 夜雨聆风
夜雨聆风





BettaFish源码解析(三):GraphRAG知识图谱
如何从Agent讨论中提取知识?
前言
在前两篇文章中,我们分别讲解了BettaFish的整体架构和Agent论坛机制。这两个是BettaFish协作的基础。
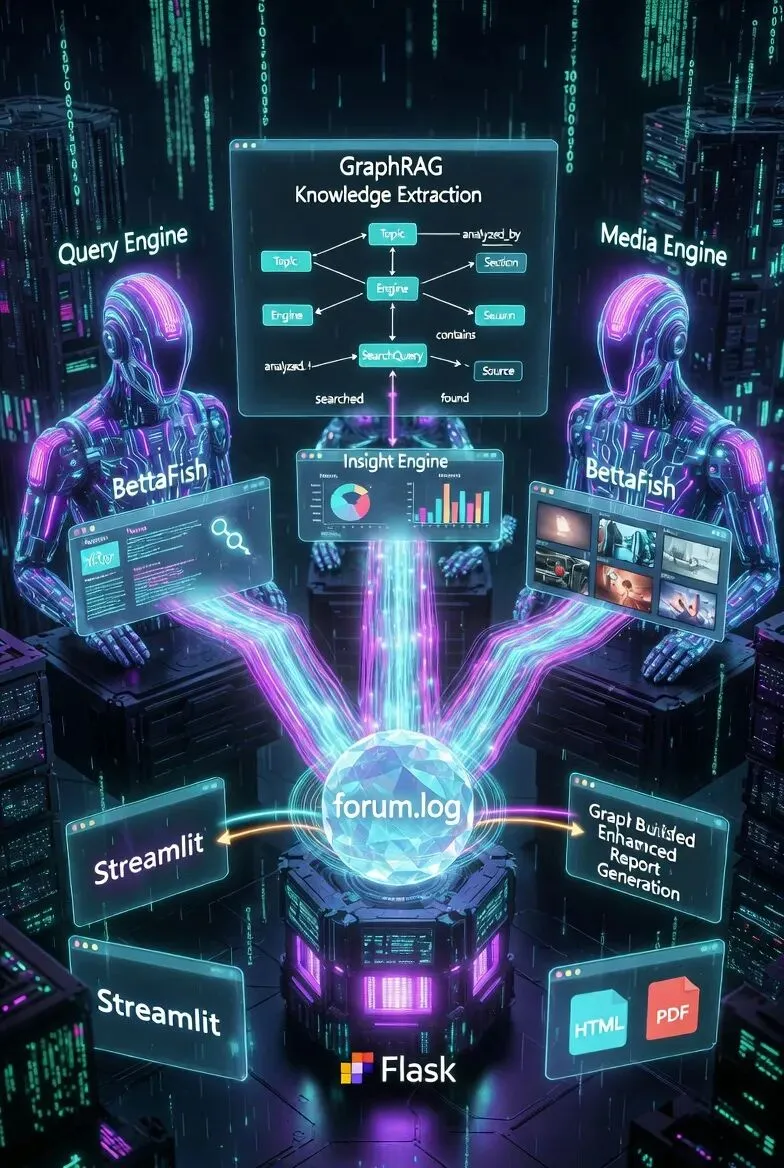
但Agent们讨论了这么多内容,如何”提炼知识”并用于报告生成呢?这就是BettaFish的第三大创新——GraphRAG(Graph Retrieval-Augmented Generation)知识图谱。
本文将深入解析GraphRAG的核心设计,回答一个核心问题:
如何从Agent的讨论中自动提取实体关系,构建知识图谱,并用于增强报告生成?
一、GraphRAG的核心思想
1.1 为什么需要知识图谱?
在传统的RAG(Retrieval-Augmented Generation)中,通常的做法是:
❌ 传统做法用户提问 → 向量数据库搜索(语义匹配)→ 获取文档片段 → 生成回答问题:- 语义搜索可能找不到"隐式关系"- 无法理解Agent之间的"观点冲突"- 难以结构化方式回答"对比分析"类问题
BettaFish的方案:
✅ BettaFish做法Agent讨论 → 实体关系提取 → 图谱构建 → 结构化查询 → 增强报告生成优势:- 显式关系:Agent A"同意"Agent B的观点,这是明确的边- 多维关联:基于engine、section、search_query等多维度- 可解释性:可以清晰展示"为什么得出这个结论"
1.2 GraphRAG vs 传统RAG
| 特性 | 传统RAG | BettaFish GraphRAG |
|---|---|---|
| 数据来源 | 非结构化文档 | 结构化State + Forum日志 |
| 关系提取 | 语义隐式 | 显式明确(analyzed_by/contains) |
| 查询方式 | 向量语义匹配 | 图谱结构化查询(多条件) |
| 可解释性 | 低(黑盒) | 高(可追踪推理路径) |
二、图谱数据结构设计
2.1 核心数据模型
BettaFish的图谱采用简单的节点-边(Node-Edge)模型,非常清晰:
# ReportEngine/graphrag/graph_storage.py@dataclassclassNode:"""图谱节点"""id: str# 唯一标识type: str# 节点类型name: str# 节点名称attributes: Dict[str, Any] # 扩展属性@dataclassclassEdge:"""图谱边"""from_id: str# 起始节点IDto_id: str# 目标节点IDrelation: str# 关系类型weight: float=1.0# 边权重attributes: Dict[str, Any] # 扩展属性
为什么这么设计?
-
简单粗暴有效:不引入复杂的图数据库,Python对象即可
-
扩展性好:attributes字段可以存储任意元数据
-
兼容前端:提供
label和properties两个属性
2.2 节点类型(5种)
BettaFish定义了5种核心节点类型:
| 节点类型 | 说明 | 示例 |
|---|---|---|
| topic | 用户查询主题 | “武汉大学舆情” |
| engine | 分析引擎来源 | QueryEngine, InsightEngine, MediaEngine |
| section | 报告段落/章节 | “1. 舆情现状分析” |
| search_query | 搜索关键词 | “2023年历史数据” |
| source | 信息来源URL | “https://weibo.com/…” |
2.3 关系类型(4种)
同样定义了4种核心关系类型:
| 关系类型 | 说明 | 方向 | 示例 |
|---|---|---|---|
| analyzed_by | 主题由引擎分析 | Topic → Engine | “武汉大学舆情”被QueryEngine分析 |
| contains | 引擎包含段落 | Engine → Section | QueryEngine包含”舆情现状”章节 |
| searched | 段落触发搜索 | Section → SearchQuery | “舆情现状”章节触发了”历史数据”搜索 |
| found | 搜索发现来源 | SearchQuery → Source | “历史数据”搜索找到了”微博”来源 |
三、图谱构建器:如何从讨论中提取知识?
3.1 核心设计原则
BettaFish的GraphBuilder有一个非常重要的设计原则:
基于结构化数据构建图谱,无需LLM进行实体/关系提取
这是与传统GraphRAG最大的不同!
# ReportEngine/graphrag/graph_builder.pyclassGraphBuilder:""" 知识图谱构建器 基于已有的结构化数据(State JSON、Forum 日志)构建图谱, 无需 LLM 进行实体/关系提取。 关键设计: - 避免LLM幻觉:不依赖LLM识别实体 - 100%可追溯:每条边都有明确来源 - 高效构建:O(1)时间复杂度 """
3.2 图谱构建流程
State JSON(引擎输出) ↓解析为ParsedState对象 ↓提取报告标题、查询、段落信息 ↓添加Topic节点 ↓添加Engine节点 + Topic→Engine边(analyzed_by关系) ↓为每个Section添加节点 + Engine→Section边(contains关系) ↓解析SearchQuery记录 + Section→SearchQuery边(searched关系) ↓解析Source记录 + SearchQuery→Source边(found关系) ↓Forum日志(可选) ↓添加Host节点 + Host与其他节点的关系 ↓完整Graph对象
3.3 State JSON解析
def_add_engine_nodes(self, graph: Graph, topic_node: Node,engine_name: str, state: ParsedState):"""添加引擎相关节点"""# 1. 创建引擎节点engine_node=graph.add_node(node_type="engine",name=engine_name,node_id=engine_name,report_title=state.report_title, # 扩展属性original_query=state.query )# 2. 添加 Topic → Engine 边(analyzed_by关系)graph.add_edge(topic_node, engine_node, "analyzed_by")# 3. 处理段落forsectioninstate.sections:self._add_section_nodes(graph, engine_node, engine_name, section)
关键点:
-
Topic是根节点:所有分析都围绕用户查询展开
-
Engine是中间节点:连接Topic和Section
-
Section是叶子节点:承载具体的分析内容
3.4 Section与SearchQuery的处理
def_add_section_nodes(self, graph: Graph, engine_node: Node,engine_name: str, section: ParsedSection):"""添加段落相关节点"""# 创建段落节点section_id=f"{engine_name}_S{section.order}"section_node=graph.add_node(node_type="section",name=section.title,node_id=section_id,title=section.title, # 扩展属性 )# 添加 Engine → Section 边(contains关系)graph.add_edge(engine_node, section_node, "contains")
SearchQuery和Source的添加逻辑类似,都是通过解析State JSON中的嵌套结构来构建图谱。
四、图谱查询引擎:如何检索知识?
4.1 查询参数设计
# ReportEngine/graphrag/query_engine.py@dataclassclassQueryParams:"""查询参数"""keywords: List[str] =field(default_factory=list)node_types: Optional[List[str]] =None# 限定节点类型engine_filter: Optional[List[str]] =None# 限定引擎来源depth: int=1# 扩展深度max_sections: int=15# 结果数量限制max_queries: int=20max_sources: int=10
设计亮点:
| 参数 | 作用 | 使用场景 |
|---|---|---|
| keywords | 关键词匹配 | 用户问”情绪分析”相关内容 |
| node_types | 类型筛选 | 只看段落(section)或来源(source) |
| engine_filter | 引擎筛选 | 只看InsightEngine的分析 |
| depth | 深度扩展 | Topic → Engine → Section(depth=2) |
| max_sections | 数量限制 | 防止返回太多节点 |
4.2 多维度查询实现
# ReportEngine/graphrag/query_engine.pyclassQueryEngine:defquery(self, params: QueryParams) ->QueryResult:"""执行图谱查询"""matched_sections= []matched_queries= []matched_sources= []# 遍历图中的所有节点fornode_id, nodeinself.graph.nodes.items():# 1. 关键词匹配ifself._match_keywords(params.keywords, node):matched_sections.append(node.to_dict())# 2. 节点类型筛选ifparams.node_typesandnode.typenotinparams.node_types:continue# 3. 引擎来源筛选ifparams.engine_filterandnode.type=="engine"andnode.idnotinparams.engine_filter:continue# 4. 深度扩展# ...(实现略)
关键设计:
-
AND逻辑:所有条件都满足才加入结果
-
内存高效:只存储节点引用,不复制大对象
-
灵活扩展:支持未来添加更多筛选条件
4.3 深度扩展查询
BettaFish的查询引擎支持深度参数,这对于知识图谱非常重要:
深度=1:直接邻居Topic → Engine深度=2:两跳邻居Topic → Engine → Section深度=3:三跳邻居Topic → Engine → Section → 搜索关键词
为什么需要深度?
-
隐式关联:有些关系不是显式边,而是通过路径连接
-
上下文扩展:深度越大,上下文越丰富,但噪音也越大
五、图谱存储与持久化
5.1 JSON持久化
# ReportEngine/graphrag/graph_storage.pyclassGraph:def__init__(self):self.nodes: Dict[str, Node] = {}self.edges: List[Edge] = []defsave_to_json(self, file_path: str):"""保存图谱到JSON文件"""data= {'nodes': [node.to_dict() fornodeinself.nodes.values()],'edges': [edge.to_dict() foredgeinself.edges] }withopen(file_path, 'w', encoding='utf-8') asf:json.dump(data, f, ensure_ascii=False, indent=2)
存储格式示例:
{"nodes": [ {"id": "T_wuhan", "type": "topic", "name": "武汉大学舆情"}, {"id": "query", "type": "engine", "name": "Query Engine"}, {"id": "query_S1", "type": "section", "name": "舆情现状分析"} ],"edges": [ {"from": "T_wuhan", "to": "query", "relation": "analyzed_by"}, {"from": "query", "to": "query_S1", "relation": "contains"} ]}
为什么用JSON而非图数据库?
-
简单:无需引入Neo4j、ArangoDB等重型依赖
-
跨语言兼容:JSON是通用格式,前端任何语言都能解析
-
可移植性:图谱可以离线分享、分析
5.2 GraphStorage类设计
classGraphStorage:"""图谱存储管理器"""deffind_latest_graph(self) ->Optional[Path]:"""查找最新的图谱文件"""deffind_graph_by_report_id(self, report_id: str) ->Optional[Path]:"""根据报告ID查找图谱"""defload(self, file_path: Path) ->Optional[Graph]:"""加载图谱文件"""withopen(file_path, 'r', encoding='utf-8') asf:data=json.load(f)# 重建Graph对象graph=Graph()fornode_dataindata['nodes']:graph.add_node(Node.from_dict(node_data))foredge_dataindata['edges']:graph.add_edge(Edge.from_dict(edge_data))returngraph
六、GraphRAG在报告生成中的应用
6.1 图谱查询节点
在ReportEngine的节点流水线中,有一个专门的GraphRAGQueryNode:
# ReportEngine/nodes/chapter_generation_node.py (推测)classGraphRAGQueryNode:"""GraphRAG查询节点"""defexecute(self, state: State, **kwargs) ->Dict:"""执行图谱查询"""# 从配置或提示中获取查询参数keywords=state.current_chapter_context.get('graphrag_keywords', [])node_types=state.current_chapter_context.get('graphrag_node_types', ['section', 'source'])# 调用查询引擎query_engine=QueryEngine(self.graph)params=QueryParams(keywords=keywords,node_types=node_types,depth=2 )result=query_engine.query(params)# 将结果添加到章节上下文return {'graphrag_context': result.to_dict(),'matched_sections': len(result.matched_sections),'matched_queries': len(result.matched_queries) }
6.2 图谱数据的嵌入
查询到的图谱数据会被嵌入到LLM的提示词中:
# 在章节生成节点的Prompt构建中system_prompt=f"""你是报告生成专家。根据以下信息生成报告章节。【知识图谱上下文】{graphrag_context}根据以上上下文,生成"{chapter_title}"章节。"""user_prompt=f"""用户需求:{query}历史分析:- 已匹配{matched_sections}个相关段落- 已发现{matched_sources}个相关来源请生成结构化的JSON章节内容。"""
6.3 图谱查询的触发时机
动态触发:根据章节内容自动决定是否启用GraphRAG
# 章节点的自动判断ifself._requires_graphrag(chapter_title):# 章节涉及"对比分析"、"历史趋势" → 启用GraphRAGgraphrag_context=self._query_graph(chapter_keywords=['情绪', '趋势'])else:# 章节是"纯描述" → 跳过GraphRAGgraphrag_context=None
七、GraphRAG vs 传统RAG的对比总结
| 维度 | 传统RAG(向量检索) | BettaFish GraphRAG(结构化检索) |
|---|---|---|
| 数据结构 | 非结构化文档 | 结构化State + Forum日志 |
| 关系提取 | 语义隐式(embedding距离) | 显式明确(analyzed_by/contains) |
| 查询方式 | 向量语义匹配 | 图谱结构化查询(多条件) |
| 可解释性 | 低(黑盒匹配) | 高(可追踪推理路径) |
| 准确性 | 依赖embedding质量 | 100%准确(源自Agent原话) |
| 更新成本 | 高(需重新embedding) | 低(增量更新边) |
| 适用场景 | 通用文档问答 | 特定领域(舆情分析) |
八、总结:BettaFish GraphRAG的设计思想
8.1 核心设计原则
-
避免LLM幻觉:基于结构化数据构建,不依赖LLM识别实体
-
100%可追溯:每条边都有明确来源(State或Forum日志)
-
简单粗暴有效:不引入复杂的图数据库,Python对象即可
-
多维度查询:支持关键词、类型、引擎、深度等多条件组合
8.2 三大技术创新
-
关系显式化:analyzed_by、contains、searched、found四种关系类型
-
深度扩展查询:支持从Topic节点向外扩展N跳的路径查询
-
动态GraphRAG:根据章节内容自动决定是否启用图谱查询增强
8.3 适用场景
✅ 适合:
-
需要对比分析多个来源的场景
-
需要追踪Agent推理路径的场景
-
需要结构化回答”为什么得出这个结论”的场景
❌ 不适合:
-
纯知识问答(不需要关系推理)
-
需要处理海量节点的场景(GraphRAG性能有限)
下一章预告
在理解了GraphRAG的基础上,下一章我们将深入解析报告生成引擎:
-
模板选择→布局→篇幅→章节→渲染的完整流水线
-
IR中间表示的设计理念
-
章节JSON的校验机制
-
如何从知识图谱数据增强章节生成?
-
HTML/PDF多格式渲染的实现
关注公众号,不迷路 👉 BettaFish源码解析系列持续更新中…
