 夜雨聆风
夜雨聆风





说好的爬虫源码来了:鸡精版百度图片爬虫,想爬啥图自己改关键词
上篇写了接私单的血泪史,200块换三天觉。
今天不废话,直接上干货。
不过先说明白:这个爬虫不是直接搜图的,你得先在百度图片里搜好关键词,然后把地址栏的链接复制给它。
比如你想爬“猫”,就去百度图片搜“猫”,复制网址,贴进来,它就开始干活。
这个爬虫能干啥?
给你一个网址,它能把网页里所有的图片扒下来,自动存到你电脑里。
不管是百度图片、必应搜索,还是哪个摄影网站、壁纸站,只要图片是<img>标签里的,它都能给你揪出来。
而且加了三个贴心功能:
– 自动滚动加载:有些网站要一直往下滑才出图,它帮你滑到底
– 多线程下载:一次下3张,不用一张张等,电脑配置高的,可以多开线程
– 支持base64图片:有些图是内嵌的,也能存
说白了,这就是一个“懒人版图片收割机”。
代码原理分段讲解(不想看原理的可以直接跳到“运行效果”)
代码由两个文件组成,我们先讲它们各自干了什么。
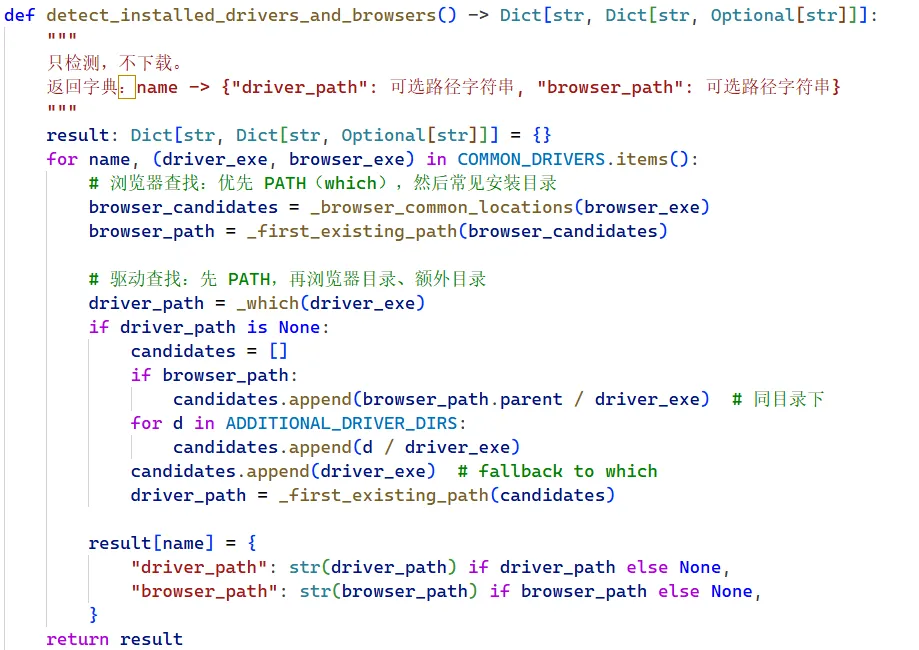
一、Browser_Type.py:自动找浏览器驱动
这个文件的核心功能是:自动检测你电脑里装了哪些浏览器,并且找到对应的驱动文件(chromedriver.exe等)。
为什么要自动找?
因为用 Selenium 操控浏览器需要驱动,以前得自己下载、配置环境变量,很麻烦。这个脚本会扫描你的 PATH 环境变量、浏览器安装目录、下载文件夹,看驱动在不在。如果在,就直接用;不在就报错,但至少告诉你缺哪个。
原理很简单:它定义了一个常见浏览器的映射表,然后依次在几个常用目录里找。比如Chrome的驱动可能在C:\Program Files\Google\Chrome\Application或者C:\WebDriver下。找到了就返回路径,找不到就返回 None。
代码截图 :Browser_Type.py(检测浏览器和驱动)

二、Image_crawler.py:主程序,干活的
这个文件里定义了一个类image_downloader,所有核心功能都在里面。我们拆开看。
1. 初始化(__init__)

创建对象时需要传三个参数:
– sleep_time:滚动页面时的等待时间,给网页加载留点时间。
– img_format:保存图片的格式,默认 png。
– save_path:图片保存的文件夹。
2. 启动浏览器(browser_init)


根据你电脑里装的浏览器,自动选择一个可用的(优先 chrome、edge、firefox、safari)。它会创建一个浏览器对象,并设置一些参数:
– -headless=new:无头模式,浏览器在后台运行,不会弹出窗口。
– 随机选一个 User-Agent,伪装成不同浏览器,减少被反爬的概率。
– 禁用日志,避免刷屏。
3. 滚动加载(get_image_urls)
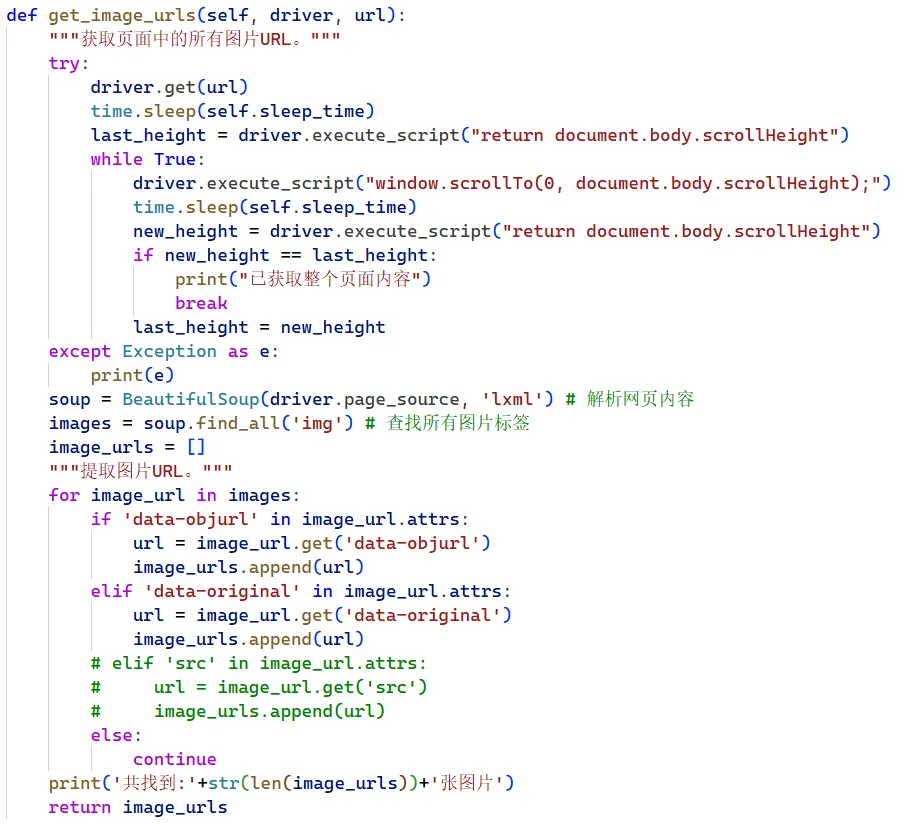
这一步是关键。很多图片网站是“懒加载”的,必须滚动页面才会加载更多图片。代码会模拟滚动到底部,检查页面高度是否变化,直到滚不动了才停。
为什么要滚动?
因为百度图片一开始只显示几十张,往下滑才会加载更多。如果不滚动,只能抓到第一屏的图。
4. 提取图片 URL
滚动完成后,用 BeautifulSoup 解析页面的 HTML,找到所有<img>标签。但是很多网站的图片地址藏在各种属性里,比如data-objurl、data-original。代码会优先找这些属性,因为这些才是高清大图的真实地址。如果都没有,才考虑src属性(但默认注释掉了,因为很多小图质量差)。
5. 保存图片(image_save)


拿到图片地址列表后,开启一个线程池(默认3个线程),同时下载多张图片,速度翻倍。

下载函数里处理了三种图片地址格式:
– https:// 开头的:直接 requests 下载。
– //img.xxx.com这种:自动补上 https: 再下载。
– data:image/base64 这种:内嵌的图片数据,用 base64 解码后保存。
6. 关闭浏览器(close_browser)

下载完记得关掉浏览器,释放资源。
三、运行效果:
双击Image_crawler.py,或者命令行里输入 python Image_crawler.py。
然后它会问你:
请输入目标连接:粘贴刚才复制的百度图片链接,回车。
请输入图片保存路径:直接回车,默认在当前文件夹下创建 images 文件夹;也可以自己输一个路径,我这里是:E:\crawler\images
请输入图片保存格式(默认png):直接回车就是 png,想存 jpg 就输 jpg


接下来,你就看着它表演吧:
-
自动启动浏览器(无头模式,你看不到界面,但它在后台干活)
-
滚动页面,加载图片
-
找到所有图片,开始下载
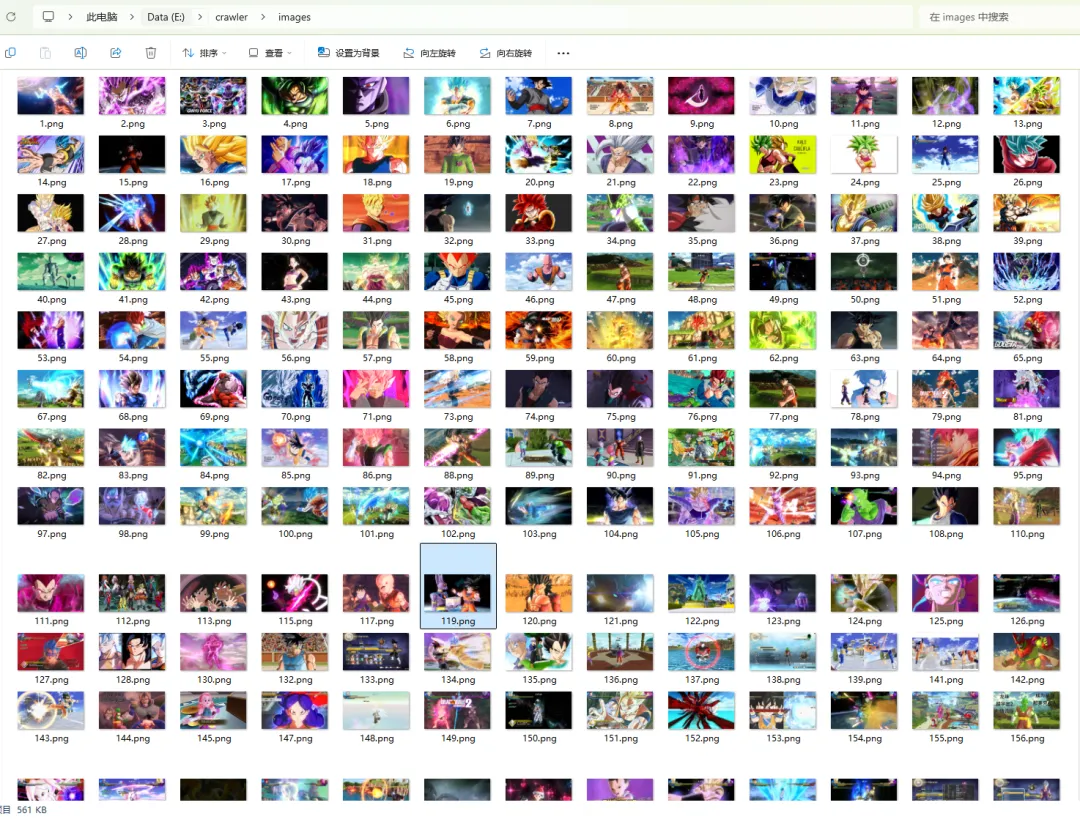
运行效果截图:
【运行效果截图:命令行输出,显示找到多少张图、下载完成】
打开保存的文件夹,图片整整齐齐躺着。
代码里藏的几个小心机(原理总结)
-
自动找驱动:不用手动下载 chromedriver,省去配置环境的麻烦。
-
滚动到底:模拟人类操作,抓全所有图片。
-
多线程下载:快,但不会太快(3个线程刚好,太多会被网站封)。
-
兼容多种图片地址:base64、相对路径都搞定。
-
无头模式:后台运行,不打扰你干别的。
注意事项(血的教训)
-
别贪心:一次爬几百张就行,别把人家服务器搞崩了,小心 IP 被封。
-
别商用:爬下来的图片自己学习用可以,拿去卖钱可能吃官司。
-
如果报错“找不到驱动”:说明你的浏览器驱动没装。去浏览器官网下载对应版本的驱动,放到
C:\WebDriver文件夹,或者直接扔到和脚本同目录。 -
如果没图:可能网站结构变了,代码里的属性名需要调整。比如百度图片可能改用其他属性存图,可以自己打开网页 F12 看看。
毒鸡汤:学会这个能接单吗?
能,但别指望靠它发财。
这种通用爬虫,网上开源的一大把,客户不会花大钱买。
但你可以把它当成练手工具,学会了之后,遇到真正复杂的定制需求,才有底气报价。
比如客户要爬电商评论、爬公众号文章、爬知乎回答……这些才是真正值钱的单子。
手里有技术,心里才不慌。
哪怕现在慌得要死,也得假装不慌。
我是用Python看清职场的90后外包打工人。
月薪四千,还在撑。
你呢?爬了什么好玩的图?评论区晒出来。
懒人福利:exe版直接下载
我已经打包成了一个.exe的执行文件,开箱即用,免去python的环境配置和依赖库的下载。不想折腾代码的朋友,关注,私信我,直接发文件。
