百万 PDF 精确定位:一文看懂 RAG 的数据准备
在上一篇,我们鸟瞰了 RAG 那条由五大齿轮死死咬合而成的精密流水线。今天,我们将戴上绝缘手套,一头扎进这座冰冷严苛的数字重工厂。
我们要死磕最前面、也最容易让人抓狂崩溃的两道前菜:数据准备与检索。
你可能觉得不屑一顾:找个文件能有多难?不就跟在电脑里“Ctrl+F”搜个关键词一样吗?
如果系统在这前两步找错了“参考资料”,找歪了答案的源头,哪怕你后面花大价钱接的是世界上最聪明的一万个最高阶模型,它也只能拿着一本《母猪的产后护理》,一本正经且极度流畅地回答你关于“公司明年营销预算降本”的问题。
在厂商精美的发布会上,喂给 AI 学习的数据全是排版干净的纯文本。但在企业真实环境中,堆满的数字资产简直是一场灾难:带水印的扫描本、排版错乱的表格、掺杂乱码的陈年旧稿。
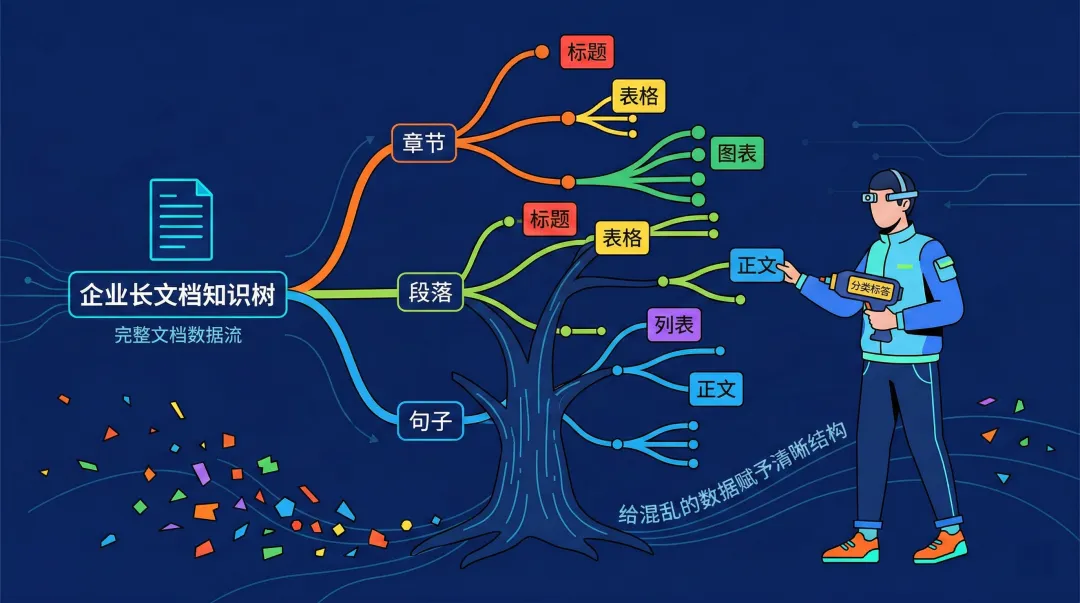
如果直接把这些乱码文件倒给大模型,它自然无法解析。所以,RAG 第一关的铁律是:必须把长篇大论的非结构化数据彻底拆解重构。
工程师将这道工序称为“切块(Chunking)”。这是 RAG 的第一重博弈:
这是最简单的底层打法,比如“每满 500 字切一刀”。但在实战中这极其要命,因为它极易把一句包含因果关系的核心语句拦腰斩断,导致大模型在检索时只能拿到半截没头没尾的话。
-
进阶打法:“语义层级解析(Semantic Chunking)”
这是目前工业界的核心准则。高端系统用视觉模型顺着文档的“章节 -> 标题 -> 段落”骨骼脉络去切分。这样切出来的每一块文本碎片,都携带了清晰的层级标签(例如:`【2023年财报 -> 第二章:海外战区 -> 第三小节:东南亚遇挫 -> 正文】`)。大模型在海量数据中捞到这一小段时,绝不可能张冠李戴。
完成切分后,系统会将这些人类语言文本转化为机器能高速检索的多维数学坐标系(Embedding),并存入专做高并发搜索的“向量数据库(Vector DB)”中。
巨大的数字弹药库建好了。现在用户随手敲了一句极度口语化的提问:“那公司要是换成明年,还能盈利吗?”
如果检索系统拿着原话去字库里死板比对,绝对查不到任何有价值的信息。为了像资深调查员一样去“查案”,业界祭出了三大武器:
第一把武器:意图重写(Query Rewrite)
绝不能拿人类顺嘴的口语原话直接搜!系统前台会外挂一个小模型。它通过分析上下文关系,瞬间把你没头没脑的“换成明年呢”,严丝合缝地改写成标准搜索指令:“寻找并提取 2024 年度本公司主营业务净利润预测数据”。有了精确的弹药,大炮才绝不可能打偏。
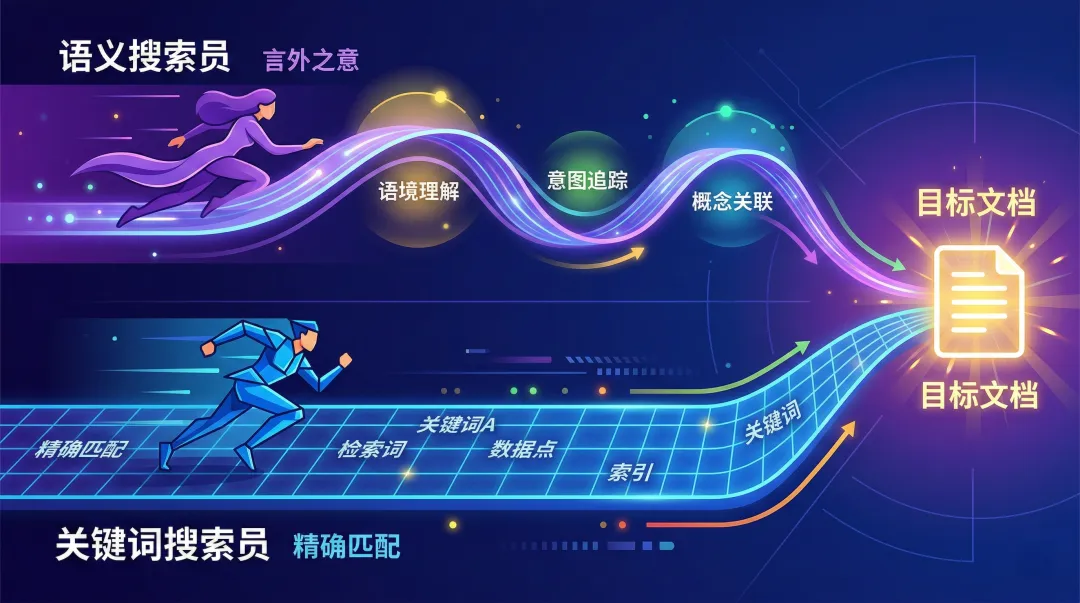
第二把武器:混合双引擎 (Hybrid Search)
单纯匹配字符早已不够看,目前的顶配 RAG 都在开着双重引擎:
-
向量检索(Dense Search):精通发散的语义联想,专门负责找“言外之意”。你搜“裁员起火”,它还能像撒网一样把暗中提及“优化员工结构”、“部门舆情着火”的资料全捞回来。
-
关键词检索(BM25 Sparse):专门负责死磕字符原貌。如果你要查一份极冷门的内部仪器文件,连代号都是“TX-909”这样的乱码,它能死死咬住这串字符串,把唯一的一页绝密图纸揪出来。
这两股逻辑互补的双引擎合流,就是目前搜查命中率触及天花板的混合检索矩阵。
混合双引擎虽然捞回来了多达 20 块疑似黄金的碎片,但里面难免混入刚好撞上关键词、前后文却逻辑错乱的烂段落。为了省下昂贵大模型的算力成本费用,必须在资料出门前设下最后一块隔离板。
系统会调用一位被称为“交叉重排(Cross-Encoder Reranker)”的轻量专职评估模型。它利用强劲的推理算力,疯狂比对问题与每个参考片段的逻辑紧密关联性。它会剔除掉低等嫌疑选项,极度浓缩出真正的“最佳底气前 3 名”。
有了结构精细的数据底图,再加上严酷的混搜引擎与重排网筛过滤,给大模型找“优质参考书”的大工程圆满交付。
有了它,直接递给大模型去回答就行了?越出众的大模型越想发散。 下一篇,我们将直击增强与生成阶段的前沿防爆战区,看工程师到底是如何约束它的发散妄想的。
回想一下,在你平时工作的企业后台或个人知识笔记里,现在的搜索系统是不是像一座“找张截图比登天还难的填埋场”?
👇 诚挚欢迎在评论区开麦吐槽你的痛苦旧时代搜索血泪史!
觉得今天的硬核解析极度解渴?千万别忘了点个 「喜欢」 与 「转发」。明天我们将揭开 RAG 给大模型洗脑防撒谎的核心秘术!
 夜雨聆风
夜雨聆风