:(“苹果”, “吃”)
-
含义:在我们的文本中,“苹果”和“吃”是挨着出现的(假设窗口大小为1)。
第一步:制造正样本
毫无疑问,(“苹果”, “吃”)这一对是正样本。模型需要学会见到它们时说“是”。
第二步:制造负样本
我们随机从词典里抓几个词出来,跟“苹果”配对。
-
随机抓了“鲸鱼”,组成(“苹果”, “鲸鱼”)
-
随机抓了“跑步”,组成(“苹果”, “跑步”)
-
随机抓了“银行”,组成(“苹果”, “银行”)
这些词在真实文本中几乎不可能跟在“苹果”后面,所以它们是负样本。模型需要学会见到它们时说“否”。
第三步:开始训练(更新权重)
现在,模型的任务变得简单多了。对于给定的中心词“苹果”,它不需要关心那 10 万个词分别的概率是多少。
它只需要面对 4 个简单的判断题(1个正样本 + 3个负样本):
-
Q:(苹果,吃)是真实出现的吗? A:是 -> 更新权重,让这个判断更准
-
Q:(苹果,鲸鱼)是真实出现的吗? A:否 -> 更新权重,让这个判断更准
-
Q:(苹果,跑步)是真实出现的吗? A:否 -> 更新权重,让这个判断更准
-
Q:(苹果,银行)是真实出现的吗? A:否 -> 更新权重,让这个判断更准
-
层次Softmax (Hierarchical Softmax):另一种优化思路,它利用霍夫曼树(一种根据词频构建的二叉树)来代替输出层的 Softmax。原本需要计算所有词的归一化概率,现在只需沿着树的一条路径计算,将计算复杂度从 O(N) 降低到 O(logN),尤其在词频不均时效果很好。
为什么这样能提升效率?
因为模型只需要更新跟这4个词相关的权重。
-
原本:计算 10 万个词的得分,更新 10 万份权重。
-
现在:只计算 4 个词的得分,只更新 4 份权重。
虽然这 4 个词的更新可能不如 10 万个词那么精确,但它的速度提升了上万倍。而且通过反复看大量的训练数据,模型依然能学到非常高质量的词向量
负采样就是:
-
不去算 所有词的概率(太累)。
-
只关注 几个词:一个对的(正样本),几个随机挑的错的(负样本)。
-
让模型在这几个词上学会判断对错。
通过这种“偷懒”的方式,模型用极小的计算代价,达到了原本需要巨大计算量才能实现的学习效果。这就是 Word2Vec 能够在大规模语料上快速训练的秘密武器。
如果只是把每个样本的计算量从 10 万降到几个,但训练样本的总数不变,那么总的“迭代次数”(通常指遍历整个数据集的次数,即epoch)是一样的。但是,总训练时间 = 迭代次数 × 每次迭代的计算量。负采样大幅降低了每次迭代的计算量,所以即使迭代次数不变,总时间也大大缩短。
我们可以用一个简单的数学对比来理解:
假设词典大小 V = 10万,负采样个数 K = 5。
-
原始 Softmax:每个训练样本需要计算并更新所有 10 万个词的权重,计算复杂度约为 O(V)(10万)。
-
负采样:每个训练样本只更新 1 个正样本 + 5 个负样本,共 6 个词的权重,计算复杂度约为 O(K+1)(6)。
速度提升倍数 ≈ 10万 / 6 ≈ 1.67万倍。
即使你要跑同样的 epoch 数(比如 5 遍语料),原来需要 5 天,现在可能几分钟就完成了。这就是为什么负采样成为 Word2Vec 训练中必不可少的“加速器”。
为什么不是增加迭代次数?
负采样的目标不是减少 epoch 数,而是让每个 epoch 跑得更快。实际上,训练 Word2Vec 通常只需要几个 epoch(比如 3-5)就能得到不错的词向量,因为语料中的共现信息已经足够丰富。如果使用原始 Softmax,可能连一个 epoch 都难以在合理时间内完成。
类比理解
-
原始 Softmax:就像每次考试要回答 10 万道题,然后老师根据所有题目的答案来调整你的知识。
-
负采样:每次考试只回答 6 道题(1 道必对 + 5 道随机干扰),老师只根据这 6 道题来调整你的知识。虽然考试次数(epoch)一样,但每次考试时间从一天缩短到一分钟,总体时间大幅下降。
所以,你的直觉是正确的:迭代次数(epoch)不变,但每次迭代的“成本”急剧下降,从而实现了高效训练。
