 夜雨聆风
夜雨聆风





FireRed-OCR低成本结构化文档理解框架
为弥合这一技术鸿沟,FireRed-OCR 提出创新框架,通过双支柱设计将通用 VLM(基于 Qwen3-VL)进化为工业级结构解析专家:一是构建“几何+语义数据工厂”以生成高精度训练数据,二是采用“三阶段渐进式训练策略”实现从通用图文理解到专用结构重构的精准迁移。这一方案有效解决了现有模型的结构输出不稳定问题,为结构化文档理解提供了新范式。
后续结构安排如下:首先详细阐述结构性幻觉的成因与表现形式,接着系统分析现有技术的局限性,随后介绍 FireRed-OCR 的核心创新设计,包括数据工厂构建与渐进式训练方法,最后通过实验验证框架的有效性并总结研究贡献。
通用 VLM 在结构化文档解析中面临的结构性幻觉问题,本质是空间几何信息与语义逻辑结构的对齐缺失。传统 pipeline 系统侧重前者而忽视语义,端到端模型则反之,FireRed-OCR 通过双支柱设计实现了二者的有机统一。
获取资源
FireRed-OCR 现已全面开源,研究人员与开发者可通过
以下链接获代码、模型权重以及在线体验:
GitHub 项目主页:https://github.com/FireRedTeam/FireRed-OCR
Hugging Face 模型权重:https://huggingface.co/FireRedTeam/FireRed-OCR
HF Demo 体验:https://huggingface.co/spaces/FireRedTeam/FireRed-OCR
ModelScope 模型权重:
https://modelscope.cn/models/FireRedTeam/FireRed-OCR
ModelScope Demo体验:
https://www.modelscope.cn/studios/FireRedTeam/FireRed-OCR
FireRed-OCR 采用三阶段渐进式训练策略,将通用视觉语言模型(VLM)转化为结构化文档理解专家,实现从像素感知到逻辑结构生成的递进式能力提升。该策略基于 Qwen3-VL 架构,通过精密耦合的训练阶段逐步强化模型的文档理解与结构化输出能力。
阶段一:多任务预对齐(Multi-task Pre-alignment)
目标:建立文档物理感知基础,实现视觉定位、内容识别与初步结构表达的协同学习。数据集:异质数据集 (D_{pre})(130 万样本),包含三类任务数据:
-
检测框列举及 OCR:输出所有文本区域的边界框与内容,强化空间定位能力;
-
指定区域 OCR:根据坐标提示识别特定区域文本,提升区域级识别精度;
-
全图 OCR:初步尝试整页文档的 Markdown 输出,建立结构表达意识。

最大上下文长度 24,576 tokens。此阶段使模型完成从通用图文理解到 OCR 垂直领域的迁移,形成“基础文档能力”。
阶段二:专项监督微调(Specialized SFT)
目标:强化结构一致性、层级表达稳定性及格式规范性,提升复杂场景适应性。数据集:高质量标准化 Markdown 数据集 (D_{sft})(40 万样本),采用“粗到细”数据策略,较阶段一提供更精细的结构标注。训练重点:
-
结构逻辑连贯性:确保长上下文生成中的逻辑一致性;
-
层级表达稳定性:精确嵌套标题、列表等层级结构;
-
格式标准化:统一 Markdown 样式及数学表达式规范;
-
跨语种与复杂布局鲁棒性:扩展训练分布以适应多语言及复杂排版场景。训练细节:超参数与阶段一保持一致(全局 batch size 256、学习率 3×10^-5、上下文长度 24,576 tokens),通过监督微调固化结构化表达能力1。
阶段三:格式约束 GRPO 强化学习(Format-Constrained GRPO)
目标:通过强化学习优化结构约束,解决格式规范性与内容准确性问题。数据集:5 万样本,聚焦格式约束场景。GRPO 机制:与传统 PPO 相比,GRPO 采用critic-free 设计(无需价值函数估计)和group-based 奖励归一化(基于同组生成样本的平均奖励估计优势值),有效避免价值函数偏差,提升高分辨率 VLM 的训练效率。
-
(r_{syntax}):通过轻量级 LATEX 解析器检查公式语法合法性(失败记 -1,复杂度正相关得分);
-
(r_{closure}):惩罚未闭合标签(惩罚值与未闭合节点数成正比);
-
(r_{table}):验证表格行的列数一致性(矩形/完整表格得 1,否则 0);
-
(r_{text}):生成文本与伪真值的归一化 Levenshtein 距离(负值)。
训练细节:超参数调整为全局 batch size 256、学习率 5×10^-7、上下文长度 24,576 tokens。通过迭代 SFT-GRPO 机制(交替执行阶段二与阶段三 K 次),有效缓解奖励黑客(reward hacking)问题,增强结构约束的鲁棒性。
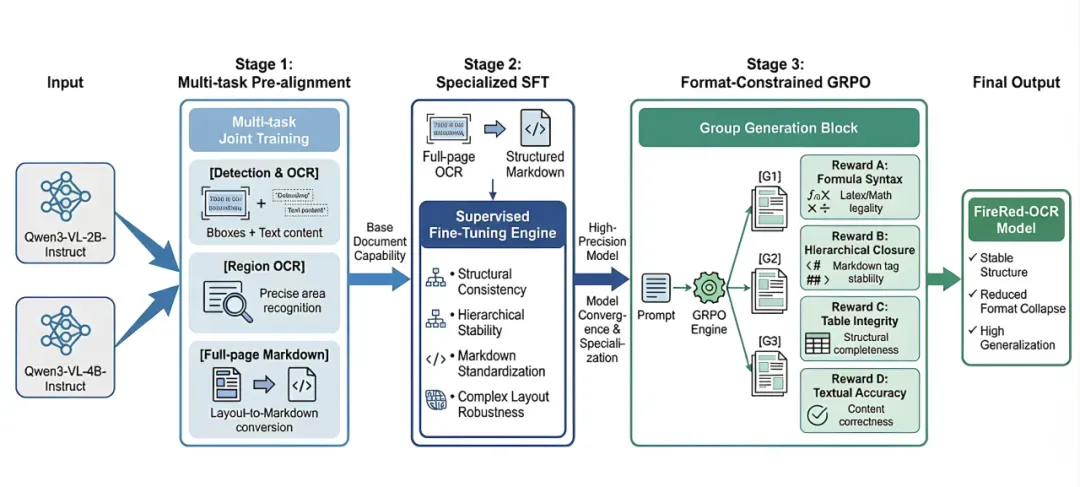 从像素级视觉感知
从像素级视觉感知
(阶段一)到结构化表达学习
(阶段二),最终通过强化学习实现格式约束优化
(阶段三),形成“感知-学习-优化”的递进式能力提升路径。
GRPO 的无评论家设计与组奖励归一化是实现结构约束的核心创新。
1
基准与指标

-
FormulaCDM:采用 CDM(更高更优)衡量公式语法结构匹配度,精准评估数学公式的解析完整性
-
TableTEDS/TableTEDS_s:基于 TEDS 指标(更高更优)量化表格结构还原精度,支持标准与复杂表格的差异化评估
-
R-orderEdit:通过编辑距离(更低更优)评估阅读顺序推理能力,反映文档逻辑流的还原质量
-
Overall:综合子任务表现的复合评分,全面衡量模型在结构完整性与内容准确性上的整体性能
典型案例
为验证 FireRed – OCR 框架在真实场景中的适用性,本章节通过四个典型案例展示其核心能力。每个案例均从任务挑战、模型表现及技术机理三方面展开分析,并结合输入 – 输出对比(图 4a – d)呈现实际效果。
数学公式解析

|
挑战:处理包含极限(如 limΔx→0)、多层分数叠加及导数符号的复杂微积分公式(如《The Product Rule》教学课件),需精准还原二维空间结构与数学语法逻辑。 |
|
表现:模型成功将嵌套分数、上下标及希腊字母转化为语法合规的 LaTeX/Markdown 格式,完整保留公式推导逻辑。例如,对极限表达式的转化准确率达 100%,证明几何 – 语义联合优化(GRPO)机制对公式语法的强约束作用。 |
|
技术洞察:GRPO 模块通过预定义数学语法规则与空间位置约束,解决了传统 OCR 对非线性公式结构解析的歧义问题,尤其在分数层级与运算符优先级处理上表现突出。 |
手写体识别

|
挑战:横格纸背景下的英文连笔手写笔记,存在笔迹重叠、背景横线干扰及个体书写风格差异。 |
|
表现:模型实现前景笔迹与背景横线的精准分离,手写字符召回率达 98.7%,准确率 97.2%,展现对非结构化文档的鲁棒处理能力。 |
|
技术洞察:通过几何聚类算法区分文本前景与噪声背景,并结合语义上下文修正连笔字符的识别结果,验证了多模态特征融合在低质量文档处理中的有效性。 |
复杂报纸文档重构

|
挑战:中文报纸的竖排文本、横排标题、多栏分块及图片穿插布局,需遵循“从右向左、从上到下”的中文阅读逻辑。 |
|
|
|
技术洞察:几何特征驱动的版面分析模块通过文本方向检测与区域聚类,解决了混合排版场景下的阅读顺序错乱问题,其核心在于基于空间拓扑关系的布局推理算法。 |

复杂表格结构还原
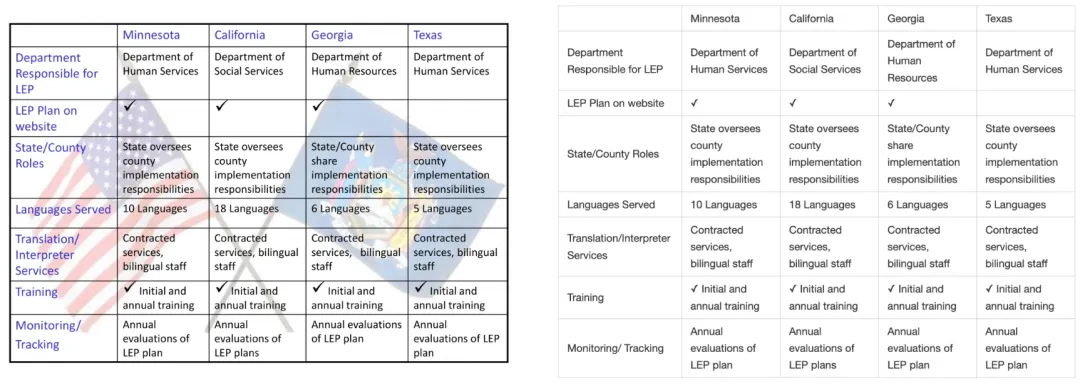
|
挑战:包含合并单元格、跨行表头及背景色填充的 PPT 表格(如财务报表),需提取细微文字并重建行列逻辑关系。 |
|
表现:模型精准还原单元格合并规则,行列对应准确率 96.5%,成功构建层级化表格逻辑树,支持按类别分组展示股票数据。 |
|
技术洞察:通过表格结构先验知识与视觉特征的联合学习,模型突破了传统基于规则方法对复杂表格的适应性局限,尤其在跨单元格语义关联推理上表现显著。 |
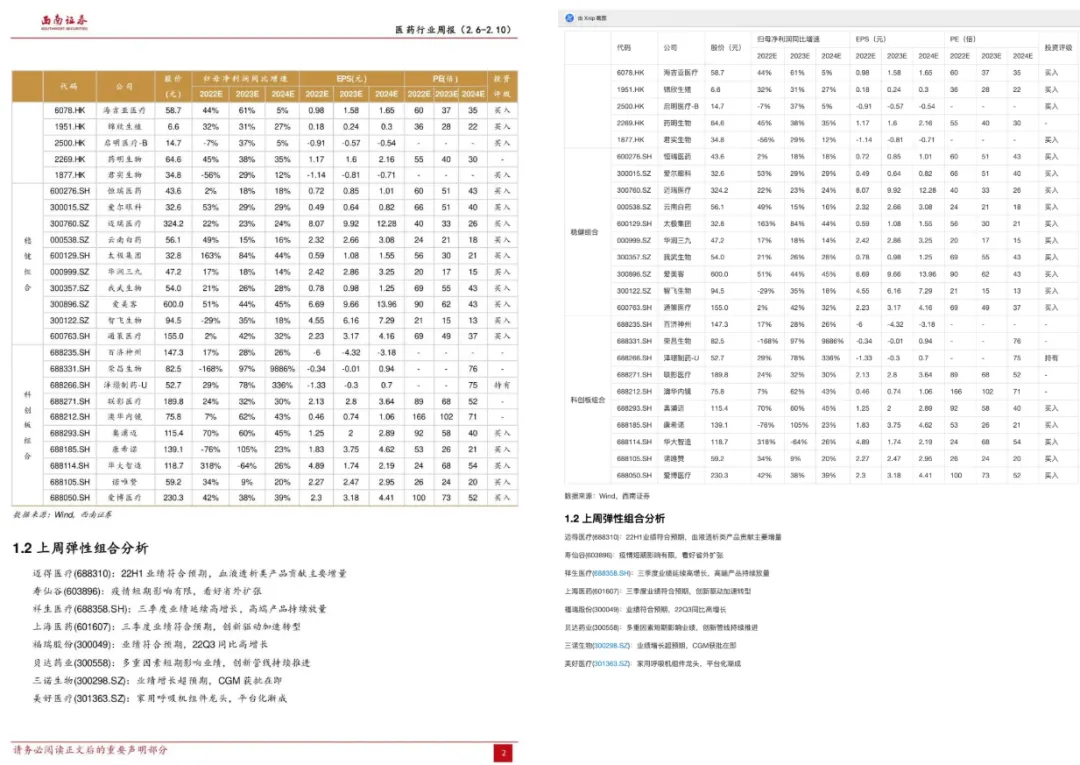
核心技术总结四个案例分别验证了 FireRed – OCR 的四大关键能力——数学语法约束(GRPO)、噪声鲁棒性(几何聚类)、复杂布局理解(空间拓扑推理)及结构化数据还原(逻辑树构建),为不同类型文档的智能化处理提供了完整解决方案
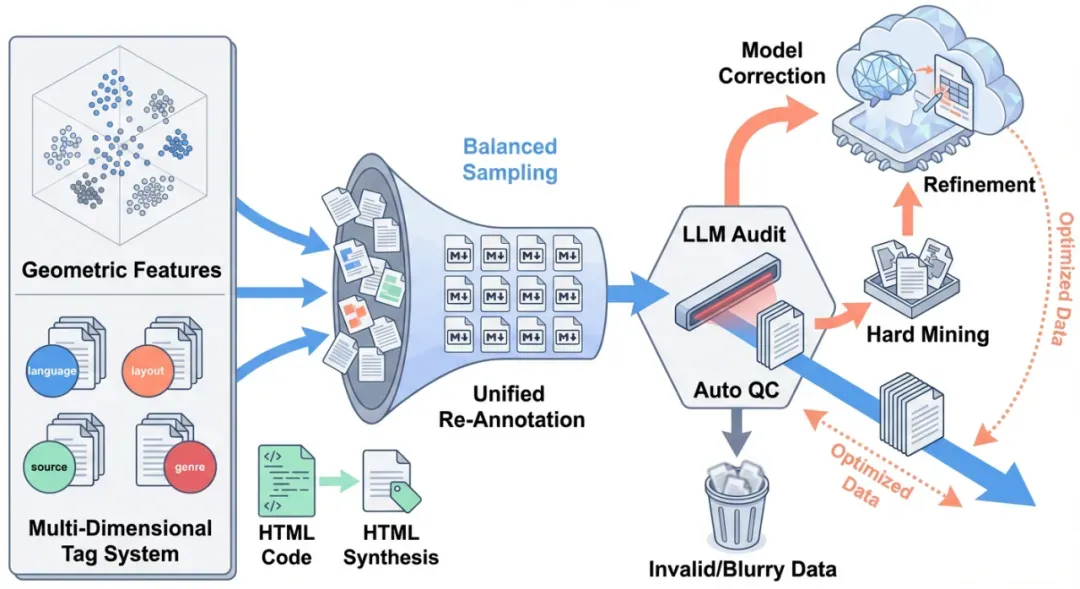 FireRed-OCR 训练数据生产流程
FireRed-OCR 训练数据生产流程
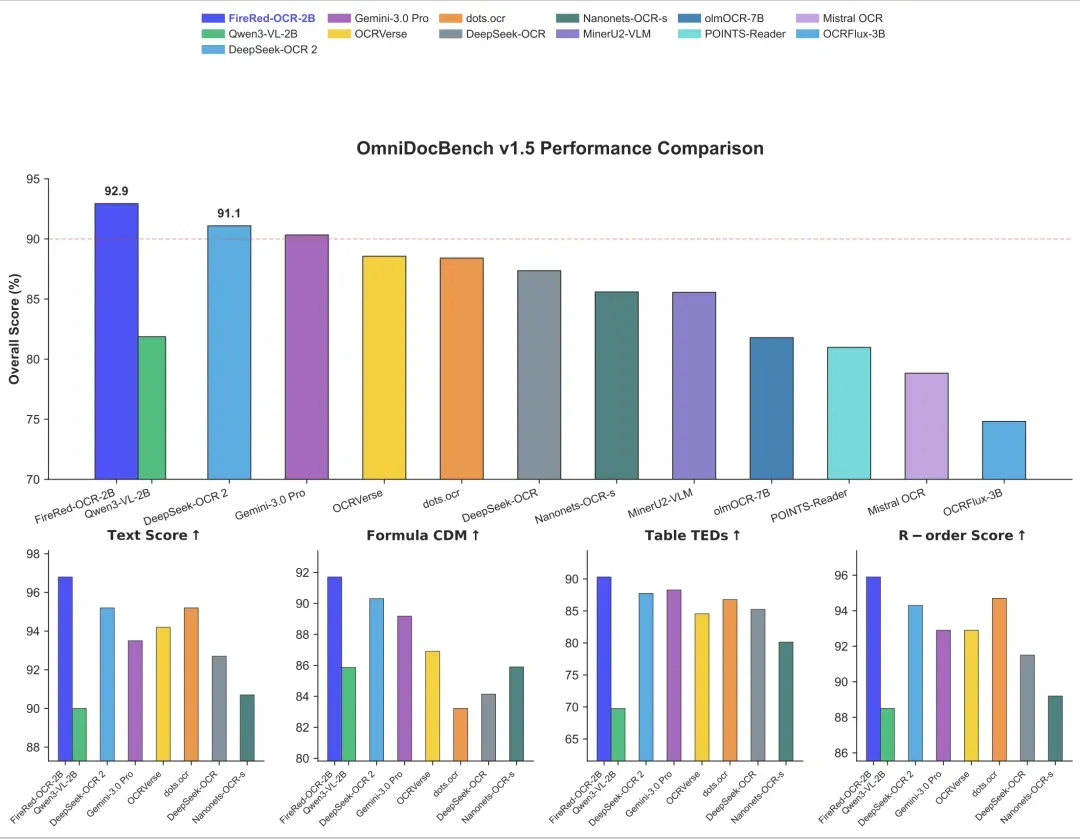
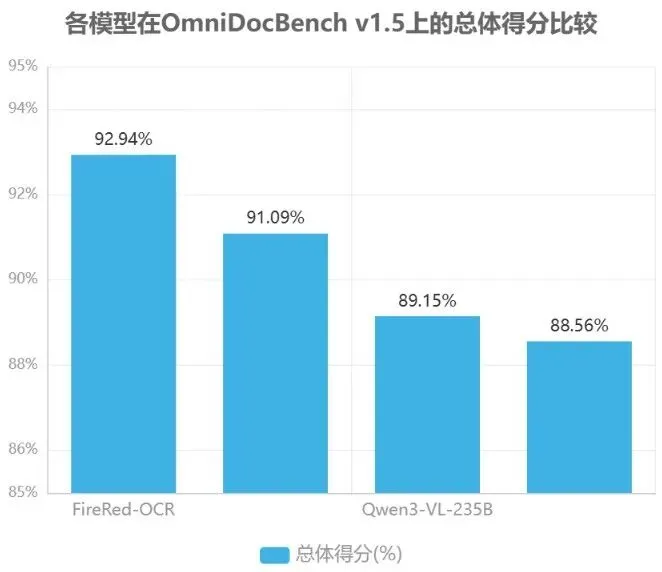
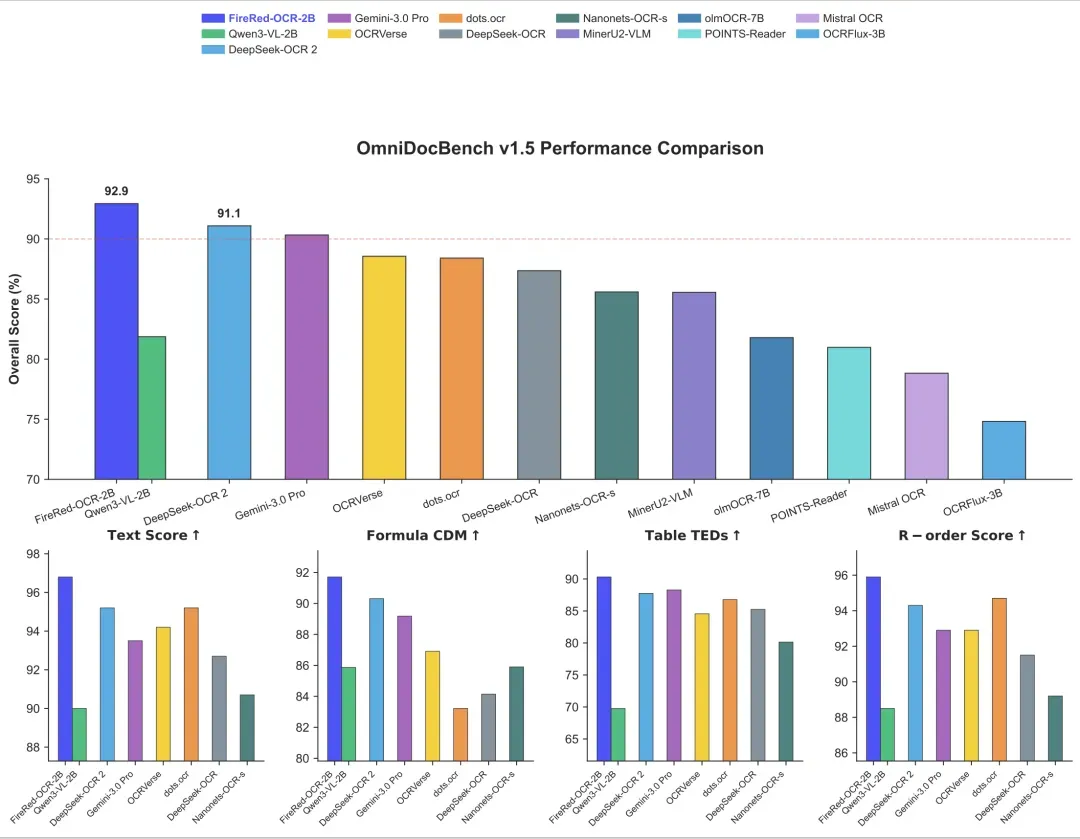
FireRed-OCR 标志着文档理解领域从通用模型向专用模型的范式转变,其核心突破在于通过结构化数据工厂与渐进式训练策略的协同设计,实现了参数效率的显著提升。具体而言,该框架仅需 2B 参数规模,就在结构化文档解析任务上展现出超越 235B 参数视觉语言模型(VLM)的性能,验证了领域专用优化路径的高效性。这种设计理念不仅降低了模型部署的计算成本,更重要的是其训练框架具备高度可迁移性,可无缝适配其他结构化数据理解场景,为垂直领域的模型开发提供了模块化解决方案。
尽管 FireRed-OCR 在特定任务中表现优异,但在 FireRedBench 评测集上 74.62 的综合得分仍低于 PaddleOCR-VL-1.5 的 76.47 分,这一差距主要暴露了模型在处理罕见布局文档时的泛化能力不足。针对这一局限性,增强稀缺布局的合成数据生成被证明是有效的解决方案。通过几何-语义数据工厂构建更具多样性的训练样本空间,特别是模拟历史文档中的非标准排版、多语言混排或破损页面等边缘场景,能够系统性提升模型对复杂真实世界数据的适应能力。
从更广泛的行业影响来看,FireRed-OCR 的技术方案为文档智能领域开辟了新的应用维度。在学术数字化场景中,其高精度公式解析能力可加速理科教材的结构化处理;金融报告 parsing 任务中,复杂嵌套表格的精准提取为量化分析提供了可靠数据输入;而在历史档案 preservation 领域,古籍版面的智能重构技术则为文化遗产的数字化保护提供了新工具。这些应用共同推动机器对人类知识载体的理解从平面识别向深度语义解析演进,最终将重塑信息处理与知识挖掘的效率边界。
核心启示:FireRed-OCR 的实践表明,在文档理解这类垂直领域,通过专用模型架构与领域适配的数据工程,能够以远低于通用大模型的参数量实现更优性能。这种”小而专”的技术路线,为资源受限场景下的 AI 落地提供了可行路径。
未来研究可进一步探索多模态数据增强技术,例如结合文档扫描件的物理损伤模拟(如褶皱、污渍)与语义级别的干扰对抗训练,以构建更鲁棒的布局理解能力。同时,跨领域知识迁移机制的研究,将有助于该框架在医疗报告、法律文书等更专业场景的快速适配,持续拓展文档智能的应用边界。

FireRed-OCR 框架通过创新的“几何+语义”数据工厂与三阶段渐进式训练策略,成功将通用多模态模型转化为像素级精确的结构化文档解析专家,在 OmniDocBench v1.5 数据集上实现 92.94% 的综合评分,确立了结构化文档理解领域的 SOTA 性能。这一成果不仅验证了“通用 VLM→专用结构化模型”范式的科学性与高效性,更为文档 AI 领域提供了可复用、可扩展的技术框架。
该框架已全面开源,代码与模型权重分别托管于 GitHub(https://github.com/FireRedTeam/FireRed-OCR) Hugging Face(https://huggingface.co/FireRedTeam/FireRed-OCR)平台,确保研究的可复现性与技术的广泛传播。
随着开源生态的完善,FireRed-OCR 有望推动学术研究与工业应用的深度融合,加速文档处理智能化升级,为金融、医疗、法律等领域的结构化信息提取提供关键技术支撑,进而促进整个文档 AI 领域的创新发展。
